This scraper is doesn't works anymore.
because `forlap.kemdikbud.go.id` already moved to `https://pddikti.kemdikbud.go.id/`.
Ini adalah Web API dengan teknologi GraphQL untuk menampilkan data kampus yang ada diseluruh Indonesia. Dibuat dengan menggunakan puppeteer untuk scraping data dari website Kementrian RISTEKDIKTI.
Semua hasil data yang ditampilkan berasal dari website KEMENRISTEKDIKTI (Kementerian Riset, Teknologi Dan Pendidikan Tinggi). Tidak menambah, mengubah ataupun menghapus data tanpa ada izin dari pemilik data. Sebaiknya, data ini hanya digunakan untuk keperluan tugas akhir, skripsi, kontribusi di kampus, dan sebagainya. Kami harap data ini tidak digunakan untuk keperluan komersil, jika masih saja menggunakannya untuk komersil, itu diluar tanggung jawab kami.
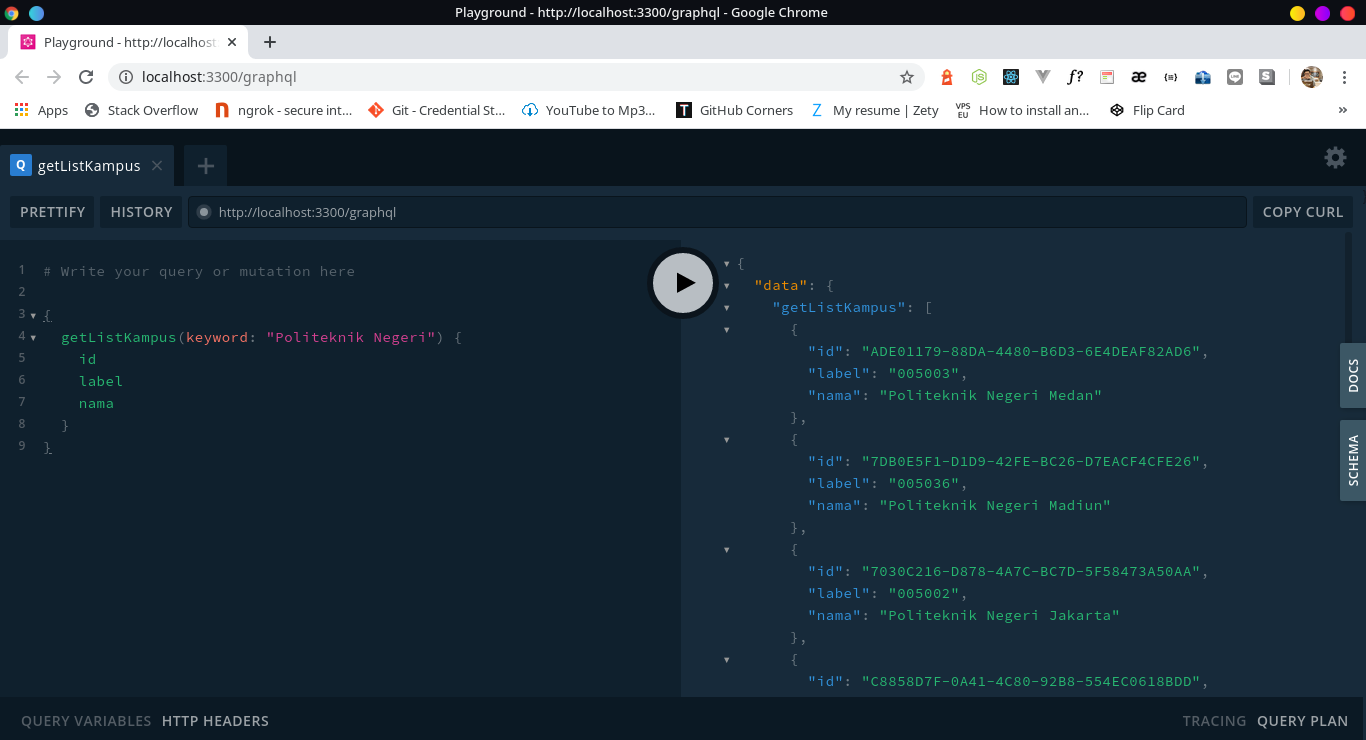
- GET List Kampus berdasarkan keyword
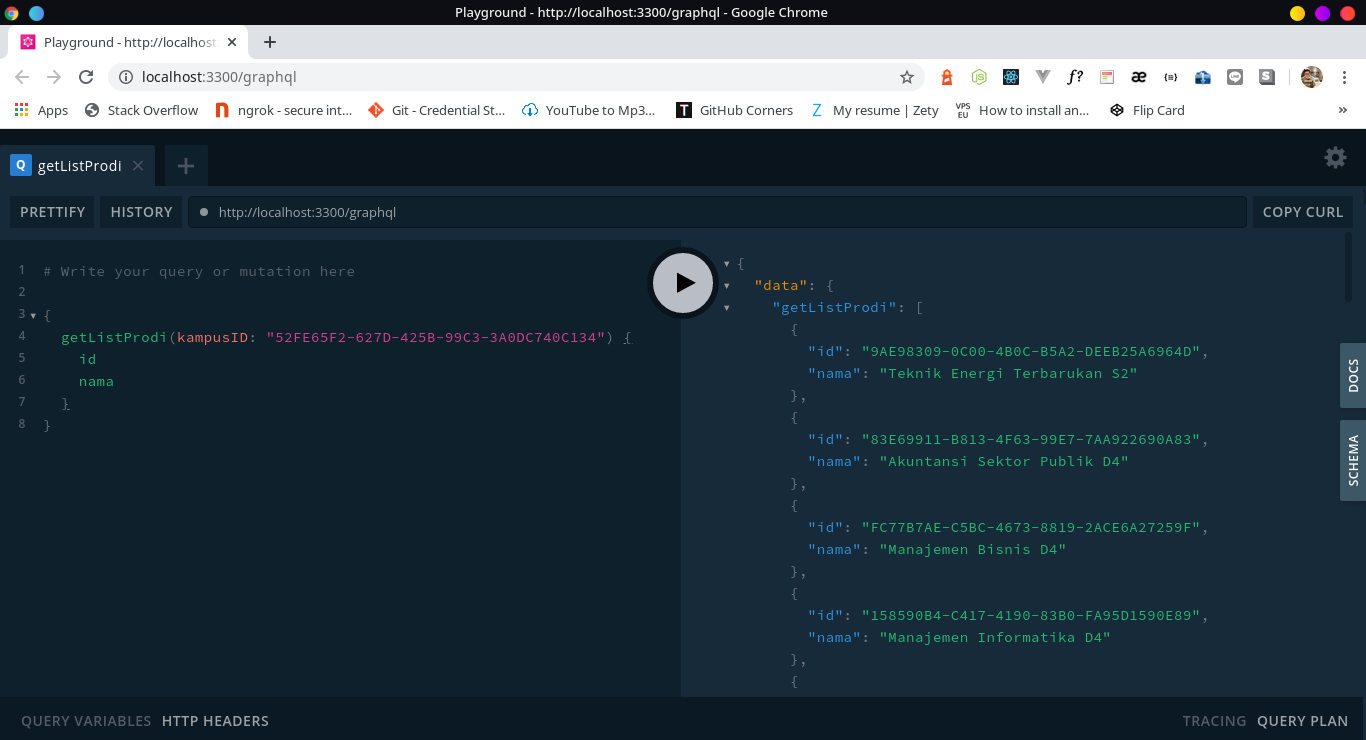
- GET List Prodi berdasarkan ID Kampus
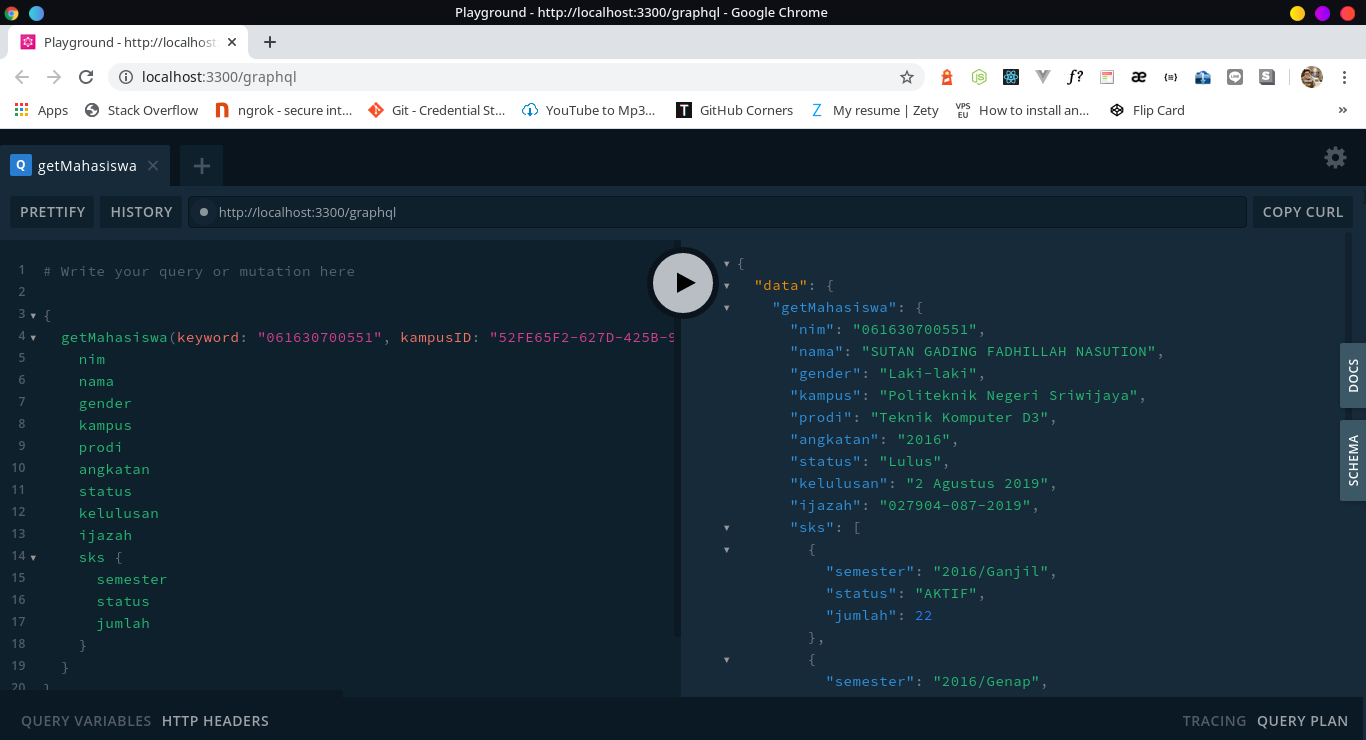
- GET Data Mahasiswa berdasarkan kampus, prodi dan keyword (nama/nim)
- GET Data Dosen berdasarkan kampus, prodi dan keyword (nama/nip/nidn)
- GET List Mahasiswa berdasarkan kampus, prodi dan keyword (nama/nim)
- GET List Dosen berdasarkan kampus, prodi dan keyword (nama/nip/nidn)
- Requestan kamu?
- Fork dan clone repository ini ke komputer kamu.
- Jalankankan
yarn installataunpm installuntuk menginstall semua depedensi yang dibutuhkan. - Buat credentials untuk gsheet di
GCP Console. lebih lengkapnya, baca disini - Copy file
api-secret.example.jsondengan namaapi-secret.json. - Buat 1 file dokumen google spreadsheet, kemudian kasih akses penuh untuk
client_emailyang didapatkan dari credentials tadi. - Copy credentials yang sudah dibuat tadi kedalam
api-secret.json, untuk keyspreadsheet_idbisa ditambahkan sendiri dibawahnya berdasarkan id spreadsheet yang dibawah tadi, contoh pada fileapi-secret.json:
{
"type": "service_account",
"project_id": "xxxx",
"private_key_id": "xxxxx",
....
"spreadsheet_id": "xxxxx"
}
- Terakhir, ketikkan command
yarn startataunpm startuntuk menjalankan server. Ketikkan commandyarn start:devataunpm run start:devuntuk running dalam mode development, hal ini jika ingin melihat browsernya beraksi secara UI, karena kalau hanya commandstartyang dijalankan adalah browserheadlesstanpa UI.
- Untuk OS ubuntu, jika
puppeteer-nya tidak jalan atau error, bisa coba install ini terlebih dahulu.sudo apt install libpangocairo-1.0-0 libx11-xcb1 libxcomposite1 libxcursor1 libxdamage1 libxi6 libxtst6 libnss3 libcups2 libxss1 libxrandr2 libgconf2-4 libasound2 libatk1.0-0 libgtk-3-0 - Jalankan perintah
node src/scraper/mahasiswa.js {kampusID} {batas_halaman} {start_halaman}untuk memulai collecting data dari target kampus. Example (untuk scrape data mahasiswa di kampus POLSRI hanya dari page 1 - 15):node src/scraper/mahasiswa.js 52FE65F2-627D-425B-99C3-3A0DC740C134 15 1. - Parameter
kampusIDbisa didapatkan dari requestgetListKampus(keyword)terlebih dahulu dari server GraphQL yang sudah dijalankan, contohnya bisa dilihat dibagianCara Mengkueri. - Jika mau lihat contoh spreadsheet yang saya buat (sudah collect ratusan ribu mahasiswa UNSRI & POLSRI), atau mau kontak saya secara pribadi di WA karena ada step yg belum paham buat run di local, bisa cek link disini: Karyakarsa: Kampus Scraper

Best Regards, Sutan Gading Fadhillah Nasution.