gImageReader
gImageReader is a simple Gtk/Qt front-end to tesseract-ocr.
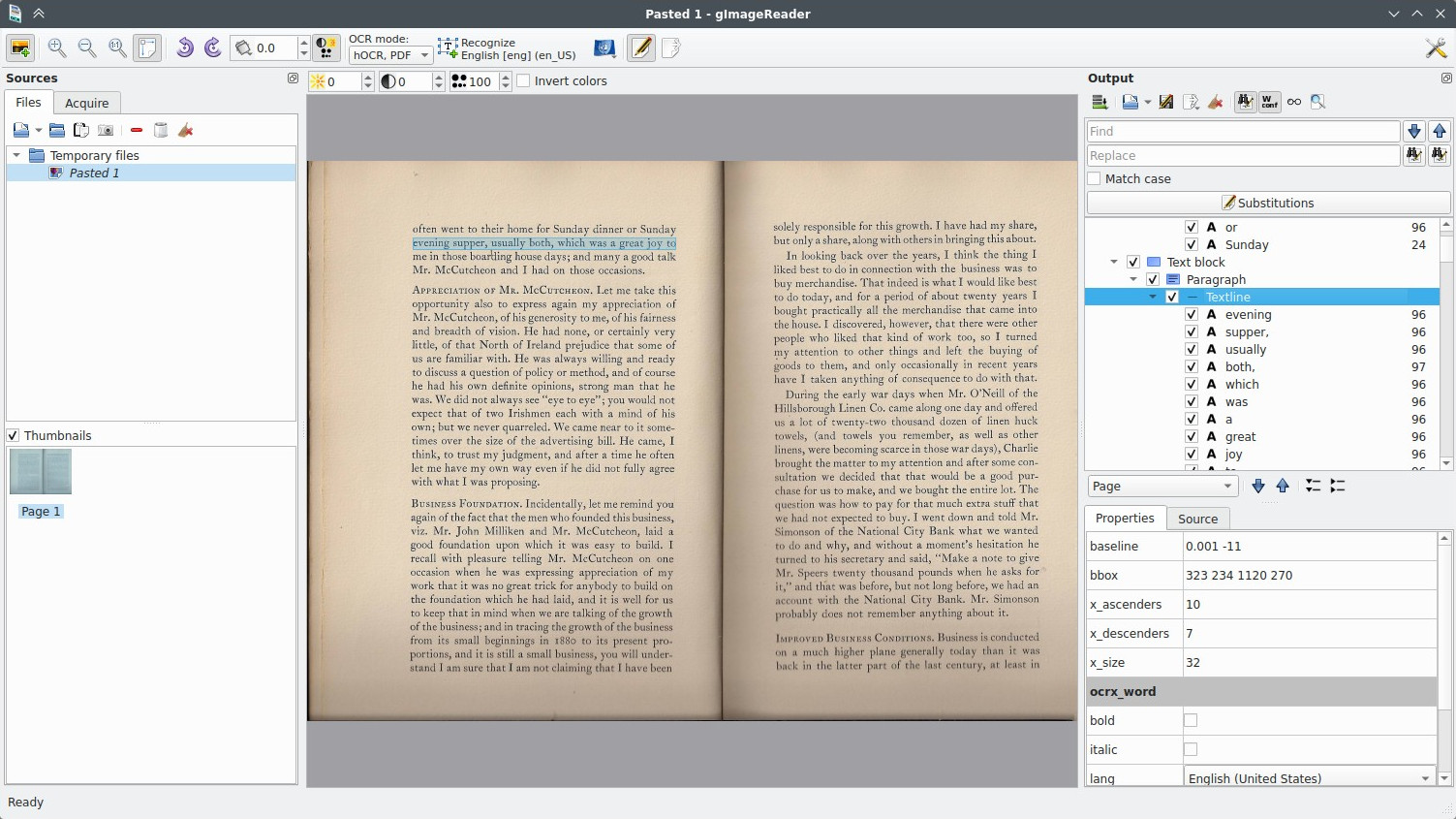
Features:
- Import PDF documents and images from disk, scanning devices, clipboard and screenshots
- Process multiple images and documents in one go
- Manual or automatic recognition area definition
- Recognize to plain text or to hOCR documents
- Recognized text displayed directly next to the image
- Post-process the recognized text, including spellchecking
- Generate PDF documents from hOCR documents
Installation:
 Source: Download from the releases page
Source: Download from the releases page Windows: Download from the releases page
Windows: Download from the releases page Fedora: Available from the official repositories
Fedora: Available from the official repositories Debian: Available from the official repositories
Debian: Available from the official repositories Ubuntu: Available from ppa:sandromani/gimagereader
Ubuntu: Available from ppa:sandromani/gimagereader OpenSUSE: Available from OpenSUSE Build Service
OpenSUSE: Available from OpenSUSE Build Service ArchLinux: Available from AUR (Gtk version) and AUR (Qt version)
ArchLinux: Available from AUR (Gtk version) and AUR (Qt version)
Compilation:
The steps for compiling gImageReader from source are documented in the wiki.
Support:
If you encounter issues, please file a ticket in the issue tracker, or feel free to mail me directly at manisandro(at)gmail(dot)com. Be sure to also consult the FAQ.
Contributing:
Contributions are always welcome, ideally in the form of pull-requests.
Especially welcome are translations. These can be created as follows:
- Copy
po/gimagereader.potfile topo/<language>.po(i.e.po/de.po) - Translate the strings in
po/<language>.po - Add the language to
po/LINGUAS