Welcome to this hands-on repository to get started with Apache Airflow! 🚀
This repository contains a simple Airflow pipeline following an ELT pattern, that can be run in GitHub codespaces (or locally with the Astro CLI). The pipeline will ingest climate data from a csv file, as well local weather data from an API to create interactive visualizations of temperature changes over time.
This is accomplished by using a set of tools in six Airflow DAGs:
- The Astro Python SDK is used for ELT operations.
- DuckDB, a relational database, is used to store tables of the ingested data as well as the resulting tables after transformations.
- Streamlit, a python package to create interactive apps is used to display the data as a dashboard. The streamlit app retrieves its data from tables in DuckDB.
All tools used are open source and no additional accounts are needed.
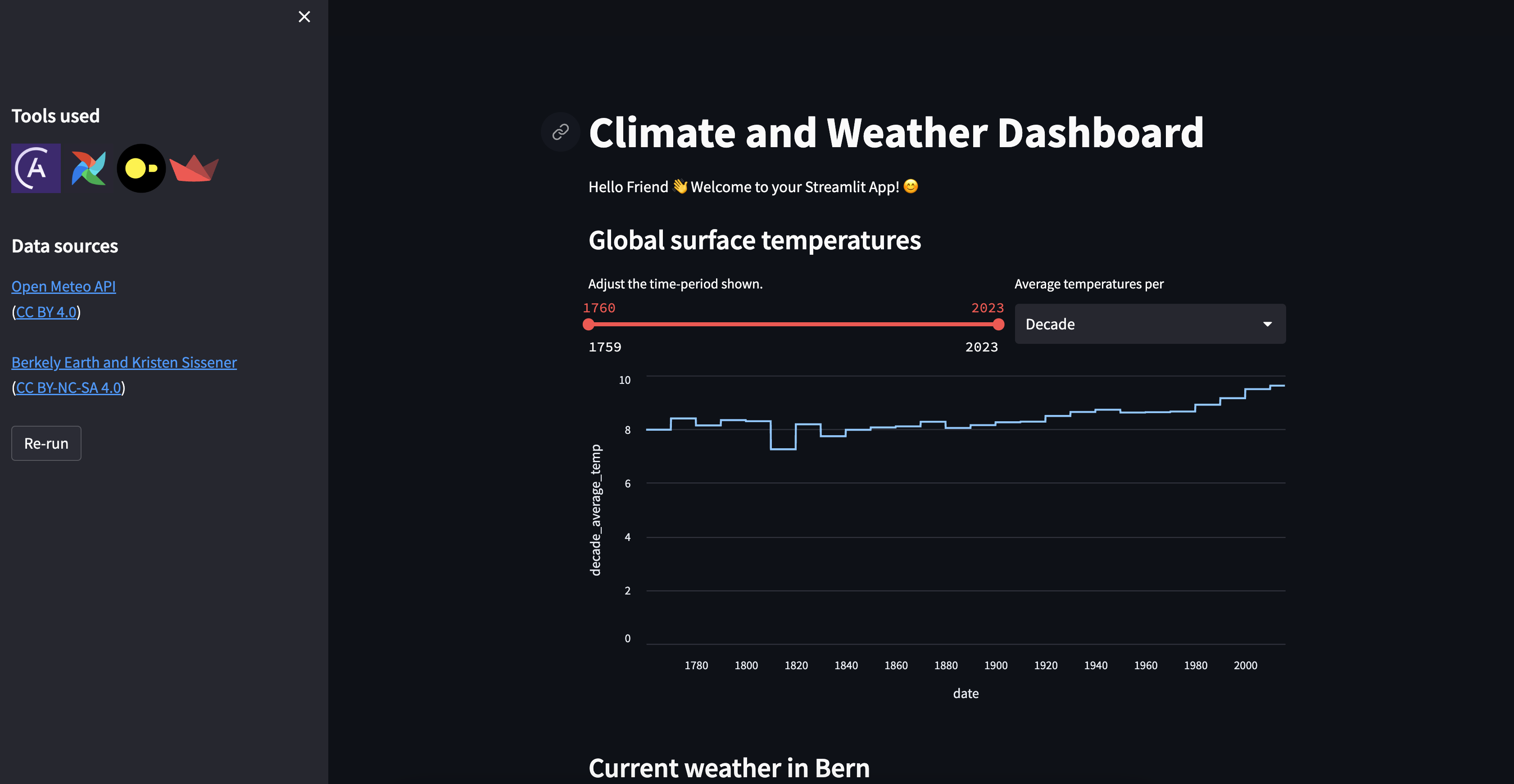
After completing all tasks the streamlit app will look similar to the following screenshots:



Follow the Part 1 Instructions to get started!
The ready to run Airflow pipeline consists of 4 DAGs and will:
- Retrieve the current weather for your city from an API.
- Ingest climate data from a local CSV file.
- Load the data into DuckDB using the Astro SDK.
- Run a transformation on the data using the Astro SDK to create a reporting table powering a Streamlit App.
Follow the Part 2 Instructions to extend the pipeline to show historical weather data for cities of your choice in the Streamlit App. During this process you will learn about Airflow features like Datasets, dynamic task mapping and the Astro Python SDK.
Use this repository to explore Airflow best practices, experiment with your own DAGs and as a template for your own projects!
This project was created with ❤️ by Astronomer.
If you are looking for an entry level written tutorial where you build your own DAG from scratch check out: Get started with Apache Airflow, Part 1: Write and run your first DAG.
Run this Airflow project without installing anything locally.
-
Fork this repository.
-
Create a new GitHub codespaces project on your fork. Make sure it uses at least 4 cores!
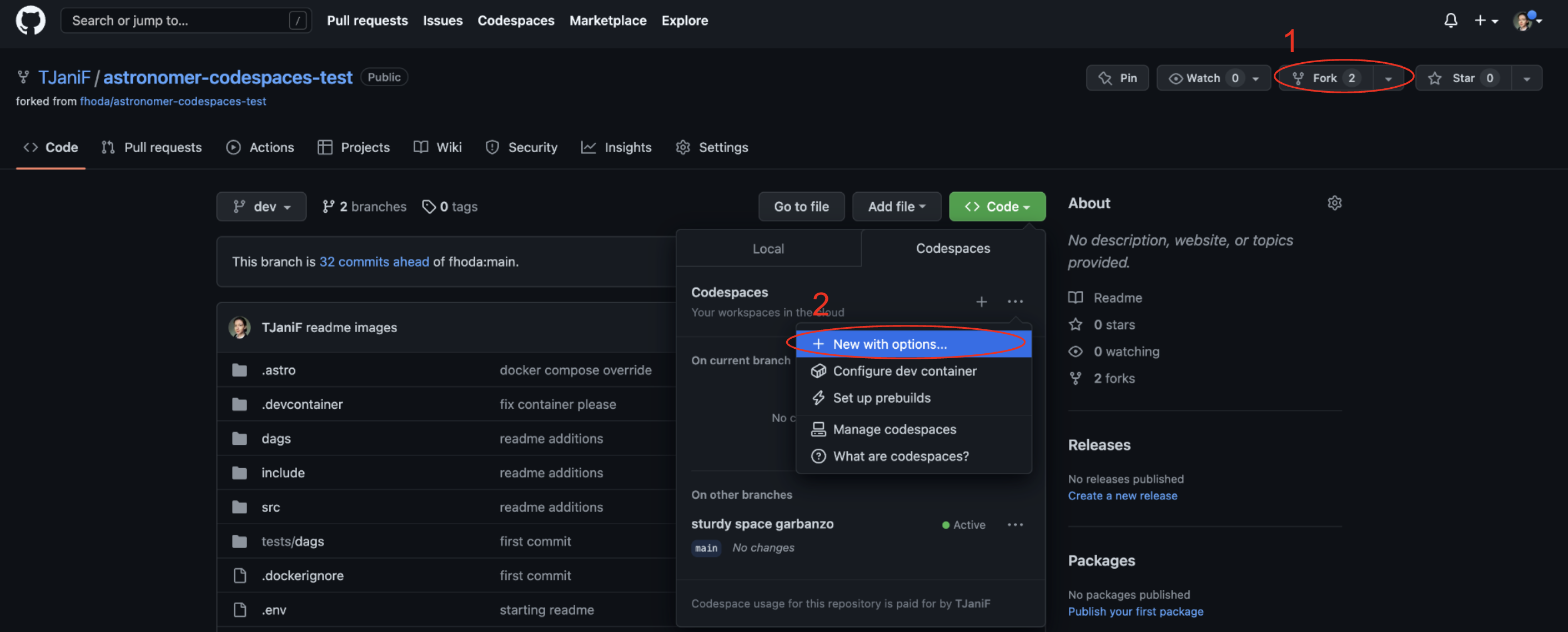
-
After creating the codespaces project the Astro CLI will automatically start up all necessary Airflow components as well as the streamlit app. This can take a few minutes.
-
Once the Airflow project has started access the Airflow UI by clicking on the Ports tab and opening the forward URL for port 8080.
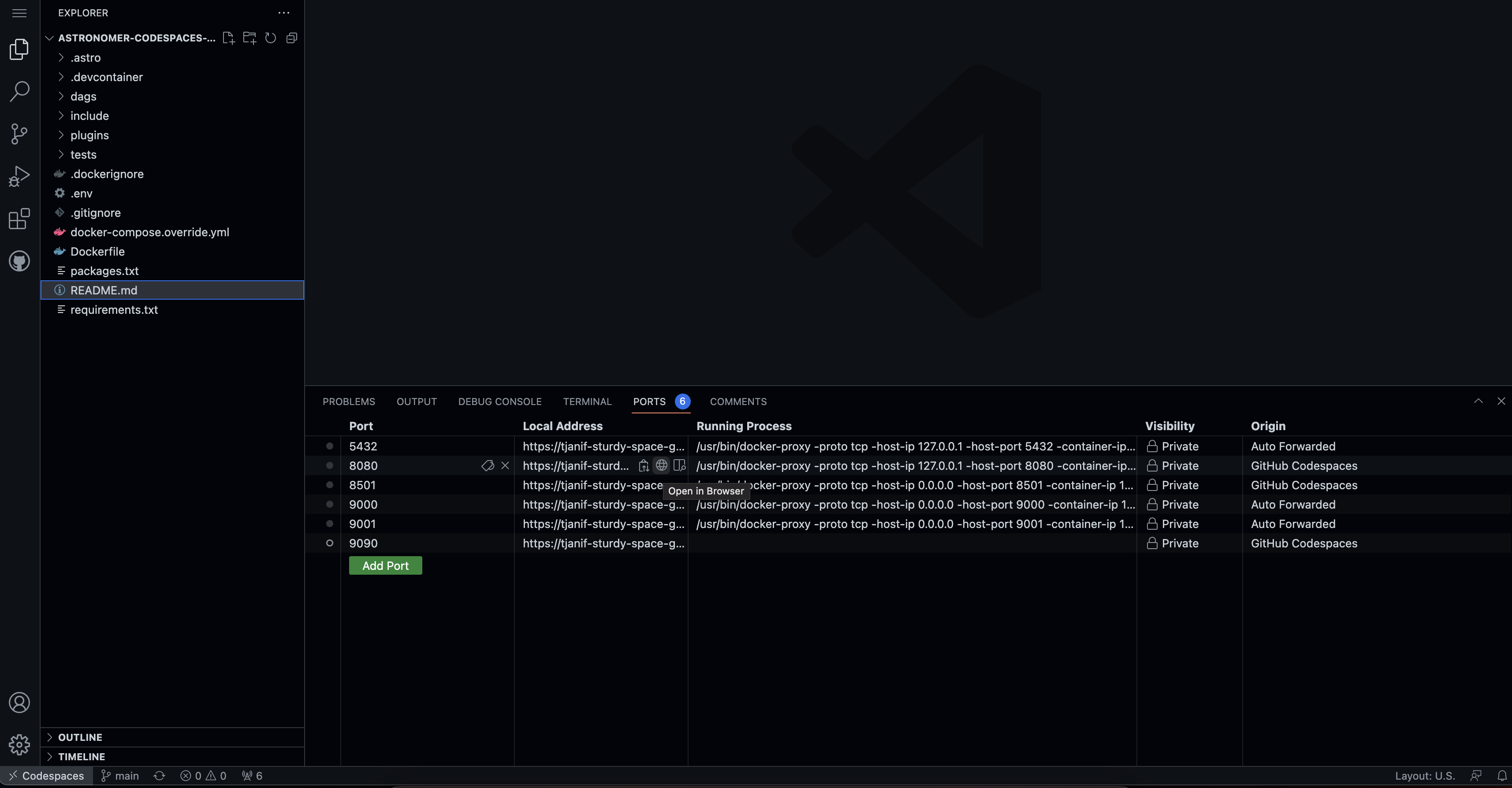
-
Once the streamlit app is running you can access it by by clicking on the Ports tab and opening the forward URL for port 8501.


Download the Astro CLI to run Airflow locally in Docker. astro is the only package you will need to install.
- Run
git clone https://github.com/astronomer/airflow-quickstart.giton your computer to create a local clone of this repository. - Install the Astro CLI by following the steps in the Astro CLI documentation. Docker Desktop/Docker Engine is a prerequisite, but you don't need in-depth Docker knowledge to run Airflow with the Astro CLI.
- Run
astro dev startin your cloned repository. - After your Astro project has started. View the Airflow UI at
localhost:8080. - View the streamlit app at
localhost:8501. NOTE: The streamlit container can take a few minutes to start up.
All DAGs tagged with part_1 are part of a pre-built, fully functional Airflow pipeline. To run them:
-
Go to
include/global_variables/user_input_variables.pyand enter your own info forMY_NAMEandMY_CITY. -
Unpause all DAGs that are tagged with
part_1by clicking on the toggle on their left hand side. Once thestartDAG is unpaused it will run once, starting the pipeline. You can also run this DAG manually to trigger further pipeline runs by clicking on the play button on the right side of the DAG.The DAGs that will run are:
startextract_current_weather_datain_climate_datatransform_climate_data
-
Watch the DAGs run according to their dependencies which have been set using Datasets.
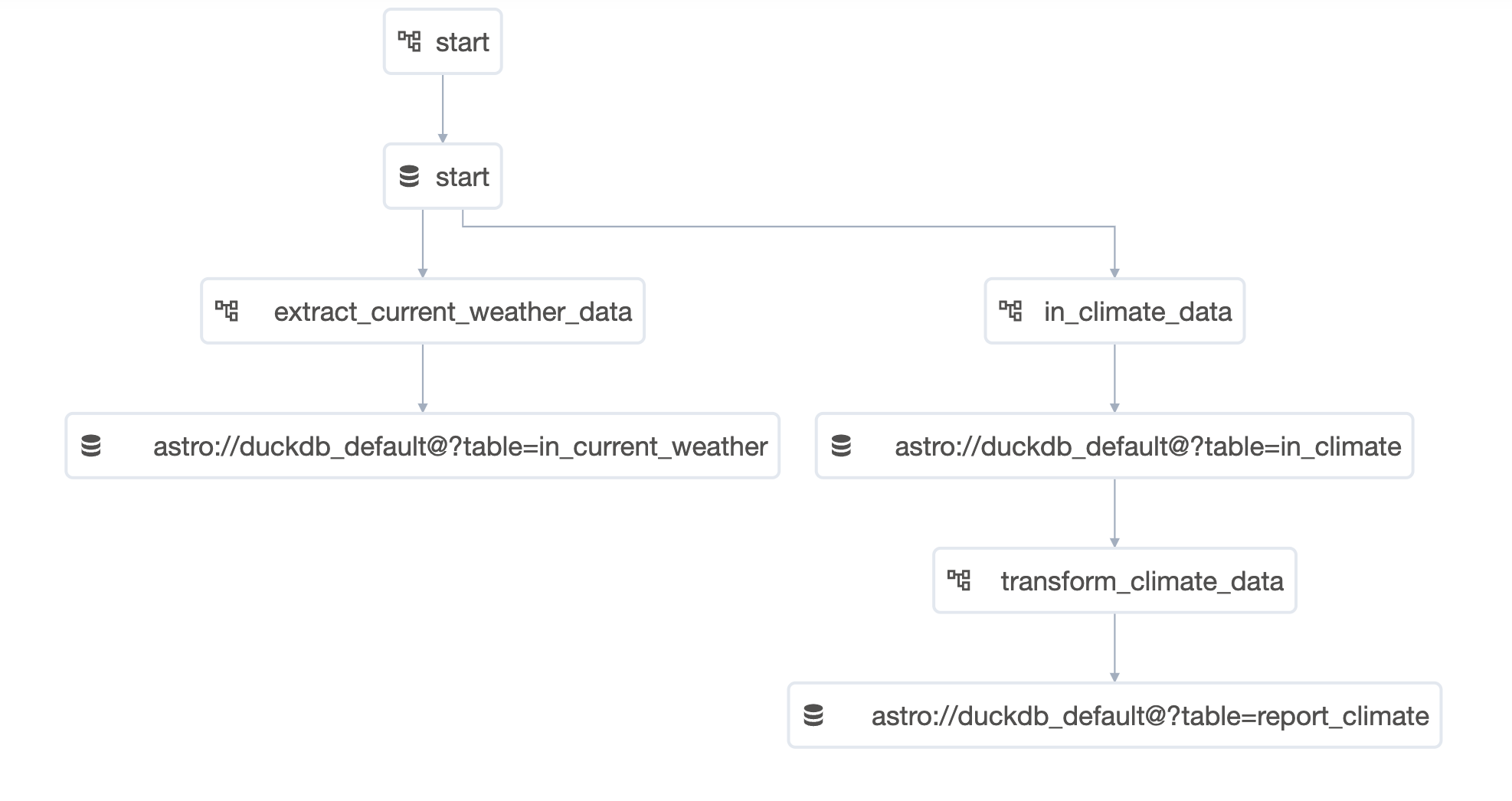
-
Open the Streamlit app. If you are using codespaces go to the Ports tab and open the URL of the forwarded port
8501. If you are running locally go tolocalhost:8501.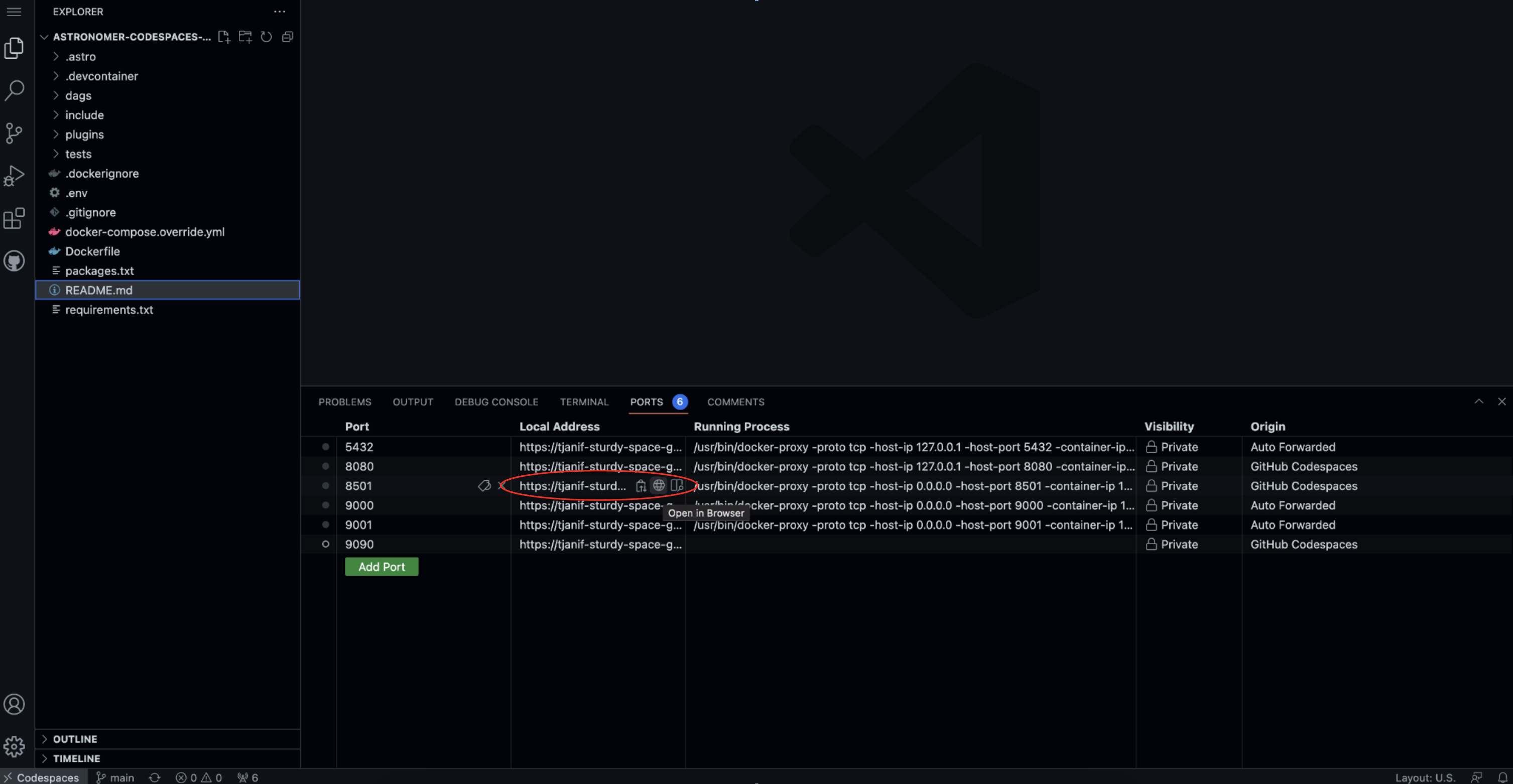
-
View the Streamlit app now showing global climate data and the current weather for your city.



The two DAGs tagged with part_2 are part of a partially built Airflow pipeline that handles historical weather data. You can find example solutions in the solutions_exercises folder.
Before you get started, go to include/global_variables/user_input_variables.py and enter your own info for HOT_DAY and BIRTHYEAR.
Both the extract_historical_weather_data and transform_historical_weather_data DAG currently have their schedule set to None.
Use Datasets to make:
extract_historical_weather_datarun after thestartDAG has finishedtransform_historical_weather_datarun after theextract_historical_weather_dataDAG has finished
You can find information about how to use the Datasets feature in this guide. See also the documentation on how the Astro Python SDK interacts with Datasets.
After running the two DAGs in order, view your streamlit app. You will now see a graph with hot days per year. Additionally parts of the historical weather table will be printed out.

The tasks in the extract_historical_weather_data currently only retrieve historical weather information for one city. Use dynamic task mapping to retrieve information for 3 cities.
You can find instructions on how to use dynamic task mapping in this guide. Tip: You only need to modify two lines of code!
After completing the exercise rerun both extract_historical_weather_data and transform_historical_weather_data.
In your streamlit app you can now select the different cities from the dropdown box to see how many hot days they had per year.

The Astro Python SDK is an open source package built on top of Airflow to provide you with functions and classes that simplify common ELT and ETL operations such as loading files or using SQL or pandas to transform data in a database-agnostic way. View the Astro Python SDK documentation for more information.
The transform_historical_weather_data uses the aql.dataframe decorator to use Pandas to transform data. The table returned by the find_hottest_day_birthyear task will be printed out at the end of your streamlit app. By default no transformation is made to the table in the task, let's change that!
@aql.dataframe(pool="duckdb")
def find_hottest_day_birthyear(in_table: pd.DataFrame, birthyear: int):
# print ingested df to the logs
gv.task_log.info(in_table)
output_df = in_table
####### YOUR TRANSFORMATION ##########
# print result table to the logs
gv.task_log.info(output_df)
return output_dfUse pandas to transform the data shown in in_table to search for the hottest day in your birthyear for each city you retrieved data for.
Tip: Both, the in_table dataframe and the output_df dataframe are printed to the logs of the find_hottest_day_birthyear task. The goal is to have an output like in the screenshot shown below. If your table does not contain information for several cities, make sure you completed exercise 2 correctly.

This repository uses a custom codespaces container to install the Astro CLI. The GH codespaces post creation command will start up the Astro project by running astro dev start.
5 Docker containers will be created and relevant ports will be forwarded:
- The Airflow scheduler
- The Airflow webserver
- The Airflow metastore
- The Airflow triggerer
Additionally when using codespaces, the command to run the streamlit app is automatically run upon starting the environment.
The global climate data in the local CSV file was retrieved from the Climate Change: Earth Surface Temperature Data Kaggle dataset by Berkely Earth and Kristen Sissener which was uploaded under CC BY-NC-SA 4.0.
The current and historical weather data is queried from the Open Meteo API (CC BY 4.0).
This repository contains the following files and folders:
-
.astro: files necessary for Astro CLI commands. -
.devcontainer: the GH codespaces configuration. -
dags: all DAGs in your Airflow environment. Files in this folder will be parsed by the Airflow scheduler when looking for DAGs to add to your environment. You can add your own dagfiles in this folder.climate_and_current_weather: folder for DAGs which are used in part 1extract_and_load: DAGs related to data extraction and loadingextract_current_weather_data.pyin_climate_data.py
transform: DAGs transforming datatransform_climate_data.py
historical_weather: folder for DAGs which are used in part 2extract_and_load: DAGs related to data extraction and loadingextract_historical_weather_data.py
transform: DAGs transforming datatransform_historical_weather.py
-
include: supporting files that will be included in the Airflow environment.climate_data: contains a CSV file with global climate data.global_variables: configuration files.airflow_conf_variables.py: file storing variables needed in several DAGs.constants.py: file storing table names.user_input_variables.py: file with user input variables likeMY_NAMEandMY_CITY.
meterology_utils.py: file containing functions performing calls to the Open Meteo API.streamlit_app.py: file defining the streamlit app.
-
plugins: folder to place Airflow plugins. Empty. -
solutions_exercises: folder for part 2 solutions.solution_extract_historical_weather_data.py: solution version of theextract_historical_weather_dataDAG.solution_transform_historical_weather.py: solution version of thetransform_historical_weatherDAG.
-
src: contains images used in this README. -
tests: folder to place pytests running on DAGs in the Airflow instance. Contains default tests. -
.dockerignore: list of files to ignore for Docker. -
.env: environment variables. Contains the definition for the DuckDB connection. -
.gitignore: list of files to ignore for git. NOTE that.envis not ignored in this project. -
Dockerfile: the Dockerfile using the Astro CLI. -
packages.txt: system-level packages to be installed in the Airflow environment upon building of the Dockerimage. -
README.md: this Readme. -
requirements.txt: python packages to be installed to be used by DAGs upon building of the Dockerimage.