A CNN based pytorch implementation on facial expression recognition (FER2013 and CK+), achieving 73.112% (state-of-the-art) in FER2013 and 94.64% in CK+ dataset
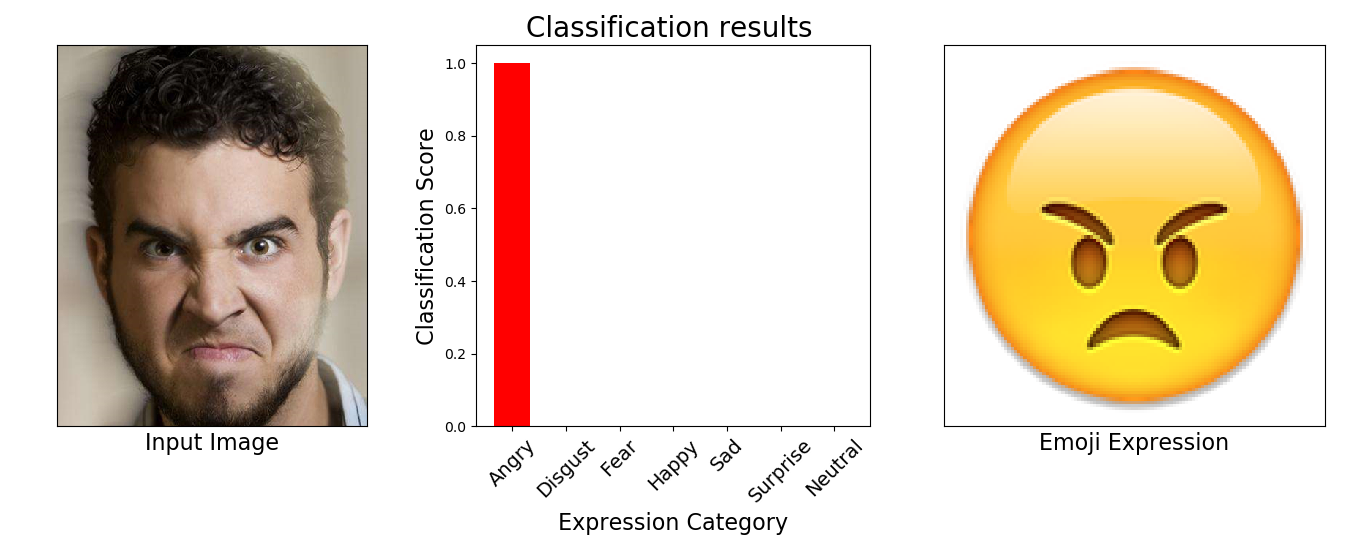
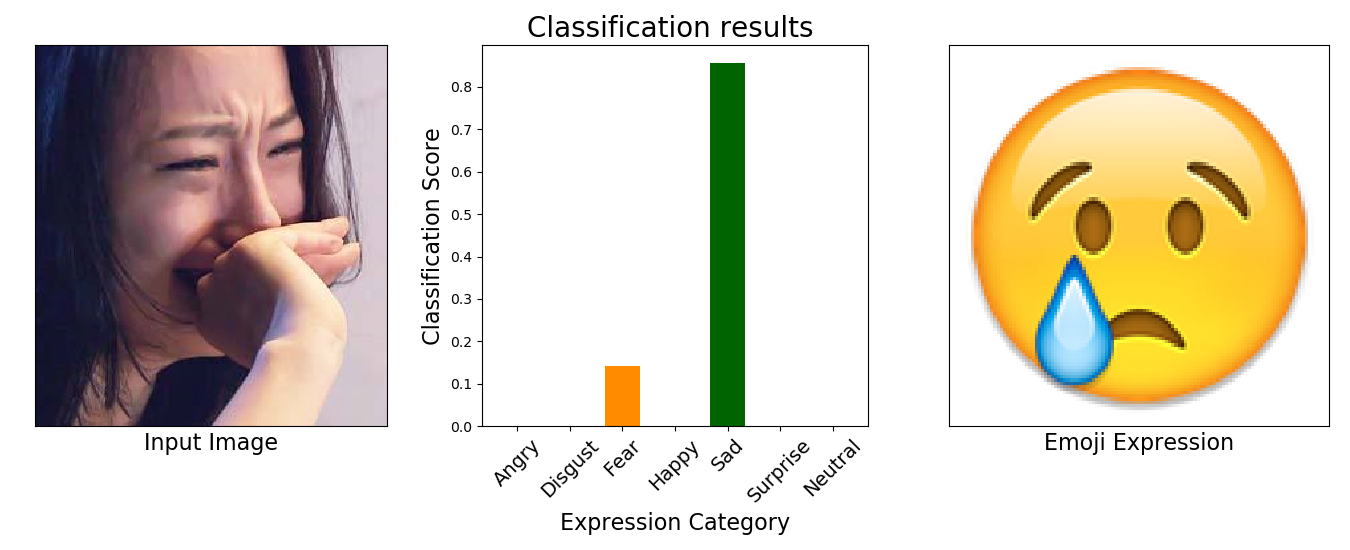
- Python 2.7
- Pytorch >=0.2.0
- h5py (Preprocessing)
- sklearn (plot confusion matrix)
- Firstly, download the pre-trained model from https://drive.google.com/open?id=1Oy_9YmpkSKX1Q8jkOhJbz3Mc7qjyISzU (or https://pan.baidu.com/s/1w2TAWzaqh8YvT-1I6rojAg, key:skg2) and then put it in the "FER2013_VGG19" folder; Next, Put the test image (rename as 1.jpg) into the "images" folder, then
- python visualize.py
- Dataset from https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data Image Properties: 48 x 48 pixels (2304 bytes) labels: 0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral The training set consists of 28,709 examples. The public test set consists of 3,589 examples. The private test set consists of another 3,589 examples.
- first download the dataset(fer2013.csv) then put it in the "data" folder, then
- python preprocess_fer2013.py
- python mainpro_FER.py --model VGG19 --bs 128 --lr 0.01
- python plot_fer2013_confusion_matrix.py --model VGG19 --split PrivateTest
- Model: VGG19 ; PublicTest_acc: 71.496% ; PrivateTest_acc:73.112%
- Model: Resnet18 ; PublicTest_acc: 71.190% ; PrivateTest_acc:72.973%
- The CK+ dataset is an extension of the CK dataset. It contains 327 labeled facial videos, We extracted the last three frames from each sequence in the CK+ dataset, which contains a total of 981 facial expressions. we use 10-fold Cross validation in the experiment.
- python mainpro_CK+.py --model VGG19 --bs 128 --lr 0.01 --fold 1
- python k_fold_train.py
- python plot_CK+_confusion_matrix.py --model VGG19
- Model: VGG19 ; Test_acc: 94.646%
- Model: Resnet18 ; Test_acc: 94.040%