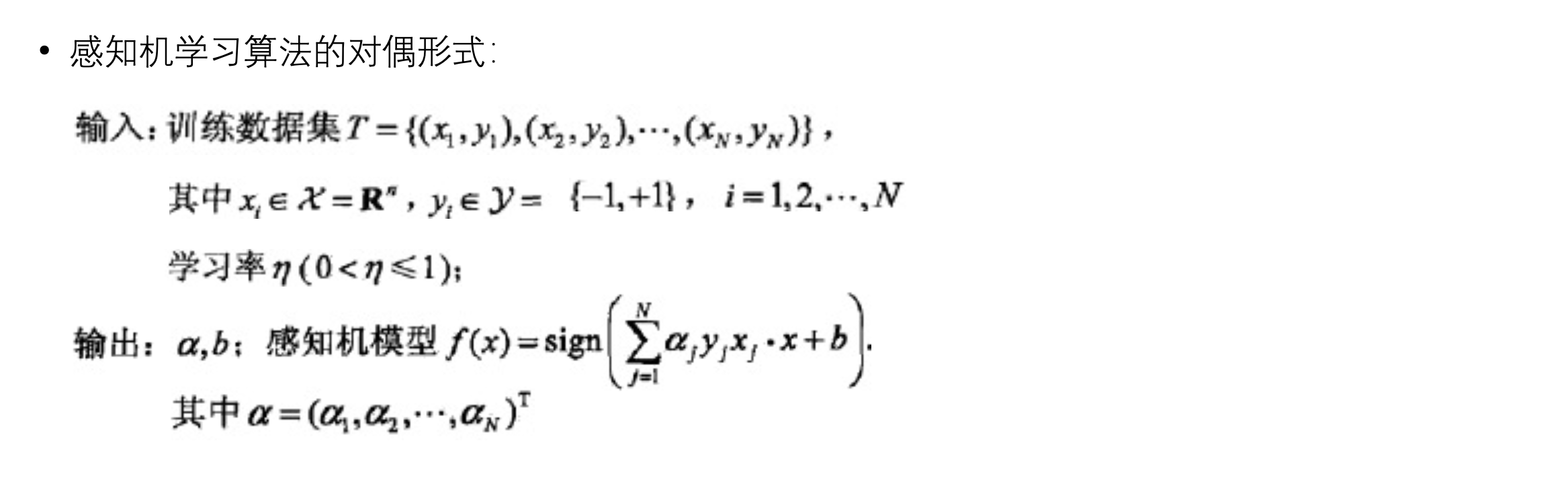机器学习:
机器学习是近20多年兴起的一门多领域交叉学科,涉及概率论、统计学、逼近论、凸 分析、算法复杂度理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以 自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对 未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与统计推断学联系尤为密切,也被称为统计学习理论。
人工智能/机器学习/深度学习

深度学习和人工智能其它方法

机器学习与数据挖掘

计算机视觉是机器学习最重要的应用
机器学习和统计学习
- Simon Blomberg:
- From R’s fortunes package: To paraphrase provocatively, ‘machine learning is statistics minus any checking of models and assumptions
- Andrew Gelman:
- In that case, maybe we should get rid of checking of models and assumptions more often. Then maybe we’d be able to solve some of the problems that the machine learning people can solve but we can’t
大数据机器学习的主要特征
- 与日俱增的数据量
- 实验数据量的增加
- 与日俱增的神经网络模型规模
- 与日俱增的精度、复杂度和对现实世界的冲击
- GPU (Graphic Processing Unit)
- TPU Tensor Processing Unit
- 深度学习框架
- TensorFlow Pytorch Caffe CNTK Keras MXNet Theano Scikit-learning Spark MLlib
基本术语
-
Data set
- 形状=圆形 剥皮=难 味道=酸甜
- 形状=扁圆形 剥皮=易 味道=酸
- 形状=长圆形 剥皮=难 味道=甜
-
Instance/sample
-
Attribute value/feature
-
Attribute/feature space
-
Feature vector
-
$D={x_1,x_2,......x_m}$ m个示例的数据集 -
是$d$维样本空间X的一个特征向量
-
training/learning
-
training data
-
training sample
-
Label ((形状=长圆形 剥皮=难 味道=甜), 橙子)
-
example
机器学习的任务
- Classification, discrete
- Regression, continuous
- Binary classification, 2-related
- Multi-class classification
- Clustering
- Multi-labeling annotation
监督学习
- 监督学习目的是学习一个由输入到输出的映射,称为模型
- 模型的集合就是假设空间(hypothesis space)
- 模型:
- 概率模型:条件概率分布$P(Y|X)$
- 非概率模型:决策函数$Y=f(X)$
- 联合概率分布:假设输入与输出的随机变量X和Y遵循联合概率 分布P(X,Y)
问题的形式化

假设空间 hypothesis space
- 学习过程: 搜索所有假设空间,与训练集匹配
- 形状=圆形 剥皮=难 味道=酸甜 橙
- 形状=扁圆形 剥皮=易 味道=酸 橘
- 形状=长圆形 剥皮=难 味道=甜 橙
- 假设形状,剥皮,味道 分别有3,2,3 种可能取值,加上取任意值*和空集, 假设空间规模$4x3x4+1=49$
- Version space: 与训练集一致的假设集合
- 形状=剥皮=难味道= 橙
- 形状=扁圆形 剥皮=易 味道=* 橘
学习三要素, 方法=模型+策略+算法
模型
- 当假设空间F为决策函数的集合:
$F={f | Y=f(x) }$ - F实质为参数向量决定的函数族:
$F={f | Y=f_{\theta}(x), \theta\in R^{n} }$ - 当假设空间F为条件概率的集合:
$F={ P| P(X|Y)}$ - F实质是参数向量决定的条件概率分布族:
$F={ P|P_{\theta}(Y|X), \theta\in R^{n}}$
策略
损失函数和风险函数
- 0-1 loss function, $L(Y, f(x))=\begin{cases} 1, & Y\neq f(X) \ 2, & Y=f(X) \ \end{cases}$
- Quadratic loss function,
$L(Y, f(X))=(Y-f(X))^{2}$ - Absolute loss function,
$L(Y, f(X))=|Y-f(X)|$ - Logarithmic loss function/loglikelihood loss function,
$L(Y, P(Y|X))=-\log P(Y|X)$
损失函数的期望,风险函数risk function,期望损失expected loss
$R_{exp}(f)=E_{p}[L(Y, f(X))]=\int_{x\times y}L(y, f(x))P(x, y)dxdy$
经验风险empiracal risk, 经验损失empiracal loss
$T={(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)}$ $R_{emp}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_i, f(x_i))$
因为风险函数很难求,一般使得经验风险最小化与结构风险最小化
- 经验风险最小化模型,
$\min_{f\in F}\frac{1}{N}\sum_{i=1}^{N}L(y_{i}, f(x_{i}))$ - 当样本容量很小时,经验风险最小化学习的效果未必很好,会产生"过拟合over- fitting"
- 为防止过拟合提出的策略,结构风险最小化 structure risk minimization,等价 于正则化(regularization),加入正则化项regularizer,或罚项 penalty term
$R_{emp}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_i, f(x_i)) + \lambda J(f)$
方法
求最优模型就是求解最优化问题:
$\min_{f\in F}\frac{1}{N}\sum_{i=1}^{N}L(y_i, f(x_i)) + \lambda J(f)$ - 难点
- 全剧最优
- 高校
奥卡姆剃刀原理 Occam’s razor
“如无必要,勿增实体”

No free lunch theorem


训练误差和测试误差
训练误差, 训练数据集的平均损失:
测试误差, 测试训练集的平均损失:
损失函数是0-1损失时:
测试数据集的准确率:
过拟合
- 过拟合与模型选择-多项式曲线拟合的例子
- 假设给定训练数据集




解决方法:
- 增大训练样本集
- 正则化

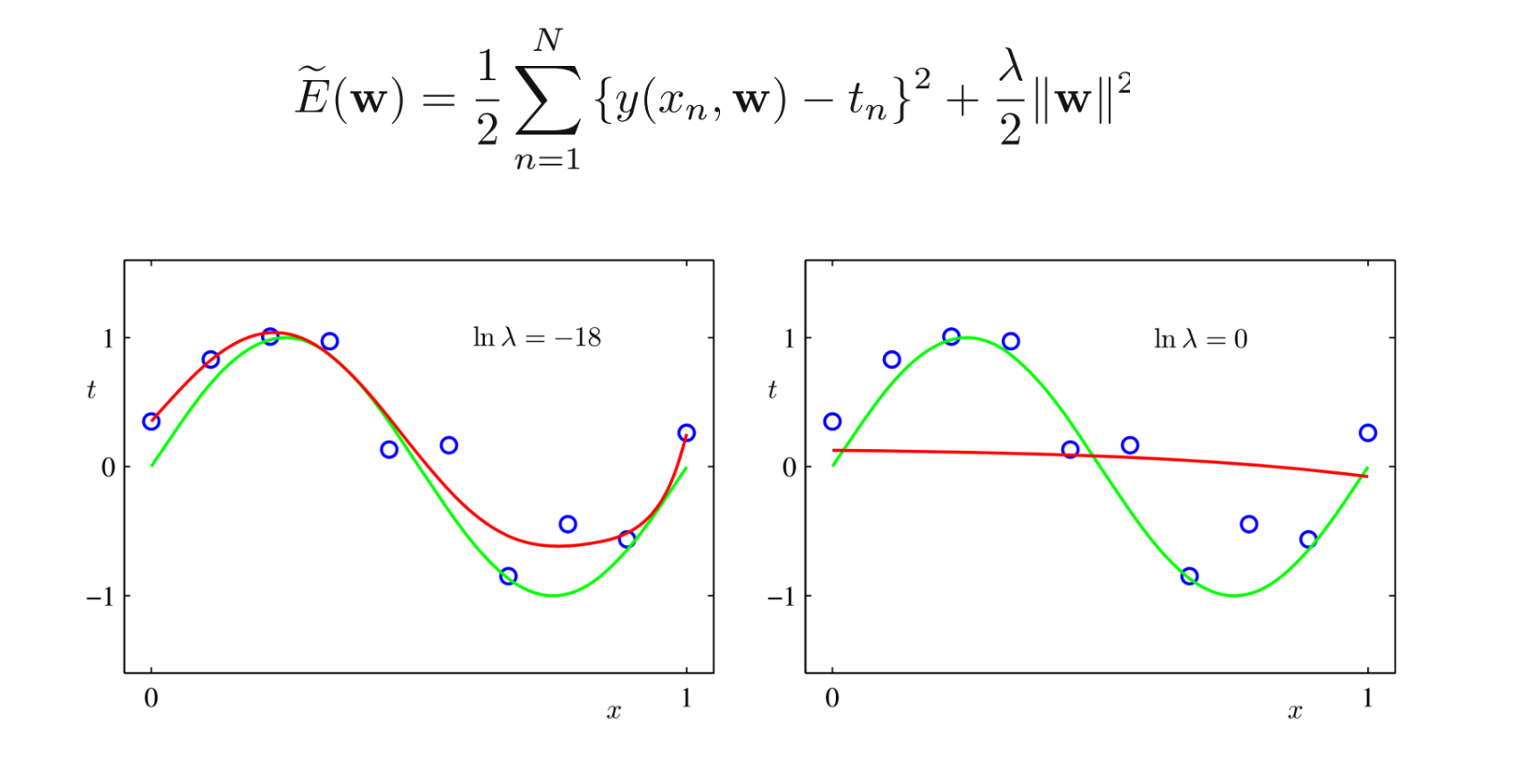
-
$\lambda$ 抑制模型复杂化



泛化能力 generalization ability


生成模型与判别模型
- 监督学习的目的就是学习一个模型:
- 决策函数:
$Y=f(X)$ - 条件概率分布:
$P(Y|X)$ - 生成方法Generative approach 对应生成模型: generative model,
- 朴素贝叶斯法和隐马尔科夫模型
- 判别方法discriminative approach 对应判别模型: discriminative model
- K近邻,感知机,决策树,logistic 回归等
- 生成方法Generative approach 对应生成模型: generative model,

模型评估方法
- 泛化误差评估:
- 训练集 training set: 用于训练模型
- 验证集 validation set: 用于模型选择
- 测试集 test set: 用于模型泛化误差的近似
- 训练集和测试集的产生
- 留出法
- 交叉验证法
- 自助法
留出法 Hold-out
训练集S, 测试集T, D为数据集
- 注意点:
- 训练/测试集的划分尽可能保持数据分布的一致性,避免引入额外偏差
- 存在多种划分方式对初始数据集进行分割,采用若干次随机划分,重复实验
- 存在问题:
- S大,T小; S小,T大,都会带来负面影响
交叉验证法 cross validation
-
$D \rightarrow k$ 个大小相等的互斥子集 -
$D=D_{1}\cup D_{2}\cup ...\cup D_{k}$ ,$D_{i}\cap D_{j}=\oslash (i\neq j)$ -
$K-1$ 个子集并集为训练集,$1$个测试集 

自助法 boostrapping
- 自助采样法:
$\lim_{m\rightarrow \infty}(1-\frac{1}{m})^{m}\to\frac{1}{e}\approx0.368$
- 测试集:
$D \backslash D’$ ,$\backslash$ 为集合减法 - 优点
- 适用于数据集较小,难以划分;
- 从数据集产生不同的训练集,适用于集成学习方法;
- 缺点
- 产生的训练集改变了初始数据集的分布,会引入估计偏差。
性能度量
-
不同任务,性能度量不同
- 回归任务 - 均方误差:
$E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_{i}-y_{i}))^{2}$
- 更一般:
$E(f;D)=\int_{x\sim D}(f(x_{i}-y_{i}))^{2}p(x)dx$
- 回归任务 - 均方误差:
-
错误率和精度 - 分类任务
- 错误率
-
$E(f;D)=\frac{1}{m}\sum_{i=1}^{m} \mathbb I (f(x_{i}\neq y_{i}))$ ,$\mathbb I$ is the indicator function
-
- 精度
$acc(f;D)=\frac{1}{m}\sum_{i=1}^{m}\mathbb I (f(x_{i}=y_{i}))=1-E(f;D)$
- 更一般:
$E(f;D)=\int_{x\sim D}\mathbb I (f(x)\neq y)p(x)dx$ $acc(f;D)=\int_{x\sim D}\mathbb I (f(x)= y)p(x)dx=1-E(f;D)$
- 错误率
-
查准率precision 、 查全率recall与F1
-
P-R曲线
-
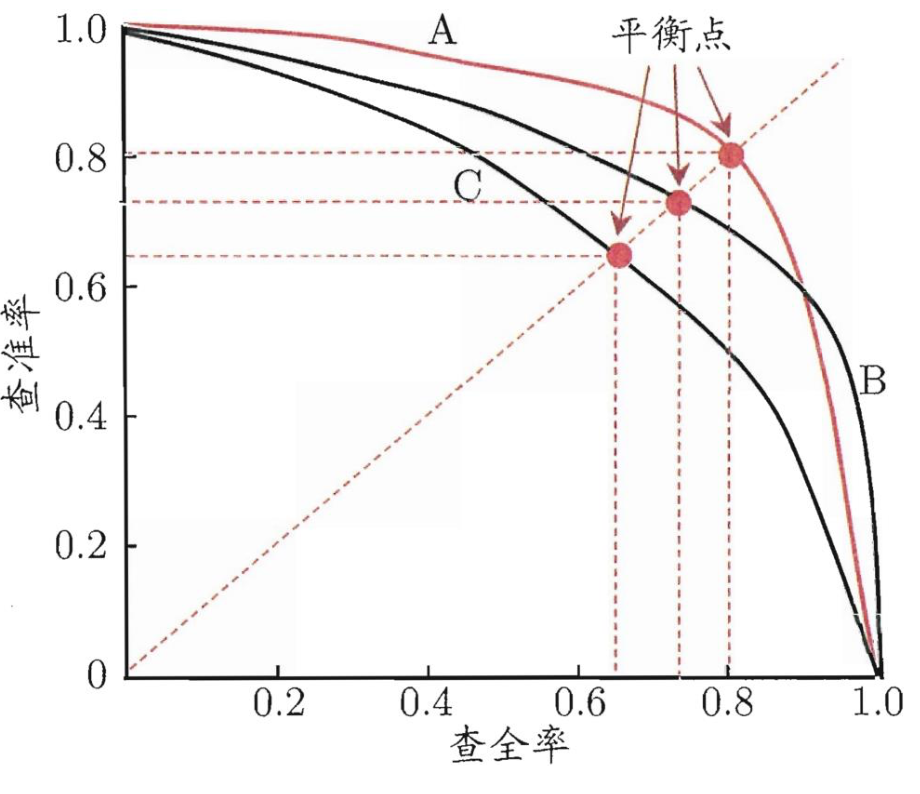
-
平衡点BEP
- 查准率$=$查全率
-
$F1$ 度量$F1=\frac{2\times P\times R}{p+R}=\frac{2\times TP}{样例总数+TP-TN}$
-
$F_{\beta}$ 度量$F_{\beta}=\frac{(1+\beta^{2})\times P\times R}{(\beta^2\times P) + R}$
-

-
ROC (Receiver Operating Characteristic), AUC(Area Under ROC Curve)
- 纵轴:“真正例率 ” (True Positive Rate, 简称 TPR)
- 横轴:“假正例率” (False Positive Rate, 简称 FPR)
-
$TPR=\frac{TP}{TP+FN}$ ,$FPR=\frac{FP}{TN+FP}$ 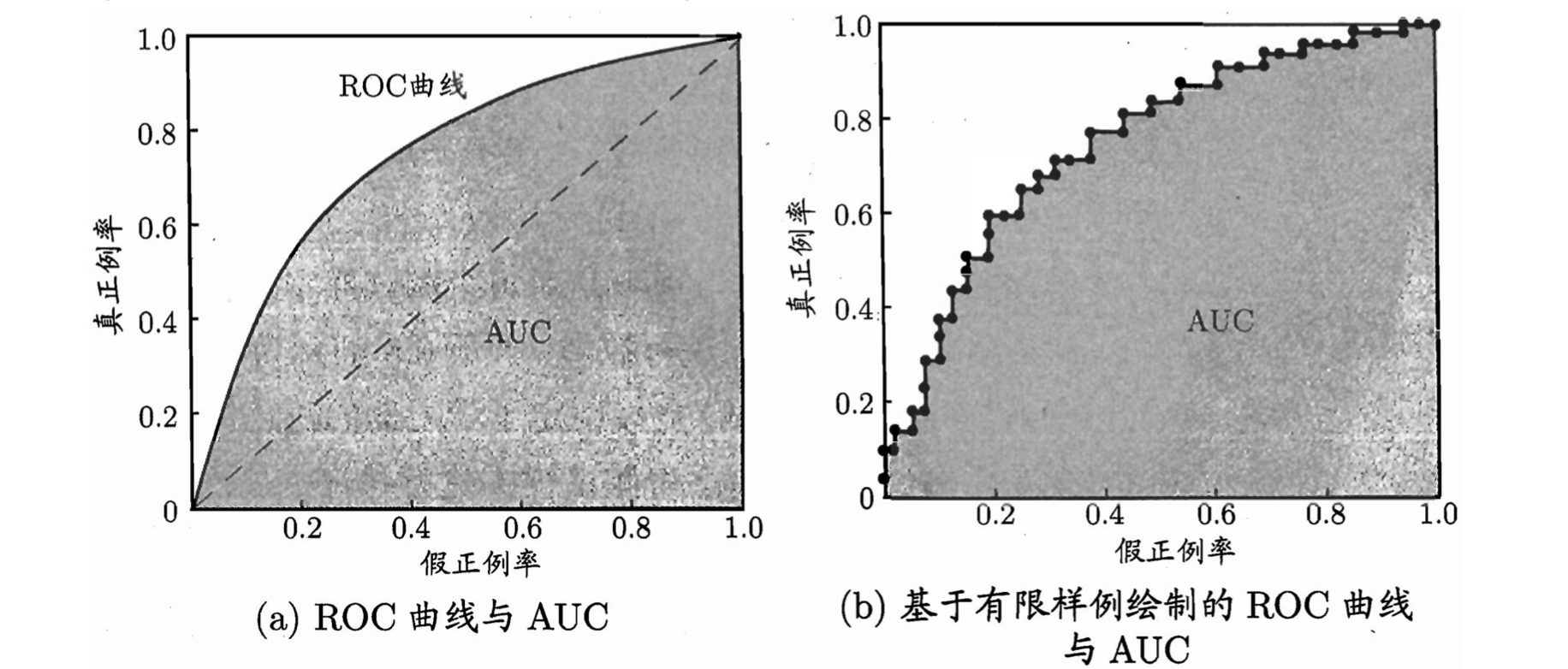
-
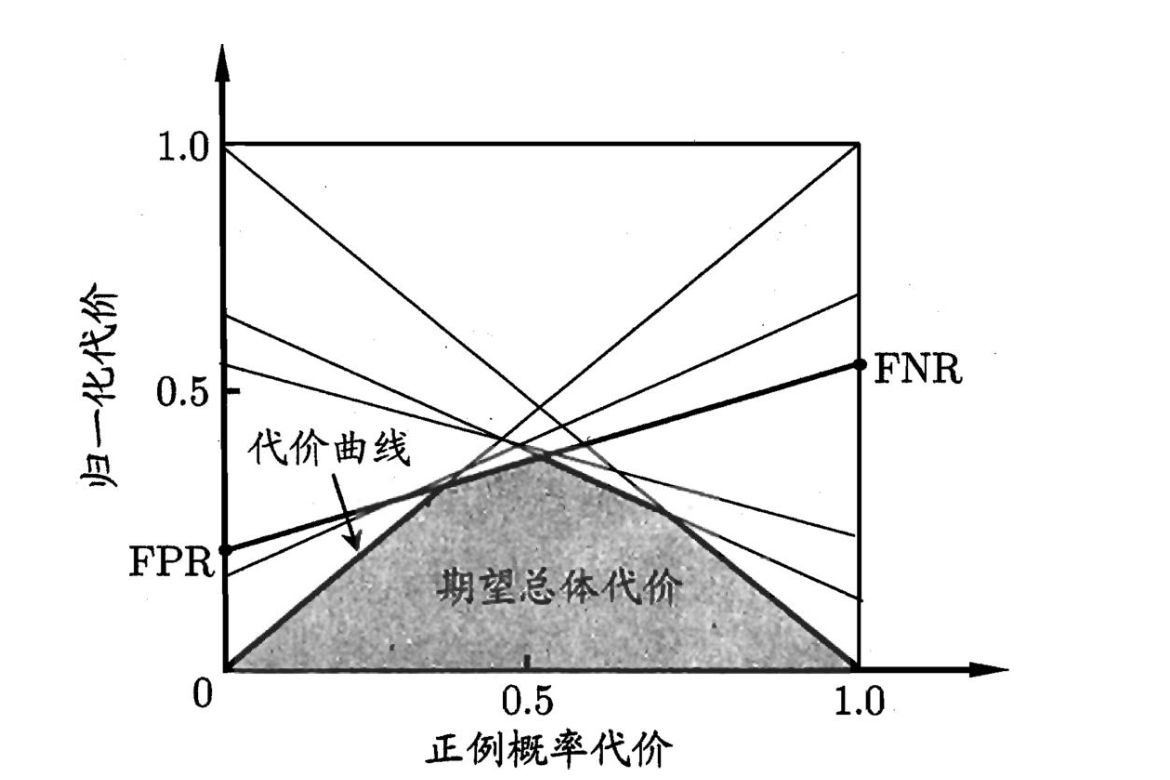
代价敏感错误率与代价曲线
- 应用背景: 不同类型的错误所造成的后果不同
- 二分类任务:代价矩阵(cost matrix)
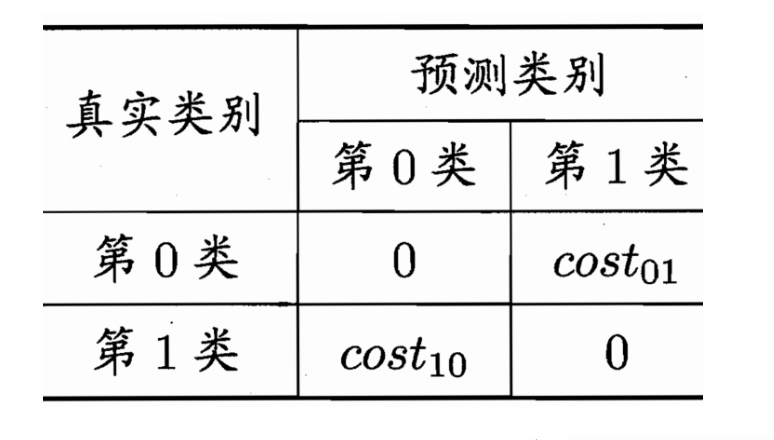
- 对应代价敏感错误率
$E(f;D;cost)=\frac{1}{m}(\sum_{x_{i}\in D^{+}}\mathbb I(f(x_{i})\neq y_{i})\times cost_{01} + \sum_{x_{i}\in D^{-}} \mathbb I f(x_{i})\neq y_{i}\times cost_{10})$ 
-
比较检验
- 问题提出: 能否直接用上述评估方法获得的性能度量"比大小"?
- 答案:不能
- 原因:
- 希望比较泛化性能,实验评估的是测试集性能;
- 测试集性能和测试集的选择有关,测试样例不同,结果不同;
- 机器学习算法本身有一定的随机性,相同的参数,相同的数据集, 结果也会不同。
- 方案: 统计假设检验(hypothesis test)
- 在测试集上观察到学习器A比B好, 则 A 的泛化性能是否在统计意义上优于 B, 以及这个结论的把握有多大
- 问题提出: 能否直接用上述评估方法获得的性能度量"比大小"?
-
假设检验
- 对单个学习器泛化性能的假设进行检验
- "二项检验" (binomial test)
-
$t$ 检验 (t-test)
- 对不同学习器的性能进行比较
- "成对$t$ 检验" (paired t-tests)
- 对单个学习器泛化性能的假设进行检验
-
二项检验
- 假设检验: "假设"是对学习器泛化错误率分布的某种判别或猜想,如$\epsilon$
- 现实任务中我们只能获知测试错误率$\hat{\epsilon}$
- 那么: 泛化错误率为$\epsilon$的学习器将其中$m'$个样本误分类的概率:
- $P(\hat{\epsilon};\epsilon)=\begin{pmatrix} m \ \hat{\epsilon}\times m \end{pmatrix}\epsilon^{\hat{\epsilon}\times m}(1-\epsilon)^{m-\hat{\epsilon}\times m}$
- 使用二项检验对泛化误差$\epsilon \leq 0.3$的假设进行检验
-
$1-\alpha$ 的概率内所能观测到的最大错误率:$\overline{\epsilon}=\max\in s.t. \sum_{i=\epsilon_{0}\times m + 1}^{m}(_{i}^{m})\epsilon^{i}(1-\epsilon)^{m-i}<\alpha$ 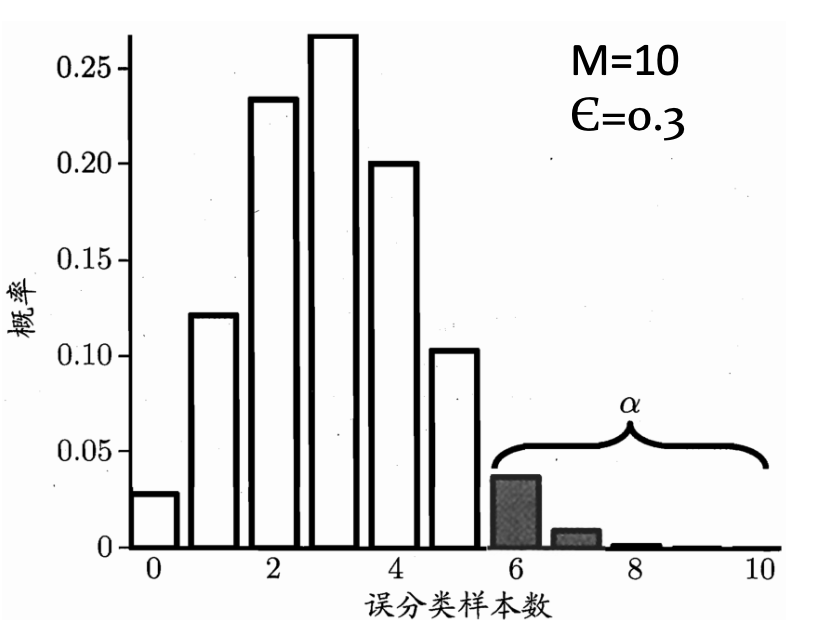
-
t检验
- 多次重复训练/测试,得到多个测试错误率
- K个测试错误率,
$\hat{\epsilon_{1}},\hat{\epsilon_{2}}...\hat{\epsilon_{k}}$ 

-
交叉验证t检验











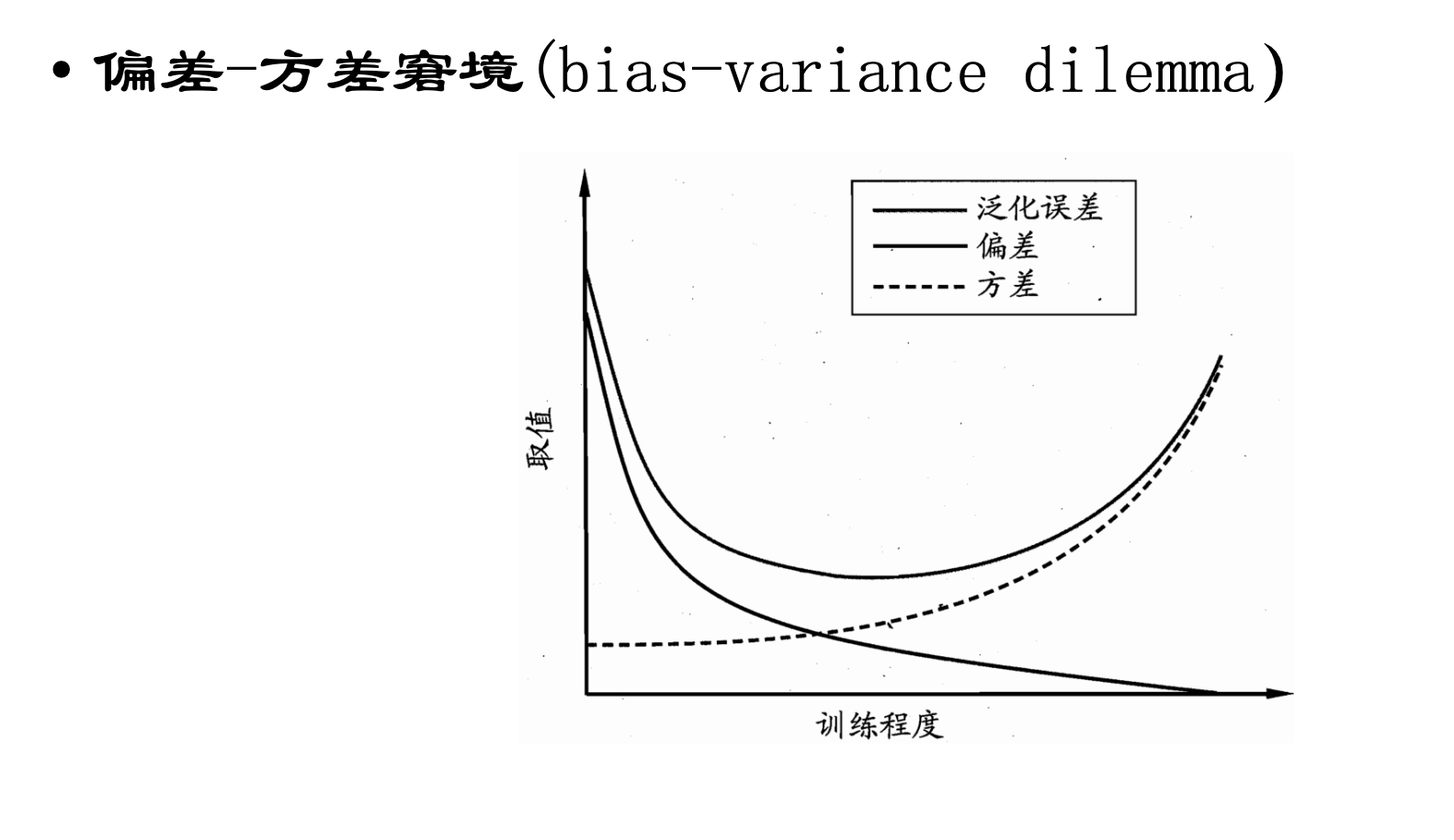
偏差与方差
- 偏差-方差分解
- 对测试样本$x$
- 令$y_D$为$x$在数据集中的标记
-
$y$ 为$x$的真实标记
-
$f(X; D)$ 为训练集$D$上学得模型$f$在$x$上的预测输出 - 回归方法的期望预测:
$\overline{f}(x)=E_{D}[f(x; D)]$ $var(x)=E_{D}[(f(x; D)-\overline{f}(x))^{2}]$ - 噪声为
$\epsilon^{2}=E_{D}[(y_{D}-y)^{2}]$ - 期望输出与真实标记的差别称为偏差
$bias^{2}(x)=(\overline{f}(x)-y)^{2}$



感知机模型
- 神经网络、支持向量机的基础 (线性可分性和对偶性)

- 感知机 (Perceptron)
- 针对: 二分类问题
- 实质: 分离超平面,判别模型
- 策略: 基于误分类的损失函数
- 方法: 利用梯度下降法对损失函数进行极小化
- 特点: 感知机学习算法具有简单而易于实现的优点
- 分类:分为原始形式和对偶形式
- 定义
- 假设输入空间 (特征空间) 是$X \subseteq \mathbb R^{n}$,输出空间是$Y={+1, -1}$
- 输入$x \in X$表示实例的特征向量,对应于输入空间 (特征空间) 的点,输出表示实例的类别,由输入空间到输出空间的函数:
-
$f(x)=sign(\vec{w}\cdot \vec{x} + b)$ 称之为感知机 - 模型参数:
$w$ ,$x$ , 内积, 权值向量, 偏置 - 符号函数
- $sign(x)=\begin{cases} +1, & x\geq 0 \ -1, & x<0 \ \end{cases}$
-
- 感知机的几何解释
- 线性方程:
$\vec{w}\cdot \vec{x} + b = 0$ - 对应于超平面$S$,
$\vec{w}$ 为法向量,$b$ 截距, 分离正负类 - 分离超平面
- 证明$\vec{w}$是法向量
- 超平面为$\vec{w}\cdot \vec{x}+b=0$, 取平面内任意两点$x_{1}, x_{2}$, 有
- $\begin{cases} \vec{w} \cdot \vec{x_1} + b = 0 & (1)\ \vec{w} \cdot \vec{x_2} + b = 0 & (2)\ \end{cases}$
-
$(1)-(2)=\vec{w}\cdot(\vec{x_1}-\vec{x_2})=0$ 且$\vec{x_1}-\vec{x_2}=\vec{x_2 x_1}$ - 因此$\vec{w}$垂直此平面
- 超平面为$\vec{w}\cdot \vec{x}+b=0$, 取平面内任意两点$x_{1}, x_{2}$, 有
- 感知机是线性的,不能处理异或分类问题
- 线性方程:

感知机学习策略
- 定义损失函数,并将其极小化
- 点到直线的距离
$Ax+By+C=0$ $d=|\frac{Ax_0 + By_0 + C}{\sqrt{A^2 + B^2}}|$
- 如何定义损失函数
- 自然选择: 误分类点的数目, 但损失函数不是$w$,
$b$ 连续可导, 不宜优化 - 另一选择: 误分类点到超平面的总距离:
- 距离:
$\frac{1}{||\vec{w}||}|\vec{w}\cdot \vec{x}_0 + b|$ - 误分类点:
$-y_{i}(\vec{w}\cdot \vec{x}+b)>0$ - 误分类点的距离:
$-\frac{1}{||\vec{w}||}y_{i}|\vec{w}\cdot \vec{x}_i + b|$ - 总距离:
$-\frac{1}{||\vec{w}||}\sum_{x_{i}\in M}y_{i}|\vec{w}\cdot \vec{x}_i + b|$
- 距离:
- 损失函数, 不考虑范数
$L(\vec{w}, b)=-\sum_{x_{i}\in M}y_{i}(\vec{w}\cdot \vec{x_{i}} + b)$ -
$M$ 为误分类点的数目
- 自然选择: 误分类点的数目, 但损失函数不是$w$,
感知机的学习算法
- 求解最优化问题:
$min_{w,b} L(w, b)=-\sum_{x_i \in M}y_{i}(w\cdot x_i + b)$ - 随机梯度下降法
- 首先任意选择一个超平面,
$w, b$ , 然后不断极小化目标函数,损失函数$L$的梯度 - 选取误分类点更新
-
$\nabla_{w}L(w, b)=-\sum_{x_{i}\in M}y_{i}x_{i}$ ,$w\leftarrow w + \eta y_{i}x_{i}$ -
$\nabla_{b}L(w, b)=-\sum_{x_{i}\in M}y_{i}$ ,$b\leftarrow b+\eta y_{i}$ -
$\eta$ : 学习步长, 学习率
-

- 例子
- 算法的收敛性
- 算法的收敛性: 证明经过有限次迭代可以得到一个将训练数据集完全正确划分的分离超平 面及感知机模型。
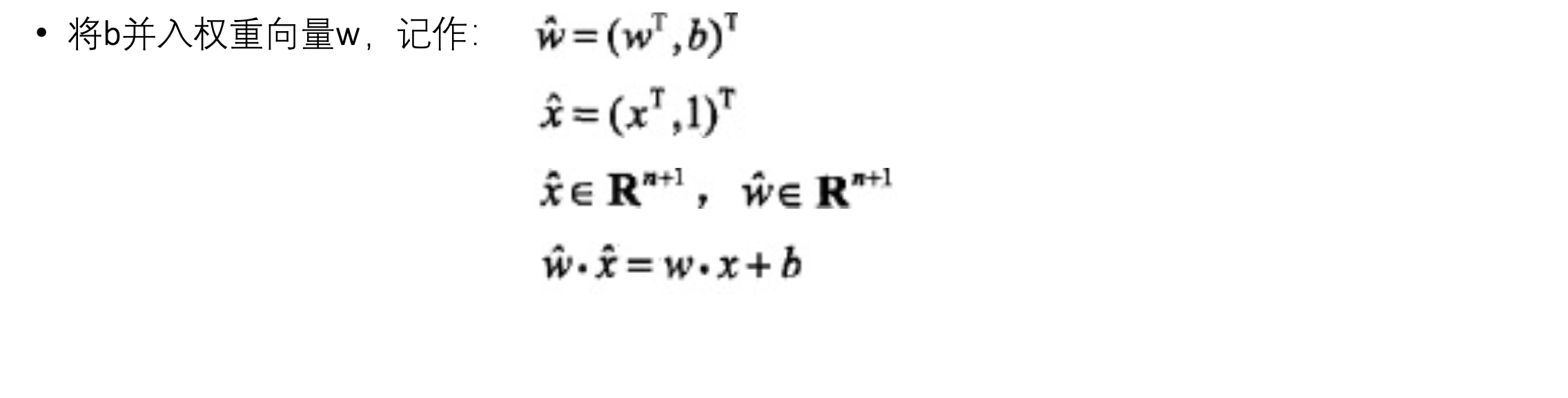






- 定理表明:
- 误分类的次数k是有上界的,当训练数据集线性可分时,感知机学习算法原始形式迭代是收 敛的。
- 感知机算法存在许多解,既依赖于初值,也依赖迭代过程中误分类点的选择顺序。
- 为得到唯一分离超平面,需要增加约束,如SVM。
- 线性不可分数据集,迭代震荡。











感知机算法的对偶形式, 类似SVM的对偶形式
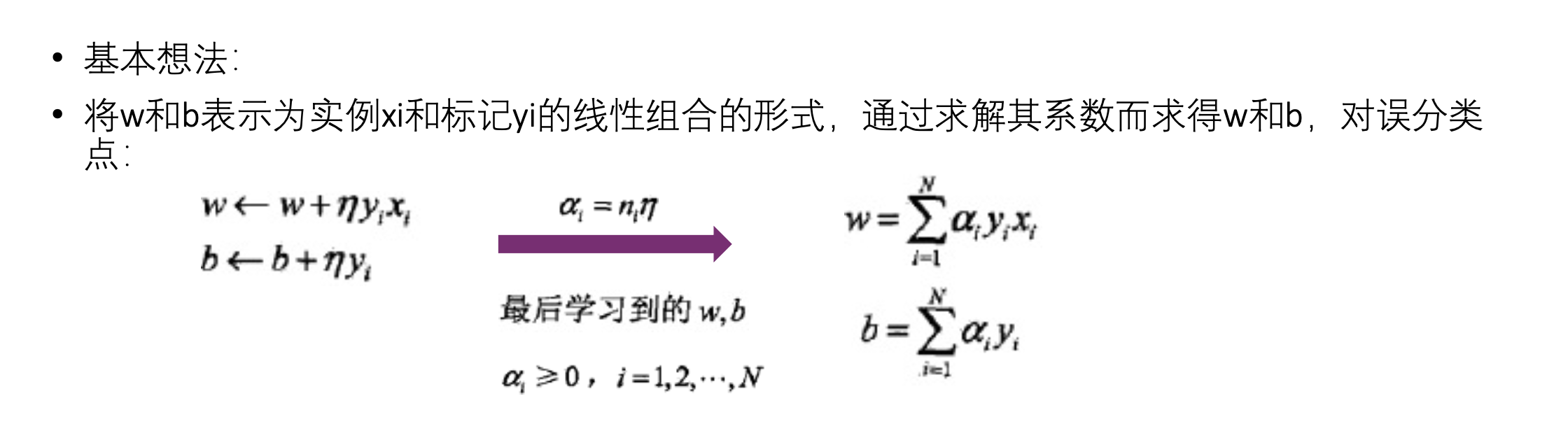
- 实例点更新次数越多,意味着该点离分离超平面?
- 不是