We are in a really early Alpha release. You should be ready for hard adventures. If you have updated to version 0.0.2 or greater - please re-download all pre-trained models
DeepPavlov is an open-source conversational AI library built on TensorFlow and Keras. It is designed for
- development of production ready chat-bots and complex conversational systems,
- NLP and dialog systems research.
Our goal is to enable AI-application developers and researchers with:
- set of pre-trained NLP models, pre-defined dialog system components (ML/DL/Rule-based) and pipeline templates;
- a framework for implementing and testing their own dialog models;
- tools for application integration with adjacent infrastructure (messengers, helpdesk software etc.);
- benchmarking environment for conversational models and uniform access to relevant datasets.
Demo of selected features is available at demo.ipavlov.ai

Agentis a conversational agent communicating with users in natural language (text).Skillfulfills user’s goal in some domain. Typically, this is accomplished by presenting information or completing transaction (e.g. answer question by FAQ, booking tickets etc.). However, for some tasks a success of interaction is defined as continuous engagement (e.g. chit-chat).Modelis a reusable functional component ofSkill.Rule-based Modelscannot be trained.Machine Learning Modelscan be trained only stand alone.Deep Learning Modelscan be trained independently and in an end-to-end mode being joined in a chain.
Skill Managerperforms selection of theSkillto generate response.Chainerbuilds an agent/component pipeline from heterogeneous components (rule-based/ml/dl). It allows to train and infer models in a pipeline as a whole.
The smallest building block of the library is Model. Model stands for any kind of function in an NLP pipeline. It can be implemented as a neural network, a non-neural ML model or a rule-based system. Besides that, Model can have nested structure, i.e. a Model can include other Model'(s).
Models can be joined into a Skill. Skill solves a larger NLP task compared to Model. However, in terms of implementation Skills are not different from Models. The only restriction of Skills is that their input and output should both be strings. Therefore, Skills are usually associated with dialogue tasks.
Agent is supposed to be a multi-purpose dialogue system that comprises several Skills and can switch between them. It can be a dialogue system that contains a goal-oriented and chatbot skills and chooses which one to use for generating the answer depending on user input.
DeepPavlov is built on top of machine learning frameworks TensorFlow and Keras. Other external libraries can be used to build basic components.
-
Currently we support only
Linuxplatform andPython 3.6(Python 3.5is not supported!) -
Create a virtual environment with
Python 3.6virtualenv env -
Activate the environment.
source ./env/bin/activate -
Clone the repo and
cdto project rootgit clone https://github.com/deepmipt/DeepPavlov.git cd DeepPavlov -
Install the requirements:
python setup.py develop -
Install
spacydependencies:python -m spacy download en
To use our pre-trained models, you should first download them:
python -m deeppavlov.deep download <path_to_config>
or you can use additional key -d to automatically download all required models and data with any command like interact, riseapi, etc.
Then you can interact with the models or train them with the following command:
python -m deeppavlov.deep <mode> <path_to_config> [-d]
<mode>can betrain,predict,interact,interactbotorriseapi<path_to_config>should be a path to an NLP pipeline json config (e.g.deeppavlov/configs/ner/slotfill_dstc2.json) or a name without the.jsonextension of one of the config files provided in this repository (e.g.slotfill_dstc2)
For the interactbot mode you should specify Telegram bot token in -t parameter or in TELEGRAM_TOKEN environment variable. Also if you want to get custom /start and /help Telegram messages for the running model you should:
- Add section to
utils/telegram_utils/model_info.jsonwith your custom Telegram messages - In model config file specify
metadata.labels.telegram_utilsparameter with name which refers to the added section ofutils/telegram_utils/model_info.json
For riseapi mode you should specify api settings (host, port, etc.) in utils/server_utils/server_config.json configuration file. If provided, values from model_defaults section override values for the same parameters from common_defaults section. Model names in model_defaults section should be similar to the class names of the models main component.
For predict you can specify path to input file with -f or --input-file parameter, otherwise, data will be taken
from stdin.
Every line of input text will be used as a pipeline input parameter, so one example will consist of as many lines,
as many input parameters your pipeline expects.
You can also specify batch size with -b or --batch-size parameter.
Available model configs are:
-
deeppavlov/configs/go_bot/*.json -
deeppavlov/configs/seq2seq_go_bot/*.json -
deeppavlov/configs/odqa/*.json -
deeppavlov/configs/squad/*.json -
deeppavlov/configs/intents/*.json -
deeppavlov/configs/ner/*.json -
deeppavlov/configs/ranking/*.json -
deeppavlov/configs/error_model/*.json
| Component | Description |
|---|---|
| Slot filling and NER components | Based on neural Named Entity Recognition network and fuzzy Levenshtein search to extract normalized slot values from text. The NER component reproduces architecture from the paper Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition which is inspired by Bi-LSTM+CRF architecture from https://arxiv.org/pdf/1603.01360.pdf. |
| Intent classification component | Based on shallow-and-wide Convolutional Neural Network architecture from Kim Y. Convolutional neural networks for sentence classification – 2014. The model allows multilabel classification of sentences. |
| Automatic spelling correction component | Based on An Improved Error Model for Noisy Channel Spelling Correction by Eric Brill and Robert C. Moore and uses statistics based error model, a static dictionary and an ARPA language model to correct spelling errors. |
| Ranking component | Based on LSTM-based deep learning models for non-factoid answer selection. The model performs ranking of responses or contexts from some database by their relevance for the given context. |
| Question Answering component | Based on R-NET: Machine Reading Comprehension with Self-matching Networks. The model solves the task of looking for an answer on a question in a given context (SQuAD task format). |
| Skills | |
| Goal-oriented bot | Based on Hybrid Code Networks (HCNs) architecture from Jason D. Williams, Kavosh Asadi, Geoffrey Zweig, Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning – 2017. It allows to predict responses in goal-oriented dialog. The model is customizable: embeddings, slot filler and intent classifier can switched on and off on demand. |
| Seq2seq goal-oriented bot | Dialogue agent predicts responses in a goal-oriented dialog and is able to handle multiple domains (pretrained bot allows calendar scheduling, weather information retrieval, and point-of-interest navigation). The model is end-to-end differentiable and does not need to explicitly model dialogue state or belief trackers. |
| ODQA | An open domain question answering skill. The skill accepts free-form questions about the world and outputs an answer based on its Wikipedia knowledge. |
| Embeddings | |
| Pre-trained embeddings for the Russian language | Word vectors for the Russian language trained on joint Russian Wikipedia and Lenta.ru corpora. |
View video demo of deployment of a goal-oriented bot and a slot-filling model with Telegram UI
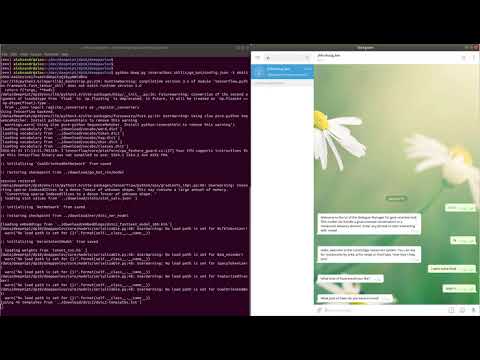
- Run goal-oriented bot with Telegram interface:
python -m deeppavlov.deep interactbot deeppavlov/configs/go_bot/gobot_dstc2.json -d -t <TELEGRAM_TOKEN>
- Run goal-oriented bot with console interface:
python -m deeppavlov.deep interact deeppavlov/configs/go_bot/gobot_dstc2.json -d
- Run goal-oriented bot with REST API:
python -m deeppavlov.deep riseapi deeppavlov/configs/go_bot/gobot_dstc2.json -d
- Run slot-filling model with Telegram interface:
python -m deeppavlov.deep interactbot deeppavlov/configs/ner/slotfill_dstc2.json -d -t <TELEGRAM_TOKEN>
- Run slot-filling model with console interface:
python -m deeppavlov.deep interact deeppavlov/configs/ner/slotfill_dstc2.json -d
- Run slot-filling model with REST API:
python -m deeppavlov.deep riseapi deeppavlov/configs/ner/slotfill_dstc2.json -d
- Predict intents on every line in a file:
python -m deeppavlov.deep predict deeppavlov/configs/intents/intents_snips.json -d --batch-size 15 < /data/in.txt > /data/out.txt
| deeppavlov.core.commands | basic training and inference functions |
| deeppavlov.core.common | registration and classes initialization functionality, class method decorators |
| deeppavlov.core.data | basic DatasetIterator, DatasetReader and Vocab classes |
| deeppavlov.core.layers | collection of commonly used Layers for TF models |
| deeppavlov.core.models | abstract model classes and interfaces |
| deeppavlov.dataset_readers | concrete DatasetReader classes |
| deeppavlov.dataset_iterators | concrete DatasetIterators classes |
| deeppavlov.metrics | different Metric functions |
| deeppavlov.models | concrete Model classes |
| deeppavlov.skills | Skill classes. Skills are dialog models. |
| deeppavlov.vocabs | concrete Vocab classes |
An NLP pipeline config is a JSON file that contains one required element chainer:
{
"chainer": {
"in": ["x"],
"in_y": ["y"],
"pipe": [
...
],
"out": ["y_predicted"]
}
}
Chainer is a core concept of DeepPavlov library: chainer builds a pipeline from heterogeneous components
(rule-based/ml/dl) and allows to train or infer from pipeline as a whole. Each component in the pipeline specifies
its inputs and outputs as arrays of names, for example: "in": ["tokens", "features"] and "out": ["token_embeddings", "features_embeddings"] and you can chain outputs of one components with inputs of other components:
{
"class": "deeppavlov.models.preproccessors.str_lower:StrLower",
"in": ["x"],
"out": ["x_lower"]
},
{
"name": "nltk_tokenizer",
"in": ["x_lower"],
"out": ["x_tokens"]
},Each Component in the pipeline must implement method __call__ and has name parameter, which is its registered codename,
or class parameter in the form of module_name:ClassName.
It can also have any other parameters which repeat its __init__() method arguments.
Default values of __init__() arguments will be overridden with the config values during the initialization of a class instance.
You can reuse components in the pipeline to process different parts of data with the help of id and ref parameters:
{
"name": "nltk_tokenizer",
"id": "tokenizer",
"in": ["x_lower"],
"out": ["x_tokens"]
},
{
"ref": "tokenizer",
"in": ["y"],
"out": ["y_tokens"]
},There are two abstract classes for trainable components: Estimator and NNModel.
Estimators are fit once on any data with no batching or early stopping,
so it can be safely done at the time of pipeline initialization. fit method has to be implemented for each Estimator. An example of Estimator is Vocab.
NNModel requires more complex training. It can only be trained in a supervised mode (as opposed to Estimator which can be trained in both supervised and unsupervised settings). This process takes multiple epochs with periodic validation and logging.
train_on_batch method has to be implemented for each NNModel.
Training is triggered by deeppavlov.core.commands.train.train_model_from_config() function.
Estimators that are trained should also have fit_on parameter which contains a list of input parameter names.
An NNModel should have the in_y parameter which contains a list of ground truth answer names. For example:
[
{
"id": "classes_vocab",
"name": "default_vocab",
"fit_on": ["y"],
"level": "token",
"save_path": "vocabs/classes.dict",
"load_path": "vocabs/classes.dict"
},
{
"in": ["x"],
"in_y": ["y"],
"out": ["y_predicted"],
"name": "intent_model",
"save_path": "intents/intent_cnn",
"load_path": "intents/intent_cnn",
"classes_vocab": {
"ref": "classes_vocab"
}
}
]The config for training the pipeline should have three additional elements: dataset_reader, dataset_iterator and train:
{
"dataset_reader": {
"name": ...,
...
}
"dataset_iterator": {
"name": ...,
...
},
"chainer": {
...
}
"train": {
...
}
}
Simplified version of trainig pipeline contains two elemens: dataset and train. The dataset element currently
can be used for train from classification data in csv and json formats. You can find complete examples of how to use simplified training pipeline in intents_sample_csv.json and intents_sample_json.json config files.
epochs— maximum number of epochs to train NNModel, defaults to-1(infinite)batch_size,metrics— list of names of registered metrics to evaluate the model. The first metric in the list is used for early stoppingmetric_optimization—maximizeorminimizea metric, defaults tomaximizevalidation_patience— how many times in a row the validation metric has to not improve for early stopping, defaults to5val_every_n_epochs— how often to validate the pipe, defaults to-1(never)log_every_n_batches,log_every_n_epochs— how often to calculate metrics for train data, defaults to-1(never)validate_best,test_bestflags to infer the best saved model on valid and test data, defaults totrue
DatasetReader class reads data and returns it in a specified format.
A concrete DatasetReader class should be inherited from the base
deeppavlov.data.dataset_reader.DatasetReader class and registered with a codename:
from deeppavlov.core.common.registry import register
from deeppavlov.core.data.dataset_reader import DatasetReader
@register('dstc2_datasetreader')
class DSTC2DatasetReader(DatasetReader):DatasetIterator forms the sets of data ('train', 'valid', 'test') needed for training/inference and divides it into batches.
A concrete DatasetIterator class should be registered and can be inherited from
deeppavlov.data.dataset_iterator.BasicDatasetIterator class. deeppavlov.data.dataset_iterator.BasicDatasetIterator
is not an abstract class and can be used as a DatasetIterator as well.
All components inherited from deeppavlov.core.models.component.Component abstract class can be used for inference. The __call__() method should return standard output of a component. For example, a tokenizer should return
tokens, a NER recognizer should return recognized entities, a bot should return an utterance.
A particular format of returned data should be defined in __call__().
Inference is triggered by deeppavlov.core.commands.infer.interact_model() function. There is no need in a separate JSON for inference.
Each library component or skill can be easily made available for inference as a REST web service. The general method is:
python -m deeppavlov.deep riseapi <config_path> [-d]
(optional -d key is for dependencies download before service start)
Web service properties (host, port, model endpoint, GET request arguments) are provided in utils/server_utils/server_config.json.
Properties from common_defaults section are used by default unless they are overridden by component-specific properties, provided in model_defaults section of the server_config.json.
Component-specific properties are bound to the component by server_utils label in metadata/labels section of the component config. Value of server_utils label from component config should match with properties key from model_defaults section of server_config.json.
For example, metadata/labels/server_utils tag from go_bot/gobot_dstc2.json references to the GoalOrientedBot section of server_config.json. Therefore, model_endpoint parameter in common_defaults will be will be overridden with the same parameter from model_defaults/GoalOrientedBot.
Model argument names are provided as list in model_args_names parameter, where arguments order corresponds to component API.
When inferencing model via REST api, JSON payload keys should match component arguments names from model_args_names.
Default argument name for one argument components is "context".
Here are POST requests examples for some of the library components:
| Component | POST request JSON payload example |
|---|---|
| One argument components | |
| NER component | {"context":"Elon Musk launched his cherry Tesla roadster to the Mars orbit"} |
| Intent classification component | {"context":"I would like to go to a restaurant with Asian cuisine this evening"} |
| Automatic spelling correction component | {"context":"errror"} |
| Ranking component | {"context":"What is the average cost of life insurance services?"} |
| (Seq2seq) Goal-oriented bot | {"context":"Hello, can you help me to find and book a restaurant this evening?"} |
| Two arguments components | |
| Question Answering component | {"context":"After 1765, growing philosophical and political differences strained the relationship between Great Britain and its colonies.", "question":"What strained the relationship between Great Britain and its colonies?"} |
Flasgger UI for API testing is provided on <host>:<port>/apidocs when running a component in riseapi mode.
DeepPavlov is Apache 2.0 - licensed.
If you have any questions, bug reports or feature requests, please feel free to post on our Github Issues page. Please tag your issue with bug, feature request, or question. Also we’ll be glad to see your pull requests to add new datasets, models, embeddings, etc.
DeepPavlov is built and maintained by Neural Networks and Deep Learning Lab at MIPT within iPavlov project (part of National Technology Initiative) and in partnership with Sberbank.
