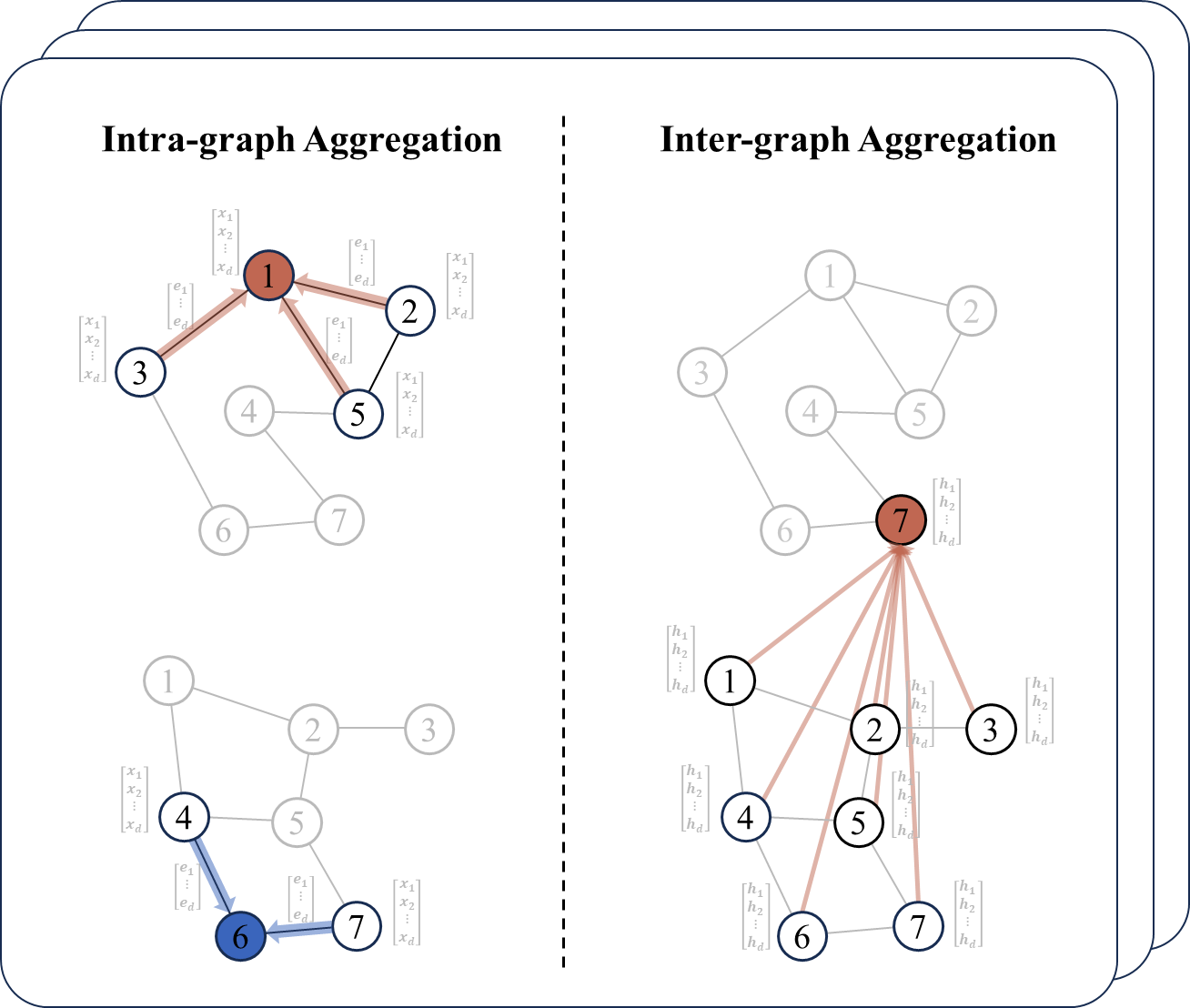
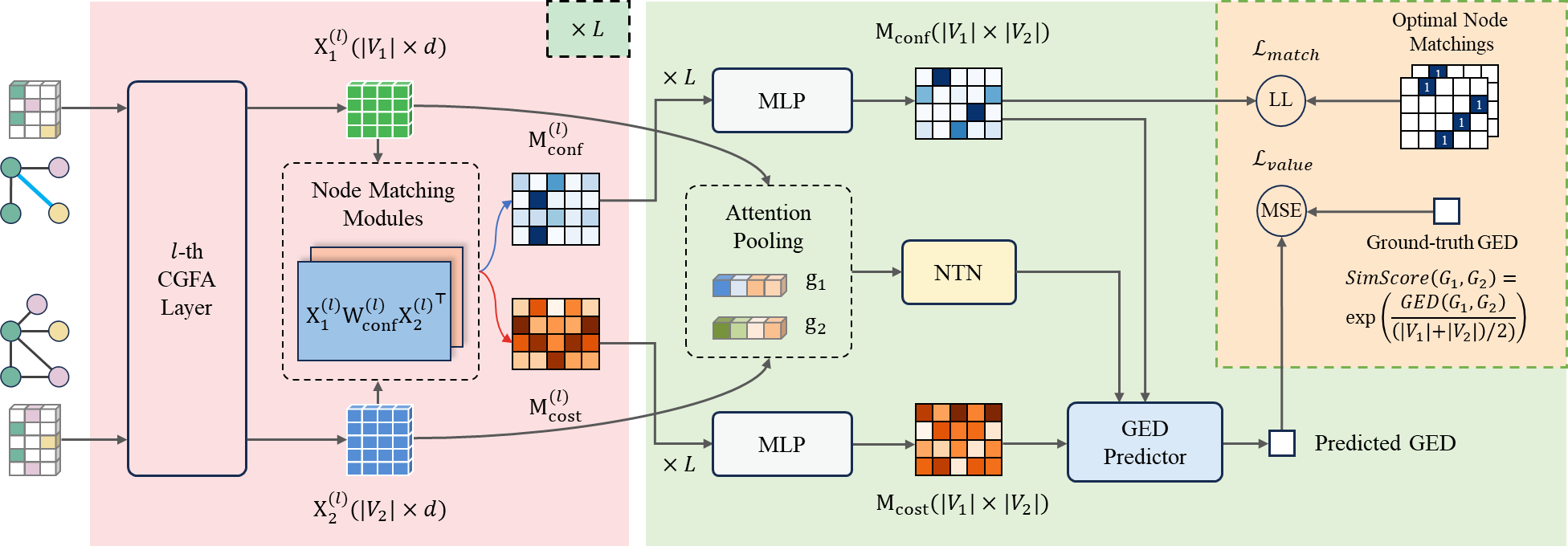
Graph Edit Distance (GED) is a classical graph similarity metric. Since exact GED computation is NP-hard, existing GNN-based methods try to approximate GED in polynomial time. However, they still lack support for edge labels or the ability to generate an edit path. To address these limitations, we propose a hybrid method named CGEDN based on Graph Neural Networks and learnable node matching. Specifically, CGEDN starts with cross-graph feature aggregation layers, which generate node embeddings with fine-grained interaction features and support edge labels as well. Next, two node matching pipelines are applied to obtain a node matching confidence matrix and a cost matrix, where the confidence matrix is supervised by optimal node matchings corresponding to GED. Finally, we calculate the weighted sum of the cost matrix with a bias value to regress GED only, or search for the top-k most promising node matchings based on confidence matrix to approximate GED and recover an edit path simultaneously. The experimental results on real and synthetic graphs demonstrate that CGEDN significantly outperforms the best result of existing approximate methods.
├── config # specify hyper-parameters here
│ ├── CGEDN
│ │ ├── CGEDN-AIDS_700-real_real.ini
│ │ ├── CGEDN-AIDS_small-real_real.ini
│ │ ├── CGEDN-Linux-real_real.ini
│ │ ├── CGEDN-IMDB_small-real_real.ini
│ │ ├── CGEDN-IMDB_large-syn_syn.ini
│ │ └── CGEDN-AIDS_large-syn_syn.ini
│ ├── GEDGNN
│ ├── SimGNN
│ └── TaGsim
│
├── data # put dataset here, following the example directory structure
│ ├── AIDS_700
│ │ ├── json
│ │ ├── properties.json
│ │ ├── test_gt.json
│ │ └── train_gt.json
│ ├── AIDS_large
│ ├── AIDS_small
│ ├── IMDB_large
│ ├── IMDB_small
│ └── Linux
│
├── experiments
│ ├── ablation
│ └── compare
│ ├── algorithms # Implementation of traditional algorithms (A*-beam)
│ ├── algorithms_result
│ ├── model # Implementation of CGEDN, GEDGNN, TaGSim and SimGNN
│ ├── model_save
│ └── main.py
│
├── tests
└── utilsnetworkx 3.1
numpy 1.24.3
pytorch 2.4.1
torch-cluster 1.6.3+pt24cpu
torch-geometric 2.6.1
torch-scatter 2.1.2+pt24cpu
torch-sparse 0.6.18+pt24cpu
tqdm 4.65.0
texttable 1.6.4
dgl 0.9.0
scipy 1.10.1
matplotlib 3.7.2
└── data # put dataset here, following the example directory structure
├── AIDS_700
│ ├── json
│ │ ├── test
│ │ │ ├── query
│ │ │ └── target
│ │ └── train
│ ├── properties.json
│ ├── test_gt.json
│ └── train_gt.json
├── AIDS_large
├── AIDS_small
├── IMDB_large
├── IMDB_small
└── Linux Data for models training is placed in data directory. All the files required by our codes can be downloaded here.
Each dataset has 1 subfolder and 3 files. Subfolder /data/json can be divided into /data/json/test and /data/json/train, which contain graphs for testing and training. We use json files to represent graphs, for example, 4.json in AIDS_small is a node/edge labelled graph:
// 4.json
{"n":10,"m":9,"nodes":["C","C","S","S","O","O","O","O","O","O"],"edges":[[0,1],[0,2],[1,3],[2,4],[2,5],[2,6],[3,7],[3,8],[3,9]],"edge_labels":["1","1","1","2","2","1","2","2","1"]}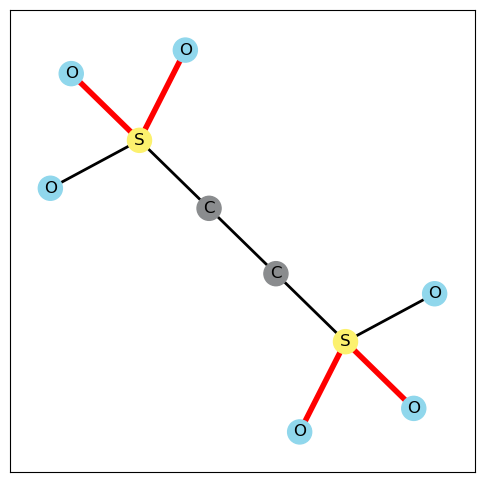
The properties.json file contains some metadata of the dataset, such as node labels set, edge labels set, maximum number of nodes, etc.
{
"node_label_map": {"As": 0, "B": 1, "Bi": 2, "Br": 3, "C": 4, "Cl": 5, "Co": 6, "Cu": 7, "F": 8, "Ga": 9, "Hg": 10, "Ho": 11, "I": 12, "Li": 13, "N": 14, "Ni": 15, "O": 16, "P": 17, "Pb": 18, "Pd": 19, "Pt": 20, "Ru": 21, "S": 22, "Sb": 23, "Se": 24, "Si": 25, "Sn": 26, "Tb": 27, "Te": 28},
"edge_label_map": null,
"nodeDim": 8,
"edgeDim": 1,
"maxNodes": 10
}The test_gt.json and train_gt.json contain ground-truth of graph pairs for model training/testing, each item can be represented by [gid1, gid2, GED, NR, NID, ER, EID, [optimal node matchings...]]
[4,6,12,5,0,0,7,[[3,5,0,9,1,6,2,4,7,8],[3,5,0,9,6,1,2,4,7,8],[3,5,0,9,1,6,2,7,4,8],...]]
SimGNN use only GED to train.
TaGSim use NR, NID, ER, EID to train(GED=NR+NID+ER+EID).
CGEDN and GEDGNN use GED and [optimal node matchings] to train.
Soecify hyper-parameters of models by defining a .ini file under /config,for example:
[Model]
model_name=CGEDN
gnn_filters=64-64-64
tensor_neurons=64
[Dataset]
dataset=AIDS_small
training_set=real
testing_set=real
[Training]
lamb=0.01All settings and default values for the model hyper-parameters can be found in /utils/parameter_parser.py.
Train and test the models by runing /experiments/compare/main.py. We provide functions for training each model on all datasets, which you can call according to your needs.
def CGEDN_train():
# Provide the path to the hyperparameter configuration file to start train and test
configs = [
"../../config/CGEDN/CGEDN-AIDS_700-real_real.ini",
# "../../config/CGEDN/CGEDN-IMDB_large-syn_syn.ini",
# "../../config/CGEDN/CGEDN-IMDB_small-real_real.ini",
# "../../config/CGEDN/CGEDN-AIDS_large-syn_syn.ini",
# "../../config/CGEDN/CGEDN-AIDS_small-real_real.ini",
# "../../config/CGEDN/CGEDN-Linux-real_real.ini",
]
for cfg in configs:
parser = get_parser()
args = parser.parse_args()
args.__setattr__("config", cfg)
config = parse_config_file(args.config)
update_args_with_config(args, config)
tab_printer(args)
trainer = Trainer(args)
if args.epoch_start > 0:
trainer.load(args.epoch_start)
for epoch in range(args.epoch_start, args.epoch_end):
trainer.fit()
trainer.save(epoch + 1)
trainer.score()
if __name__ == "__main__":
CGEDN_train()