Language Human Annotations, a frontend for tagging AI project labels, drived by pandas dataframe data.
From Chinese word 琅嬛[langhuan] (Legendary realm where god curates books)
Here's a 5 minutes youtube video explaining how langhuan works
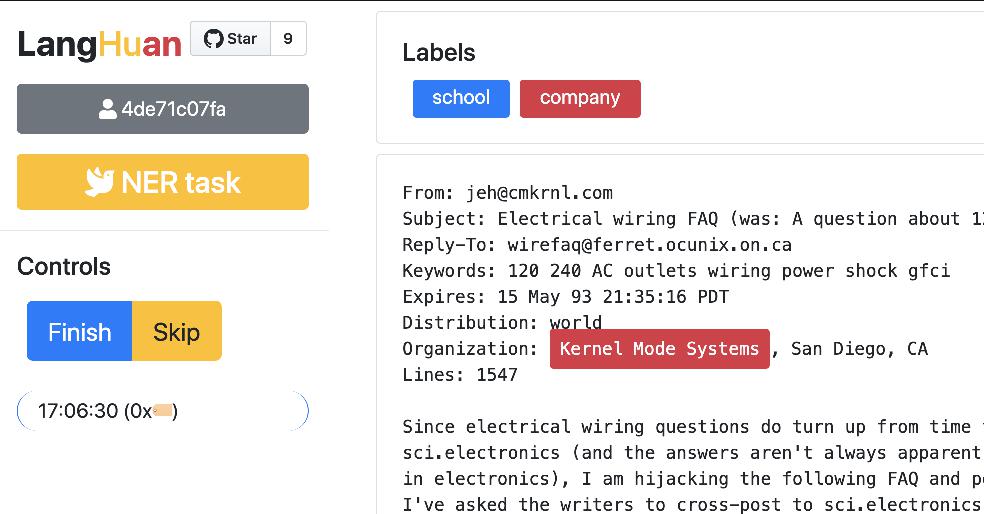
pip install langhuanlanghuan start a flask application from pandas dataframe 🐼 !
from langhuan import NERTask
app = NERTask.from_df(
df, text_col="description",
options=["institution", "company", "name"])
app.run("0.0.0.0", port=5000)from langhuan import ClassifyTask
app = ClassifyTask.from_df(
df, text_col="comment",
options=["positive", "negative", "unbiased", "not sure"])
app.run("0.0.0.0", port=5000)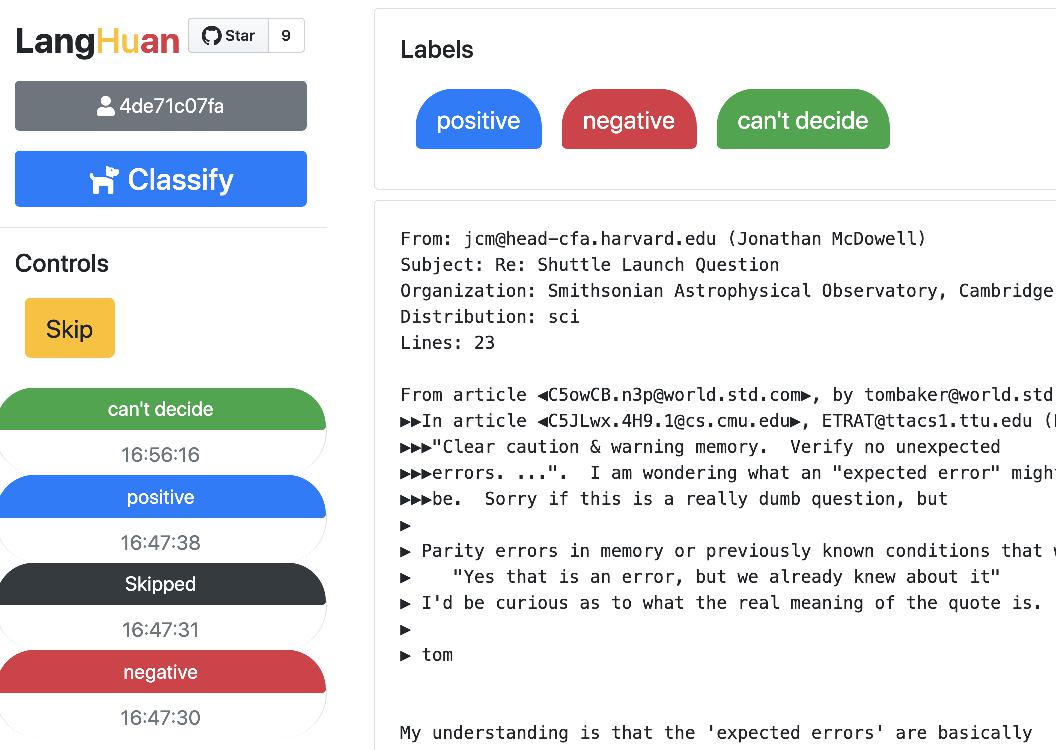
You can visit following pages for this app.
http://[ip]:[port]/ is for our hard working taggers to visit.
http://[ip]:[port]/admin is a page where you can 👮🏽♂️:
- See the progress of each user.
- Force save the progress, (or it will only save according to
save_frequency, default 42 entries) - Download the tagged entries
You can set minimun verification number: cross_verify_num, aka, how each entry will be validated, default is 1
If you set cross_verify_num to 2, and you have 5 taggers, each entry will be seen by 2 taggers
app = ClassifyTask.from_df(
df, text_col="comment",
options=["positive", "negative", "unbiased", "not sure"],
cross_verify_num=2,)You can set a column in dataframe, eg. called guessed_tags, to preset the tagging result.
Each cell can contain the format of tagging result, eg.
{"tags":[
{"text": "Genomicare Bio Tech", "offset":32, "label":"company"},
{"text": "East China University of Politic Science & Law", "offset":96, "label":"company"},
]}Then you can run the app with preset tag column
app = NERTask.from_df(
df, text_col="description",
options=["institution", "company", "name"],
preset_tag_col="guessed_tags")
app.run("0.0.0.0", port=5000)The order of which text got tagged first is according to order_strategy.
Default is set to "forward_match", you can try pincer or trident
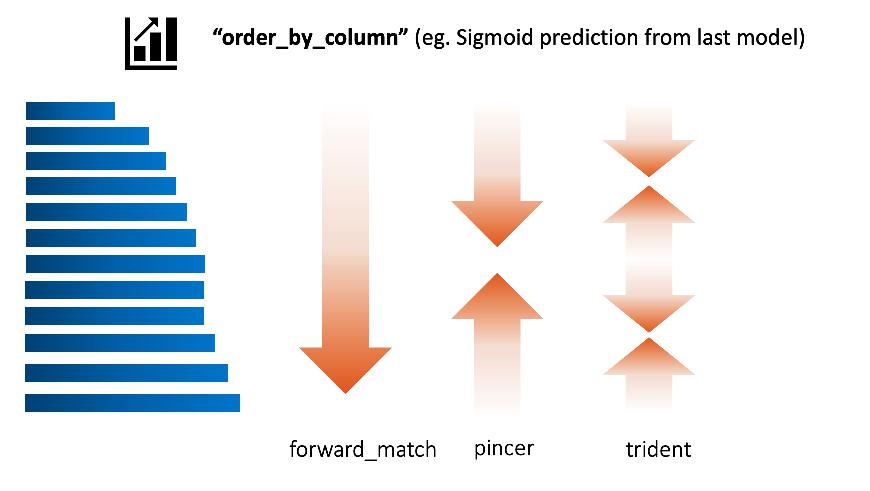
Assume the order_by_column is set to the prediction of last batch of deep learning model:
- trident means the taggers tag the most confident positive, most confident negative, most unsure ones first.
If your service stopped, you can recover the progress from cache.
Previous cache will be at $HOME/.cache/langhuan/{task_name}
You can change the save_frequency to suit your task, default is 42 entries.
app = NERTask.from_df(
df, text_col="description",
options=["institution", "company", "name"],
save_frequency=128,
load_history=True,
task_name="task_NER_210123_110327"
)This application assumes internal use within organization, hence the mininum security. If you set admin_control, all the admin related page will require
adminkey, the key will appear in the console prompt
app = NERTask.from_df(
df, text_col="description",
options=["institution", "company", "name"],
admin_control=True,
)For downloaded NER data tags, you can create a dataloader with the json file automatically:
- pytorch + huggingface tokenizer
- tensorflow + huggingface tokenizer, development pending
This is a light weight solution. When move things to gunicorn, multithreads is acceptable, but multiworkers will cause chaos.
gunicorn --workers=1 --threads=5 app:appWell, this library hasn't been tested vigorously against many browsers with many versions, so far
- compatible with chrome, firefox, safari if version not too old.