Distilbert-punctuator is a python package provides a bert-based punctuator (fine-tuned model of pretrained huggingface DistilBertForTokenClassification) with following three components:
-
data process: funcs for processing user's data to prepare for training. If user perfer to fine-tune the model with his/her own data.
-
training: training pipeline and doing validation. User can fine-tune his/her own punctuator with the pipeline
-
inference: easy-to-use interface for user to use trained punctuator.
-
If user doesn't want to train a punctuator himself/herself, two pre-fined-tuned model from huggingface model hub
Qishuai/distilbert_punctuator_en📎 Model detailsQishuai/distilbert_punctuator_zh📎 Model details
-
model examples in huggingface web page.
- English model
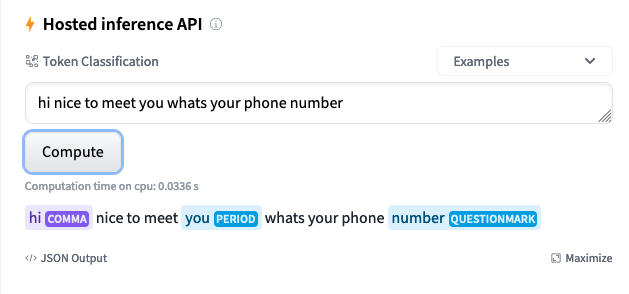
- Simplified Chinese model
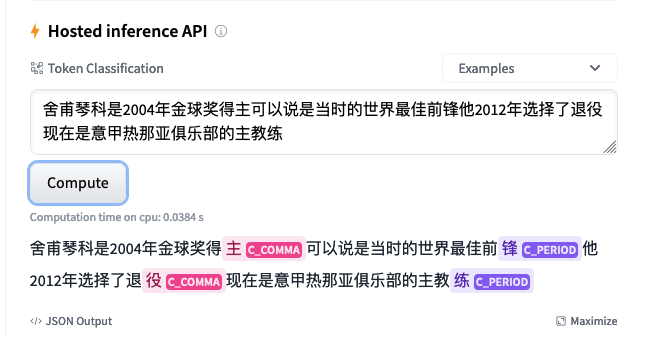


- Installing the package from pypi:
pip install distilbert-punctuatorfor directly usage of punctuator. - Installing the package with option to do data processing
pip install distilbert-punctuator[data_process]. - Installing the package with option to train and validate your own model
pip install distilbert-punctuator[training] - For development and contribution
- clone the repo
make install
Component for pre-processing the training data. To use this component, please install as pip install distilbert-punctuator[data_process]
The package is providing a simple pipeline for you to generate NER format training data.
examples/data_sample.py
Component for providing a training pipeline for fine-tuning a pretrained DistilBertForTokenClassification model from huggingface.
examples/english_train_sample.py
Arguments required for the training pipeline.
data_file_path(str): path of training datamodel_name_or_path(str): name or path of pre-trained modeltokenizer_name(str): name of pretrained tokenizersplit_rate(float): train and validation split ratemin_sequence_length(int): min sequence length of one samplemax_sequence_length(int): max sequence length of one sampleepoch(int): number of epochbatch_size(int): batch sizemodel_storage_path(str): fine-tuned model storage pathaddtional_model_config(Optional[Dict]): additional configuration for modelearly_stop_count(int): after how many epochs to early stop training if valid loss not become smaller. default 3
Validation of fine-tuned model
examples/train_sample.py
data_file_path(str): path of validation datamodel_name_or_path(str): name or path of fine-tuned modeltokenizer_name(str): name of tokenizermin_sequence_length(int): min sequence length of one samplemax_sequence_length(int): max sequence length of one samplebatch_size(int): batch sizetag2id_storage_path(Optional[str]): tag2id storage path. Default one is from model config.
Component for providing an inference interface for user to use punctuator.
+----------------------+ (child process)
| user application | +-------------------+
+ + <---------->| punctuator server |
| +inference object | +-------------------+
+----------------------+
The punctuator will be deployed in a child process which communicates with main process through pipe connection.
Therefore user can initialize an inference object and call its punctuation function when needed. The punctuator will never block the main process unless doing punctuation.
There is a graceful shutdown methodology for the punctuator, hence user dosen't need to worry about the shutting-down.
examples/inference_sample.py
Arguments required for the inference pipeline.
model_name_or_path(str): name or path of pre-trained modeltokenizer_name(str): name of pretrained tokenizertag2punctuator(Dict[str, tuple]): tag to punctuator mapping. dbpunctuator.utils provides two default mappings for English and Chinesefor own fine-tuned model with different tags, pass in your own mappingNORMAL_TOKEN_TAG = "O" DEFAULT_ENGLISH_TAG_PUNCTUATOR_MAP = { NORMAL_TOKEN_TAG: ("", False), "COMMA": (",", False), "PERIOD": (".", True), "QUESTIONMARK": ("?", True), "EXLAMATIONMARK": ("!", True), } DEFAULT_CHINESE_TAG_PUNCTUATOR_MAP = { NORMAL_TOKEN_TAG: ("", False), "C_COMMA": (",", False), "C_PERIOD": ("。", True), "C_QUESTIONMARK": ("? ", True), "C_EXLAMATIONMARK": ("! ", True), "C_COLON": (":", True), "C_DUNHAO": ("、", False), }
tag2id_storage_path(Optional[str]): tag2id storage path. Default one is from model config. Pass in this argument if your model doesn't have a tag2id inside config