This project is under development not ready
This project is a simple and customizable Text-to-Speech (TTS) application that converts input text into audio using a pre-trained PyTorch model (model.pth). The intuitive web interface allows you to upload your TTS model, input text, and generate speech.
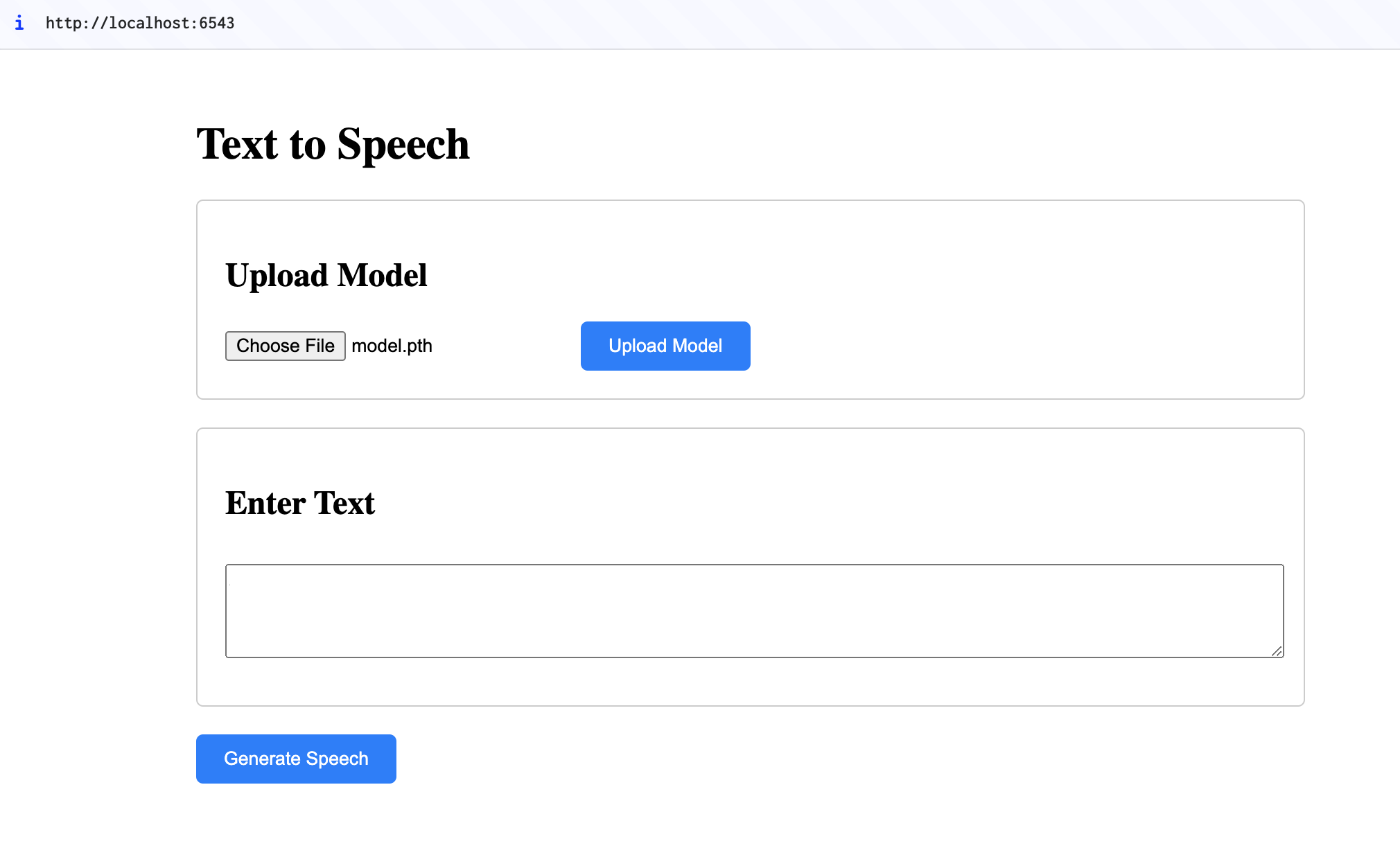
- Model Upload: Load your pre-trained TTS model in
.pthformat. - Text Input: Enter any text you want to convert into speech.
- Audio Generation: Generate and download the speech audio file.
Ensure you have the following installed:
- Python 3.8 or higher
- Pyramid
- PyTorch
- TorchAudio
-
Clone the repository:
git clone https://github.com/yourusername/text-to-speech-app.git cd bavard -
Install the dependencies:
poetry install
-
Run the application:
poetry serve
-
Open your browser and navigate to:
http://localhost:6543
- Upload Model: Click "Choose File" to upload your
model.pthfile. - Enter Text: Type the desired text in the input box.
- Generate Speech: Click the "Generate Speech" button to convert the text into an audio file.
- Playback or Download: Listen to the generated audio or download it.
.
├── services # Pytorch services comsuption
├── static/ # Static files (CSS, JS)
├── templates/ # HTML templates
├── controllers.py # MVC Controllers
├── routes.py # Pyramid routes
├── scripts.py # Poetry tasks scripts
└── views.py # MVC Views
Contributions are welcome! Please open an issue or submit a pull request if you'd like to add new features or improvements.
This project is licensed under the MIT License. See the LICENSE file for details.
For any questions or suggestions, feel free to reach out:
- Email: ramonlimaramos@gmail.com
- GitHub: @ramonlimaramos