This repository contains a reinforcement learning algorithm wherein an agent is crafted with several default rewards (e.g. win, lose, and tie). It is trained by playing itself and then allowing the user to interact using a feature-rich CLI.
This 2-day project was inspired by the classic work by Sutton and Barton (2012) particularly the self-play discussion in exercise 1.1. I also referenced @tansey's repository for clarifying some details of a particular implementation.
Assuming a package manager such as pip, the following dependencies are needed to run the CLI:
pip install urwid urwid_timed_progress tabulate funcy phi pyrsistent numpyTo run, simply call python tic-tac-toe from within the directory.

In case you're a lover of flow charts and sequence diagrams, here's a quick sketch of the program flow from the top-level.

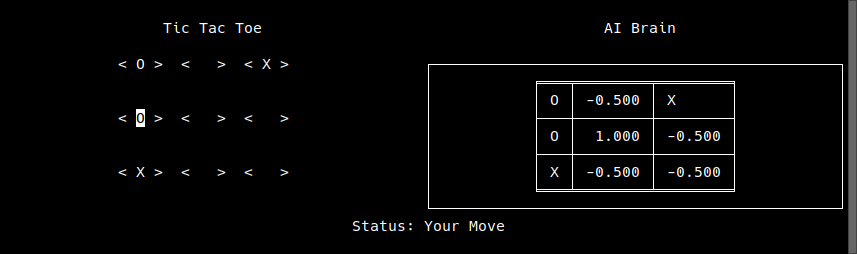
- Why does the "AI Brain" section seem to show the initial values?
Because the values are very close the original values, they appear to be the same. However, if you look at the actual values, they are different. This distinction is important for the AI as it currently chooses the highest reward for
- Where can I get the values that the algorithm produces?
When you run the project, a file is produced called rewards.tsv that includes the weights for the different scenarios encountered during the training process for the agent playing as the X mark.
Sutton, R. S., & Barto, A. G. (2012). Reinforcement learning: an introduction (2nd ed.). Cambridge, MA: The MIT Press.