Beyond Vectors: Augment LLM Capabilities with MongoDB Aggregation Framework
In the dynamic landscape of investment management, real-time transaction data is your most powerful ally. A single bad decision can have a ripple effect felt throughout your entire portfolio. Unlocking the actionable insights buried within raw transactional data holds the key to making sound, strategic investment decisions. This blog post will explore how MongoDB's Aggregation Framework and GenAI can work together to transform your data analysis workflow.
Large Language Models (LLMs) have revolutionized our interaction with computers, providing capabilities such as drafting emails, writing poetry, and even engaging in human-like conversations. However, when it comes to dealing with complex data processing and mathematical calculations, LLMs have their limitations.
While Large Language Models (LLMs) excel at language, they lack the ability to understand and manipulate numbers or symbols in the same way. Additionally, LLMs rely on a limited context window for processing information, and cannot directly access database systems.
That's where MongoDB's Aggregation Framework shines, offering an efficient and powerful solution for complex data analysis tasks. It allows you to process entire collections of data, passing it through a multi-stage data pipeline. Within these stages, you can perform calculations and transformations on entire collections. This bypasses the limitations of LLMs for numerical computations, providing a robust and reliable method for data analysis.
In this blog post, we’ll combine the power of the MongoDB Aggregation framework with GenAI to overcome the limitations of “Classic RAG”. We'll explore this by delving into the MongoDB Atlas Sample Dataset, specifically the sample_analytics database. The transaction data offers a realistic dataset that allows users to hone their skills in data analysis, querying, and aggregation, particularly in the context of financial data.
Collection: transactions
- transaction_id: This is a unique identifier that distinctly marks each transaction.
- account_id: This field establishes a connection between the transaction and its corresponding account.
- date: This represents the precise date and time at which the transaction took place.
- transaction_code: This indicates the nature of the transaction, such as a deposit, withdrawal, buy, or sell.
- symbol: If relevant, this field denotes the symbol of the stock or investment involved in the transaction.
- amount: This reflects the value of the transaction.
- total: This captures the comprehensive transacted amount, inclusive of quantities, fees, and any additional charges associated with the transaction.
The Power of Transactional Data
Stock transaction data offers a wealth of information for investment researchers and analysts. By carefully examining patterns within this data, you can:
- Identify Trends: Spot emerging market movements and potential shifts in investor sentiment.
- Uncover Hidden Opportunities: Discover undervalued stocks or sectors poised for growth.
- Manage Risk: Assess the volatility of specific holdings and make informed decisions about asset allocation for optimal risk-return balance.
Consider a scenario where we need to determine the return on investment (ROI) for each stock over a certain period. This task involves filtering the sales by product, calculating the ROI, and then sorting these to find the stocks with the highest returns. Traditional methods like SQL or application code processing can be complex and inefficient, especially with large datasets.
In SQL, this would require multiple subqueries, temporary tables, and joins - a complex and potentially inefficient process, especially with large datasets. With application code, you would need to retrieve all the data first, calculate the ROI, and then perform the sorting, which could be resource-intensive.
Navigating these complexities can be made more efficient by harnessing the power of MongoDB's Aggregation Framework, combined with the intelligent capabilities of AI technologies like CrewAI and Large Language Models (LLMs). This potent combination not only streamlines the process but also uncovers deeper insights from our data.
Benefits
- Informed Decision-Making: ROI analysis provides a clear metric for evaluating the success of past investments. This data empowers investors, from individuals to large institutions, to make informed decisions about buying, selling, or holding specific stocks.
- Portfolio Optimization: Identifying high and low-performing stocks is crucial for adjusting your investment mix. You might shift investments towards top-performing assets or re-evaluate underperforming ones.
- Identifying Trends: Analyzing ROI over time can reveal trends within individual stocks or broader market sectors. Recognizing these patterns helps investors anticipate potential opportunities or risks.
- Benchmarking: Comparing your portfolio's ROI to relevant market indices helps gauge how your investments are performing relative to the overall market.
- Tax Implications: In many jurisdictions, calculating the ROI of investments plays a role in determining capital gains or losses, impacting tax calculations.
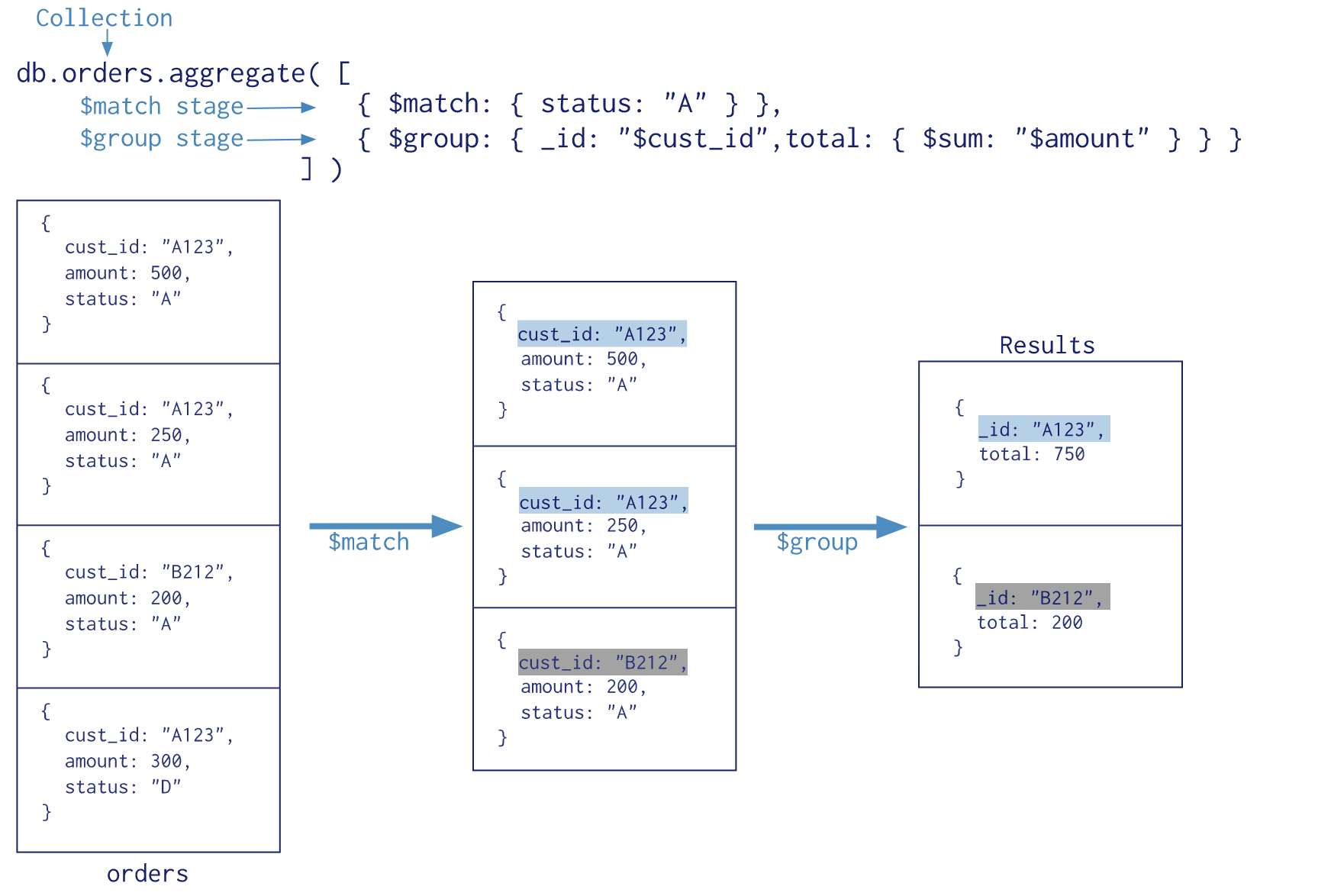
The MongoDB Aggregation Framework provides a powerful data processing pipeline where documents are transformed to produce aggregated results. By executing complex calculations and data manipulations directly on the server-side, it significantly reduces the volume of data that needs to be transferred across the network. This optimization is crucial when working with Large Language Models (LLMs) - specially those that are hosted remotely like OpenAI.
LLMs excel at understanding and generating human-like text, but they can be constrained by the size of their context window (the amount of input text they can process at once). Preprocessing and aggregating data with MongoDB's Aggregation Framework effectively shrinks the dataset that needs to be fed to the LLM.
By moving the math and the data aggregation to MongoDB, you can leverage the LLM's language capabilities for high-value tasks like:
- Generating insightful summaries and interpretations: Summarizing pre-aggregated trends identified by MongoDB.
- Crafting compelling narratives: Turning data points into engaging business reports.
- Answering complex questions about the data: The LLM can combine its understanding of the processed data with external knowledge to provide richer answers.
MongoDB's Aggregation Framework provides an efficient and straightforward solution for this complex analysis. Here's how you could write the query:
[
{
"$unwind": "$transactions"
},
{
"$group": {
"_id": "$transactions.symbol",
"buyValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "buy"] },
{ "$toDouble": "$transactions.total" },
0
]
}
},
"sellValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "sell"] },
{ "$toDouble": "$transactions.total" },
0
]
}
}
}
},
{
"$project": {
"_id": 0,
"symbol": "$_id",
"returnOnInvestment": { "$subtract": ["$sellValue", "$buyValue"] }
}
},
{
"$sort": { "returnOnInvestment": -1 }
}
]This MongoDB Aggregation Framework pipeline is composed of multiple stages, each performing a specific operation on the data:
-
$unwind: This stage deconstructs an array field from the input documents to output a document for each element. Here we're unwinding thetransactionsarray. -
$group: This stage groups input documents by a specified identifier expression and applies the accumulator expression(s) to each group. We're grouping bytransactions.symboland calculating thebuyValueandsellValuefor each group. -
$project: This stage reshapes each document in the stream by renaming, adding, or removing fields, as well as creating computed values and sub-documents. We're projecting thesymbolandreturnOnInvestment(calculated by subtractingbuyValuefromsellValue) fields. -
$sort: This stage reorders the document stream by a specified sort key. We're sorting the documents byreturnOnInvestmentin descending order.
This pipeline calculates the total buy and sell values for each stock, and then calculates the return on investment by subtracting the total buy value from the total sell value. The stocks are then sorted by return on investment in descending order, so the stocks with the highest returns are at the top.
To run this query, you'll need access to a MongoDB instance with the sample data.
Here's a simple way to run it using pymongo, a Python driver for MongoDB:
import pymongo
client = pymongo.MongoClient("mongodb+srv://<username>:<password>@cluster0.mongodb.net/test")
db = client["sample_analytics"]
collection = db["transactions"]
pipeline = [
{
"$unwind": "$transactions"
},
{
"$group": {
"_id": "$transactions.symbol",
"buyValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "buy"] },
{ "$toDouble": "$transactions.total" },
0
]
}
},
"sellValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "sell"] },
{ "$toDouble": "$transactions.total" },
0
]
}
}
}
},
{
"$project": {
"_id": 0,
"symbol": "$_id",
"returnOnInvestment": { "$subtract": ["$sellValue", "$buyValue"] }
}
},
{
"$sort": { "returnOnInvestment": -1 }
}
]
results = list(collection.aggregate(pipeline))
for result in results:
print(result)The result will be a list of documents, each representing a unique stock, and containing the return on investment for that stock.
{'symbol': 'amzn', 'returnOnInvestment': 72769230.71428967}
{'symbol': 'sap', 'returnOnInvestment': 39912931.04990542}
{'symbol': 'aapl', 'returnOnInvestment': 25738882.292086124}
{'symbol': 'adbe', 'returnOnInvestment': 17975929.726718843}
{'symbol': 'bb', 'returnOnInvestment': 12396285.970310092}
{'symbol': 'amd', 'returnOnInvestment': 7910082.824741647}
{'symbol': 'csco', 'returnOnInvestment': 5688005.834037811}
{'symbol': 'nvda', 'returnOnInvestment': 5233665.374793142}
{'symbol': 'ebay', 'returnOnInvestment': 3608593.9555669427}
{'symbol': 'fb', 'returnOnInvestment': 1100046.9410015345}
{'symbol': 'znga', 'returnOnInvestment': 208171.51880900562}
{'symbol': 'team', 'returnOnInvestment': -406507.08118489385}
{'symbol': 'nflx', 'returnOnInvestment': -2133963.99949342}
{'symbol': 'intc', 'returnOnInvestment': -7407861.202953339}
{'symbol': 'crm', 'returnOnInvestment': -15106640.203961253}
{'symbol': 'msft', 'returnOnInvestment': -15665720.737709165}
{'symbol': 'ibm', 'returnOnInvestment': -18356948.23498428}
{'symbol': 'goog', 'returnOnInvestment': -168114276.91805267}
This approach leverages MongoDB's Aggregation Framework to perform complex data analysis tasks efficiently, directly within the database, without requiring extensive data transfer or additional processing in the application code.
The data presented above provides a snapshot of the return on investment (ROI) for various tech stocks.
The top performers in terms of ROI are Amazon (AMZN), SAP, and Apple (AAPL), with impressive returns of 72.7 million, 39.9 million, and 25.7 million respectively. These companies have demonstrated consistent growth and profitability, making them attractive to investors.
On the other end of the spectrum, we see negative returns for companies like Atlassian (TEAM), Netflix (NFLX), Intel (INTC), Salesforce (CRM), Microsoft (MSFT), IBM, and Google (GOOG). This indicates a loss on the investments made in these stocks. The most significant loss was incurred by Google, with a negative return of 168.1 million.
Supercharging Insights with AI
The aggregation framework lays the groundwork, but we can take our analysis a step further with AI. Imagine an AI assistant that can:
- Summarize Trends: Get concise summaries of complex data patterns calculated by MongoDB.
- Link to External News: Connect market trends with real-time news on companies you're invested in.
- Answer Complex Questions: Ask questions about the dataset and get responses that combine the data with insights from the wider financial world.
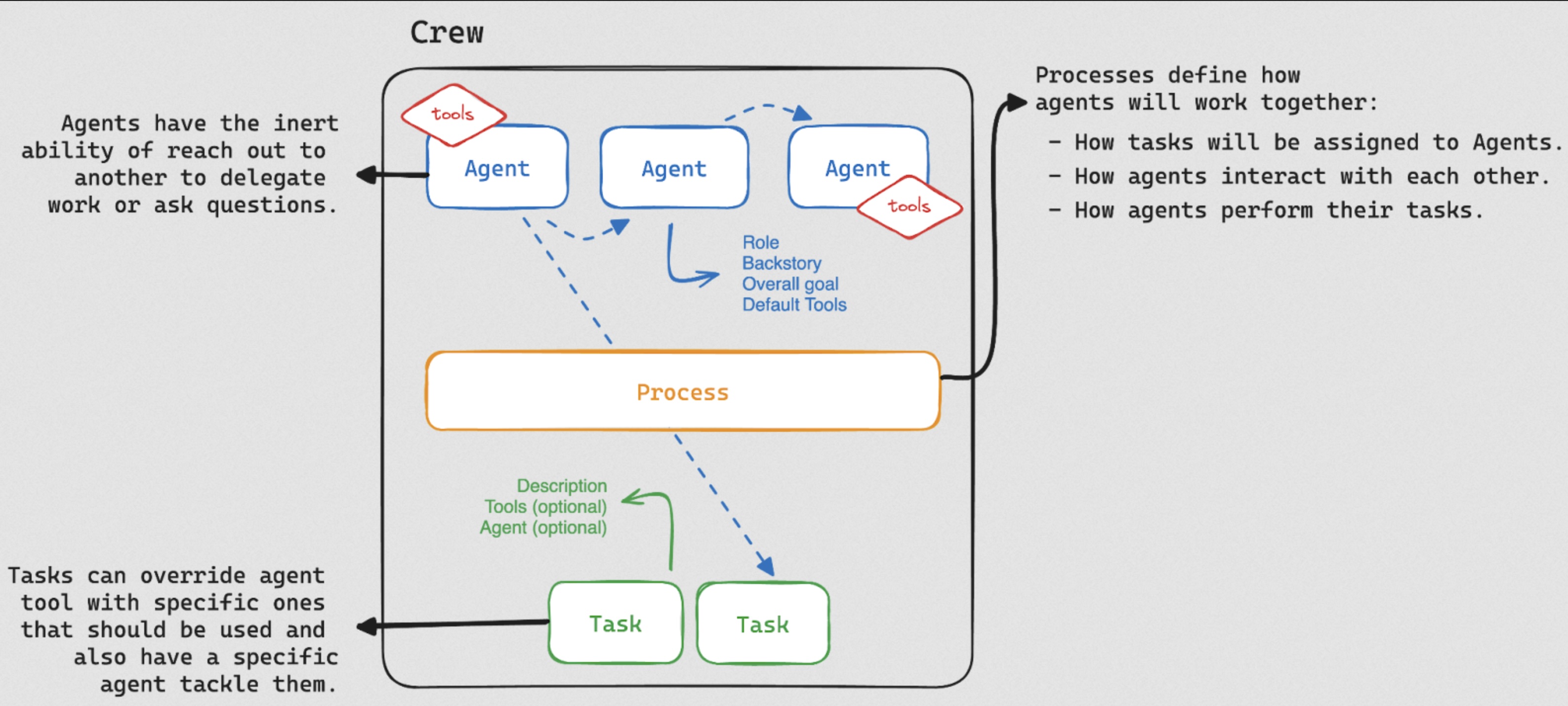
(image from LangChain Blog | CrewAI: The Future of AI Agent Teams)
The financial world is fueled by data analysis. The faster you can extract meaningful insights from raw data, the better your investment decisions will be. CrewAI, combined with the power of MongoDB Atlas, provides a unique automation approach that goes beyond basic number-crunching to deliver truly actionable analysis.
For this example, we will create an Investment Researcher Agent. This agent is our expert, skilled in finding valuable data using tools like search engines. It's designed to hunt down financial trends, company news, and analyst insights.
Unlocking the Power of AI Collaboration: Agents, Tasks, and Tools
The realm of artificial intelligence (AI) is rapidly evolving, transforming how we approach tasks and projects in the data-driven world we live in. CrewAI takes this a step further by introducing a groundbreaking framework for collaborative AI. This framework empowers teams to achieve more than ever before by leveraging the combined strengths of specialized AI units and streamlined workflows.
At the core of CrewAI lie agents. These are not your typical AI assistants; instead, they function as intelligent team members, each with a distinct role (e.g., researcher, writer, editor) and a well-defined goal. They possess the capability to perform tasks, make decisions, and even communicate with other agents to achieve the overarching objectives of a crew.
But what truly sets CrewAI apart is its ability to orchestrate seamless collaboration between these agents. This is achieved through a system of tasks. Tasks act as the building blocks of CrewAI workflows, allowing you to define a sequence of actions that leverage the strengths of different agents.
CrewAI also provides a comprehensive arsenal of tools that further empower these agents. These tools encompass a wide range of capabilities, including web scraping, data analysis, and content generation. By equipping agents with the right tools, you can ensure they have everything they need to perform their tasks effectively.
In essence, CrewAI's powerful combination of agents, tasks, and tools empowers you to:
- Automate repetitive tasks: Free up your team's valuable time and resources by automating mundane or repetitive tasks.
- Streamline workflows: Design efficient workflows that leverage the strengths of AI collaboration.
- Unlock the true potential of AI: Move beyond basic AI functionalities and harness the power of collaborative AI for complex projects.
Before We Start
To follow along, you'll need:
-
MongoDB Atlas Cluster: Create your free cluster and load the Sample Dataset. The transaction data in the sample analytics dataset offers a realistic dataset that allows users to hone their skills in data analysis, querying, and aggregation, particularly in the context of financial data.
-
SERPER_API_KEY: Sign up for a free account at https://serper.dev. Serper is a Google Search API that will grant our CrewAI setup access to real-time market data and news, enriching our analysis beyond just database calculations.
-
LLM Resource: CrewAI supports various LLM connections, including local models (Ollama), APIs like Azure, and all LangChain LLM components for customizable AI solutions. Click here to learn more about CrewAI LLM Support
In this section, we'll walk through the Python code used to perform financial analysis based on transaction data stored in MongoDB, using Azure OpenAI and Google Search API for data analysis and insights. The Python version used during development was: 3.10.10
First, we set up a connection to MongoDB using pymongo. This is where our transaction data is stored. We'll be performing an aggregation on this data later.
import os
import pymongo
MDB_URI = "mongodb+srv://<user>:<password>@cluster0.abc123.mongodb.net/"
client = pymongo.MongoClient(MDB_URI)
db = client["sample_analytics"]
collection = db["transactions"]Next, we set up our connection to Azure OpenAI. Azure OpenAI can be replaced by your preferred LLM.
from langchain_openai import AzureChatOpenAI
AZURE_OPENAI_ENDPOINT = "https://__DEMO__.openai.azure.com"
AZURE_OPENAI_API_KEY = "__AZURE_OPENAI_API_KEY__"
deployment_name = "gpt-4-32k" # The name of your model deployment
default_llm = AzureChatOpenAI(
openai_api_version=os.environ.get("AZURE_OPENAI_VERSION", "2023-07-01-preview"),
azure_deployment=deployment_name,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_key=AZURE_OPENAI_API_KEY
)We're also going to use the Google Search API. This will be used by our "researcher" agent to find relevant financial data and news articles.
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain.agents import Tool
search = GoogleSerperAPIWrapper(serper_api_key='__API_KEY__')
search_tool = Tool(
name="Google Answer",
func=search.run,
description="useful for when you need to ask with search"
)We'll be using CrewAI to manage our agents and tasks. In this case, we have one agent - a researcher who is tasked with analyzing the data and providing actionable insights.
from crewai import Crew, Process, Task, Agent
researcher = Agent(
role='Investment Researcher',
goal="""
Research market trends, company news, and analyst reports to identify potential investment opportunities.
""",
verbose=True,
llm=default_llm,
backstory='Expert in using search engines to uncover relevant financial data, news articles, and industry analysis.',
tools=[search_tool]
)
analysis_task = Task(
description="""
Using the following information:
[VERIFIED DATA]
{agg_data}
*note*
The data represents the average price of each stock symbol for each transaction type (buy/sell),
and the total amount of transactions for each type. This would give us insight into the average costs and proceeds from each stock,
as well as the volume of transactions for each stock.
[END VERIFIED DATA]
[TASK]
- Provide a financial summary of the VERIFIED DATA
- Research current events and trends, and provide actionable insights and recommendations
""",
agent=researcher,
expected_output='concise markdown financial summary and list of actionable insights and recommendations',
tools=[search_tool],
)
tech_crew = Crew(
agents=[researcher],
tasks=[analysis_task],
process=Process.sequential
)Next, we define our MongoDB aggregation pipeline. This pipeline is used to process our transaction data and calculate the return on investment for each stock symbol.
pipeline = [
{"$unwind": "$transactions"},
{"$group": {
"_id": "$transactions.symbol",
"buyValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "buy"] },
{ "$toDouble": "$transactions.total" },
0
]
}
},
"sellValue": {
"$sum": {
"$cond": [
{ "$eq": ["$transactions.transaction_code", "sell"] },
{ "$toDouble": "$transactions.total" },
0
]
}
}
}
},
{"$project": {
"_id": 0,
"symbol": "$_id",
"returnOnInvestment": { "$subtract": ["$sellValue", "$buyValue"] }
}
},
{"$sort": { "returnOnInvestment": -1 }}
]
results = list(collection.aggregate(pipeline))
client.close()
print("MongoDB Aggregation Pipeline Results:")
print(results)Finally, we kick off our task execution. The researcher agent will use the data from our MongoDB aggregation, as well as any other tools at their disposal, to analyze the data and provide insights.
tech_crew.kickoff(inputs={'agg_data': str(results)})Thought: I now know the final answer
Final Answer:
Financial Summary:
From the verified data, we can see that the following stocks have generated the highest returns on investment:
1. Amazon (AMZN): 72,769,230.71
2. SAP: 39,912,931.05
3. Apple (AAPL): 25,738,882.29
4. Adobe (ADBE): 17,975,929.73
On the other hand, the following stocks have produced negative returns:
1. Atlassian Corporation Plc (TEAM): -406,507.08
2. Netflix (NFLX): -2,133,963.99
3. Intel Corporation (INTC): -7,407,861.20
4. Salesforce (CRM): -15,106,640.20
5. Microsoft (MSFT): -15,665,720.74
6. IBM: -18,356,948.23
7. Google (GOOG): -168,114,276.92
Actionable Insights and Recommendations:
Based on current news and events:
1. Amazon (AMZN): The company's stock is performing strongly, approaching its record high of 2021. It is recommended to keep an eye on this stock for potential investment opportunities.
2. SAP: Despite the company's plan to cut jobs, analysts have a positive outlook on the stock. It is advisable to monitor the stock closely for any changes in its performance.
3. Apple (AAPL): The recent surge in the company's stock value due to its intention to delve into AI shows promising growth. Investors may consider this stock for potential investment.
4. Adobe (ADBE): The stock is showing a positive sentiment in relation to other stocks in the technology sector and has a high price target set by Wall Street analysts. It is recommended to watch this stock for potential growth.
It is also suggested to keep a close eye on those stocks that are currently showing negative returns. Understanding the reasons behind their poor performance could provide investment opportunities if these issues are addressed and the businesses start to turn around.
While the combination of MongoDB's Aggregation Framework and GenAI represents a powerful tool for data analysis and interpretation, it's important to recognize a few potential limitations:
-
Dependence on Historical Data: Past performance may not always predict future results, especially in unpredictable markets where unforeseen events can significantly impact investment outcomes.
-
Uncertainty in Predictions: Despite the sophistication of the analysis, there will always be an inherent degree of uncertainty in investment predictions. Future outcomes are inherently unknowable, and factors beyond the scope of historical data can influence results.
-
LLM Limitations: LLMs are still evolving, and their ability to research, interpret and analyze data is continually improving. However, biases in training data or limitations in the model's architecture could lead to inaccurate or misleading insights.
By being aware of these limitations and taking steps to mitigate them, you can ensure a more responsible and well-rounded approach to investment analysis.
In this blog post, we explored how MongoDB's Aggregation Framework, Large Language Models (LLMs), and CrewAI can be leveraged to transform investment analysis. The key to unlocking smarter investment decisions lies in harnessing the power of your transaction data. MongoDB's Aggregation Framework provides the tools to efficiently calculate essential metrics like ROI, trends, and volatility. When combined with AI's ability to interpret these findings, you gain a deeper understanding of the market. This empowers you to identify hidden opportunities, make informed decisions, and automate routine analysis, ultimately boosting your investment success.
The future of investment analysis belongs to those who embrace the power of data and AI. By combining MongoDB's robust data handling with the insight-generating capabilities of AI tools like CrewAI, you gain the tools to:
- Analyze trends faster than those relying on traditional methods.
- Identify profitable patterns that others miss.
- Make informed decisions backed by both raw data and contextual insights.
- Automate tedious analysis, giving you more time for strategic thinking.
Don't just analyze the market – shape it. Start harnessing the potential of MongoDB and AI today, and transform your investment decision-making process.
The source code is available at GitHub - mdb-agg-crewai