2023年第十八届“挑战杯”全国大学生课外学术科技作品竞赛“揭榜挂帅”专项赛
参加竞榜的选题发榜单位: **软件与技术服务股份有限公司
参加竞榜的选题名称: 基于信创的学习迁移模型构建知识图谱
申报作品具体名称: 融智图谱——学习迁移模型构建知识图谱
负责人:孤飞 ranxi169@163.com
针对源代码的使用说明
建议创建一个python3.8的虚拟环境,可能需要安装Rust Compiler
首先需要安装CUDA和PaddlePaddle(飞桨)框架:
针对CUDA 11.6我们第一步首先在终端运行以下代码:
pip install paddlepaddle-gpu==2.5.1.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
然后安装PaddleNLP:
pip install paddlenlp -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
以及安装Pytorch:
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
安装transformers:
pip install transformers -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
其余依赖按照requirements.txt安装即可。
--揭榜挂帅
--data-final:最终数据集(分为policy和news的train和test)格式为重新按照句子分段的txt
--data-origin:原始提供的多模态数据
--data-preprocess:转换多模态数据为txtline数据格式的脚本
--other-to-txt:第一步:将各种数据格式文件转换为txt文件
--txt-resegment:第二步:将所有的txt文件重新分句,使得每个段落(\n)不至于太长。
--train-test-split:第三步:将所有txt文件分为训练集和测试集
--data-preprocessed:多模态数据转化后的txt格式的数据集
--new-news:包含从wps、pdf和docx转换的txt文件
--new-policy:原本的txt文件,因为policy只有txt文件
--dataset-develop:用于开发更多功能的数据生成脚本
--batch-result-api.py:在后端等待并直接输出算法结果的api,可以批量输出
--batch-result-save.py:调用后端输出的api,批量输入txt获得算法结果
--docker:用于构建docker镜像的工作目录
--torch:语句补全的docker镜像源码
--uie:实体识别和关系抽取的docker镜像源码
--mixed-filter:用于过滤输出结果,混合过滤器提升模型最终结果准确性
--presentation:交互式前端展示,html,api和css
--back-end-api.py:后端api,先运行在888端口
--presentation.html:前端展示实体识别和关系提取代码,可以调用后端api
--sentence-comletion:知识框架补全部分,实现句子补全
--uie-model:基于飞桨UIE模型的迁移微调信息抽取模型
--checkpoint:模型微调后模型保存到的目录
--model_best4000:最终提交的模型文件目录,包含12个模型文件
--data:放置用于测试、模型微调训练的数据文件
--doccano_ext.json:其中只用放置这个标注的数据集文件,其余文件通过tran.sh脚本生成
--deploy:UIE模型部署到服务器的基础代码目录,不需要修改
--train.sh:从本目录下的data数据集获取train.txt数据进行模型微调训练的脚本
--tran.sh:将doccano_ext.json文件转换为train.txt、test.txt、name.txt、dev.txt
--model_evaluation:测试全部类型的实体与关系的准确率和召回率的脚本
--model_debug.sh:测试各个类型的实体和关系的精确率和召回率的脚本
--其余py文件:模型训练与测试等代码不用修改
--uie-pytorch:由飞桨版本UIE重构的Pytorch版本模型
--convert.sh:将uie paddle模型转换为pytorch动态图模型
--export.sh:将pytorch动态图模型转换为onnx静态图模型
--autoapi.py:在服务器上提供api,通过接口访问模型并返回预测结果的脚本
--localtest.py:在本地对事先输入的文本进行预测并返回预测结果的脚本
--requirements.txt:运行项目需要安装的Python库
- 准备好标注好的数据
doccano_ext.json,放进uie-model目录下的data文件夹内 - 运行
tran.sh,就会将从doccano导出的标注数据转化为模型的输入数据和测试数据 - 运行
train.sh,就可以开始训练uie-base模型,训练结束后会保存模型到checkpoint目录下的model_best路径下,train.sh可以根据自己的需求修改参数。
由于github等版本控制工具仓库有大文件限制,且模型文件通过git传输较慢,故将模型上传至百度网盘。提供了直接拷贝整个项目之外的快速传输方案。
将下载的压缩包解压后复制当前目录不存在的模型目录即可。
文件:model-best4000.rar 、 uie-pytorch.rar 、 docker.rar
链接:https://pan.baidu.com/s/1CLdcpnjK2CEDh0tZvZV6RA?pwd=czci
提取码:czci
运行model_evaluation.sh,就可以开始测试整个模型的精确率、召回率了,本模型的F1-Score能够达到97%,**三项指标性能均超过95%**满足题目要求。

运行model_debug.sh,就可以开始测试整个模型的精确率,召回率了,
实体识别精确率、召回率、F1-Score均高于95%.
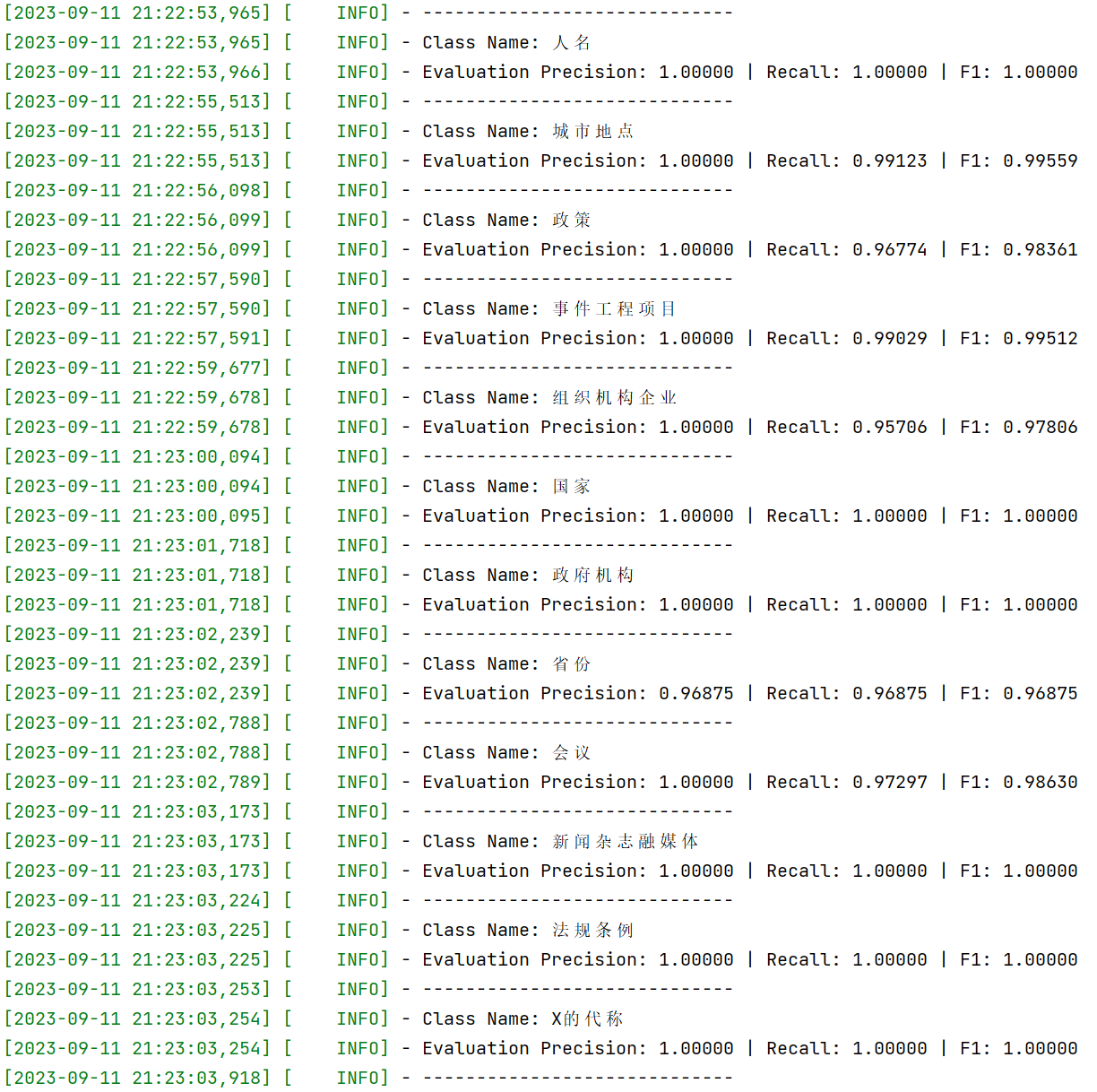
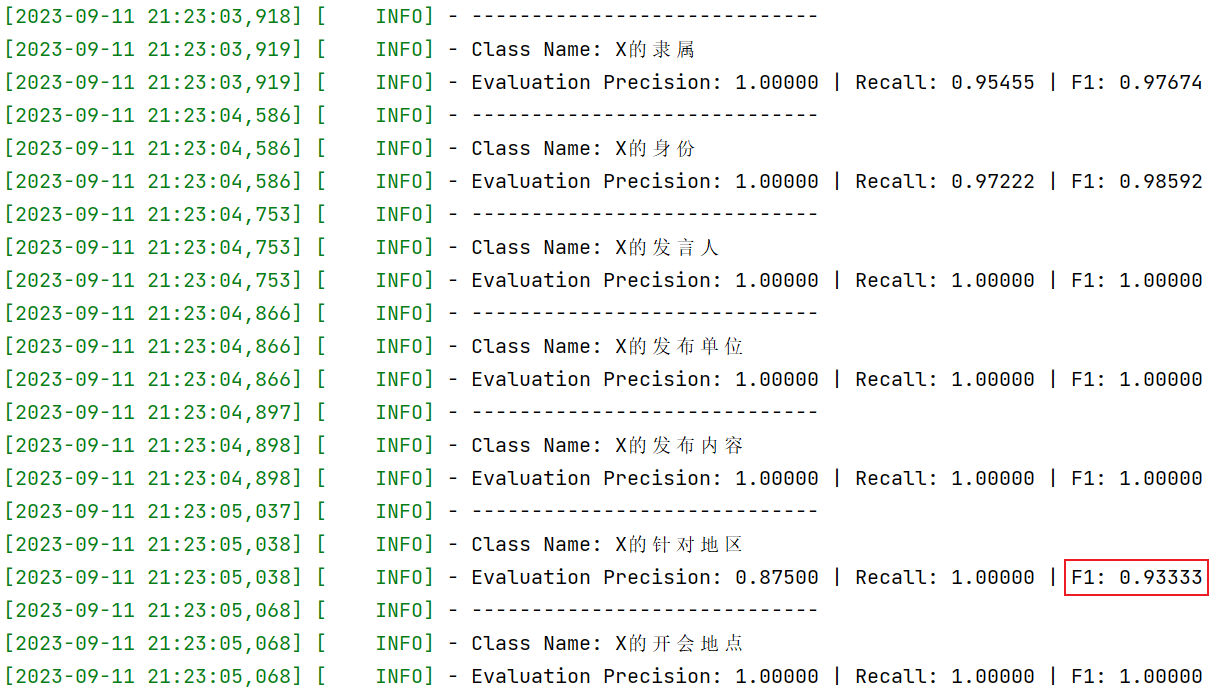
关系提取准确率(指F1Score)仅有1/7个(政策的针对地区)低于95%,其余均高于95%
参数调整请看UIE模型的参数介绍文档:./uie-model/README.md
或者在线版:PaddleNLP/README.md at develop · PaddlePaddle/PaddleNLP (github.com)
有关doccano协同标注平台搭建,AIStudio 使用A100 GPU训练项目可以联系我:ranxi169@163.com
后端api已经打包至docker,具体使用说明请看说明文档:Docker后端使用说明
前端静态网页提供完整直接可部署的文件夹,具体使用说明请看说明文档:nginx前端使用说明