This project aims to create a web service for a model trained using the Azure Machine Learning Python SDK. There will be two models trained, one using scikit-learn's SVC module with hyperparameter tunning and another using Azure AutoML. The model with best accuracy will be then deployed and consumed.
The project will use an Azure ML Workspace, with the Jupyter notebook environment inside Azure itself. This avoids any extra setup and module instalation. There will be 3 main files on the project:
- A Jupyter Notebook with all the AutoML process, including deployment (
automl.ipynb) - A Jupyter Notebook with the Hyperdrive process (
hyperparameter_tuning.ipynb) - A python script for data treatment, as well as the scikit-learn model training (
train.py)
Care was taken for the data to be treated in the same way in both model training. The other files in the repository were created during the process of running the notebooks.
The data used for the training is the UCI Glass Identification dataset used to predict glass type based on various factors. The ID column was removed, since it does not present relevant information and can lead to wrong results.
The dataset has 214 observations. There are 7 types of glasses in the data description, but none of the observations have the type 4 (Non-float processed vehicle windows). The attributes on the data are:
RI: refractive index Na: Sodium Mg: Magnesium Al: Aluminum Si: Silicon K: Potassium Ca: Calcium Ba: Barium Fe: Iron
The data is loaded to Azure using the TabularDatasetFactory.from_delimited_files() method. For the Automated ML run specifically, we have loaded the data as a Tabular dataset, treated it using the clean_data() function inside train.py, then exported it as CSV and registered it as an Azure dataset. This was done to make sure the data would be treated in the same way in both AutoML and Hyperdrive. It's not possible to create an AutoML remote job from an in-memory Pandas dataframe (which is the data type clean_data() returns.
The task will be to predict the type of glass based on the data describing various characteristics of glass.
The data will be accessed directly using the web link found in the UCI database, then treated using the train.py.
The AutoML training is executed with a timeout of one hour and four concurrent iterations. This allows for resource saving and fast development. It used 3 cross-validations for a good assessment of the results. Deep learning was disabled since the dataset isn't too complex and might not bennefit from it.
The accuracy obtained was of 79%, the best model was a VotingEnsemble. The full configuration of the model is as follows:
Pipeline(memory=None,
steps=[('datatransformer',
DataTransformer(enable_dnn=None, enable_feature_sweeping=None,
feature_sweeping_config=None,
feature_sweeping_timeout=None,
featurization_config=None, force_text_dnn=None,
is_cross_validation=None,
is_onnx_compatible=None, logger=None,
observer=None, task=None, working_dir=None)),
('prefittedsoftvotingclassifier',...
min_samples_leaf=0.01,
min_samples_split=0.10368421052631578,
min_weight_fraction_leaf=0.0,
n_estimators=25,
n_jobs=1,
oob_score=False,
random_state=None,
verbose=0,
warm_start=False))],
verbose=False))],
flatten_transform=None,
weights=[0.16666666666666666,
0.16666666666666666,
0.16666666666666666,
0.16666666666666666,
0.16666666666666666,
0.16666666666666666]))],
verbose=False)
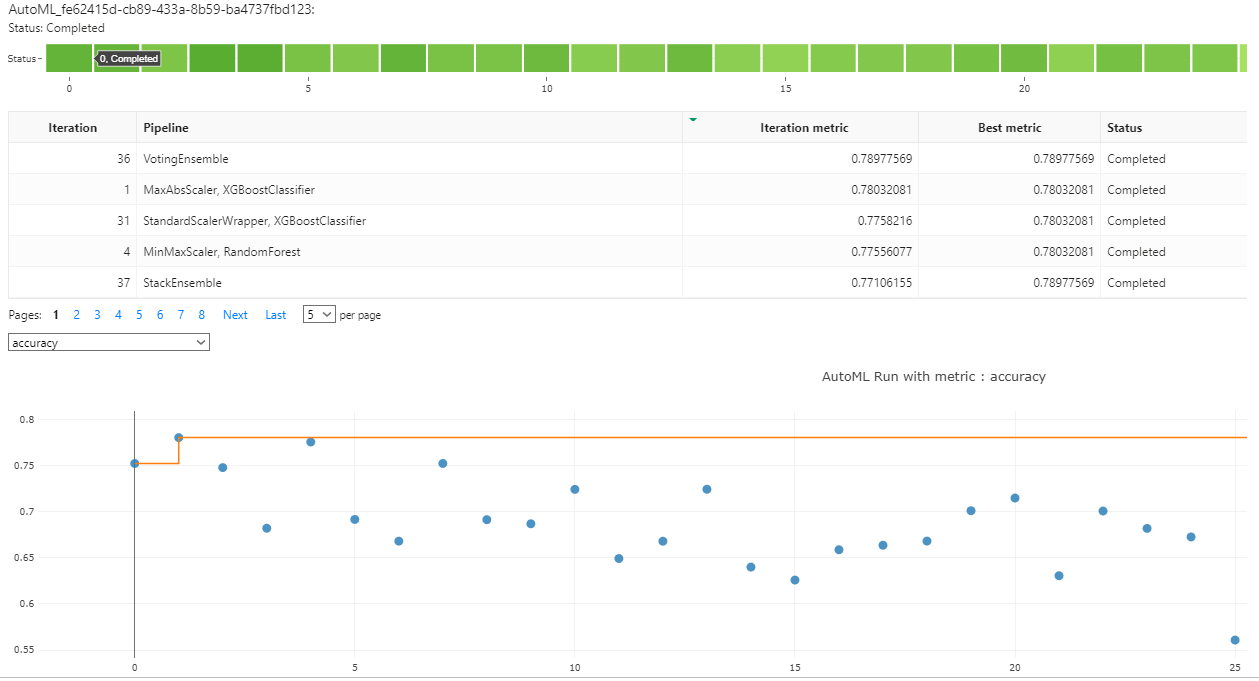
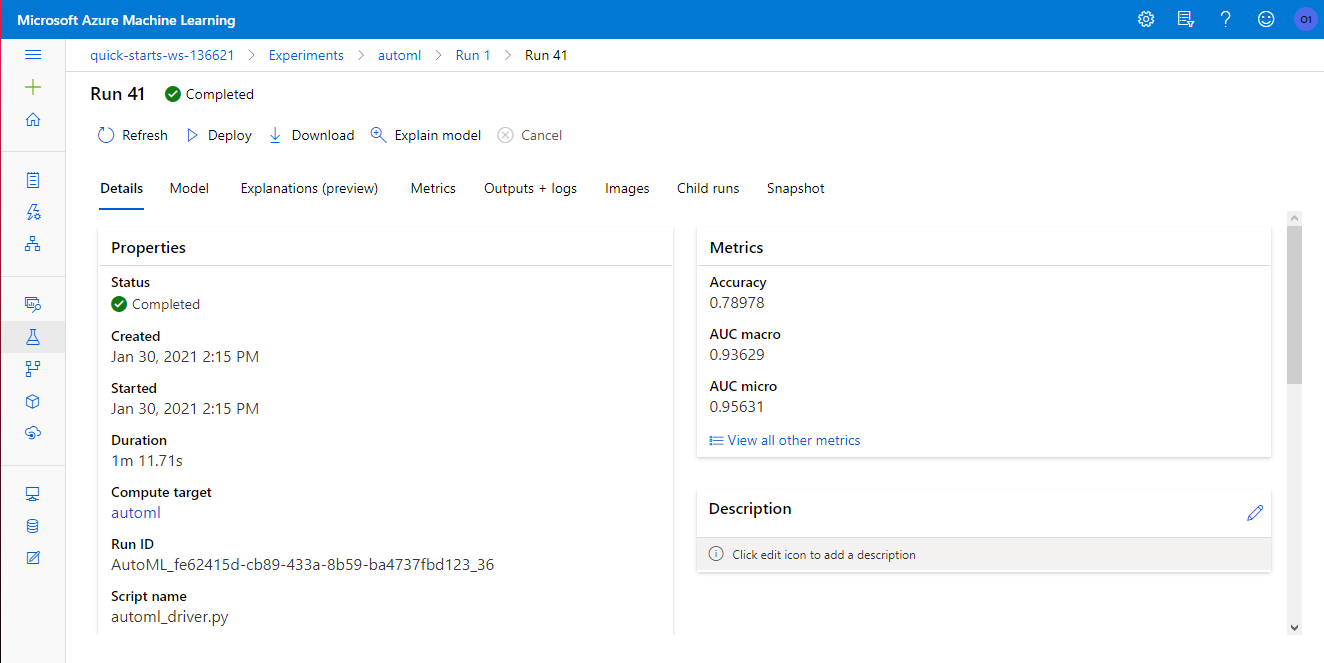
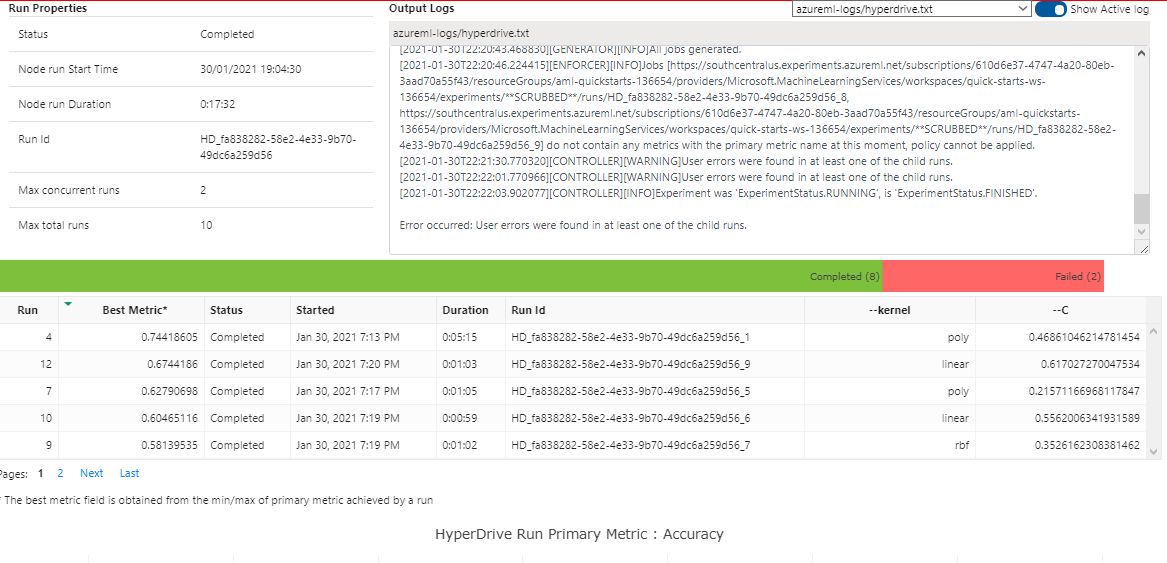
For the hyperparameter tuning we choose scikit-learn's SVC module, the tuned hyperparameters were the kernel type (categorical) and the regularization parameter (a number that goes from 0 to 1).
The accuracy obtained for the model was 74.41%. The kernel chosen for the best run was poly and the regularization parameter for this run was set to 0.46861046214781454.
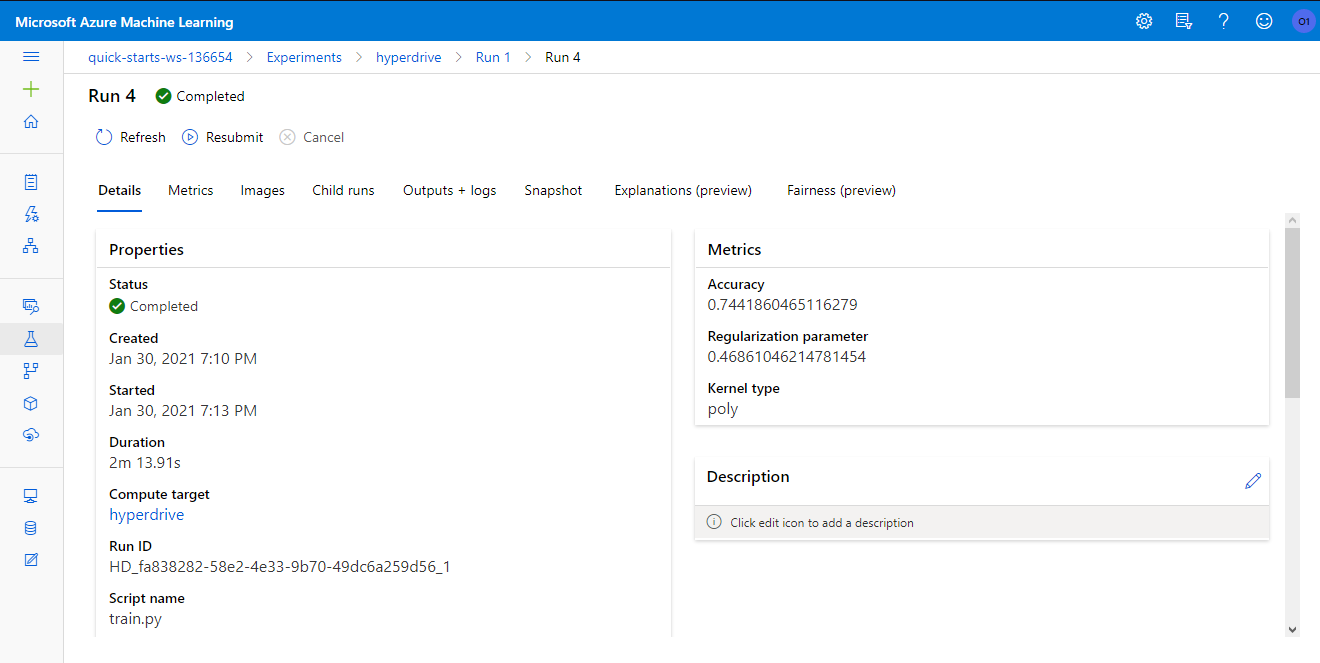
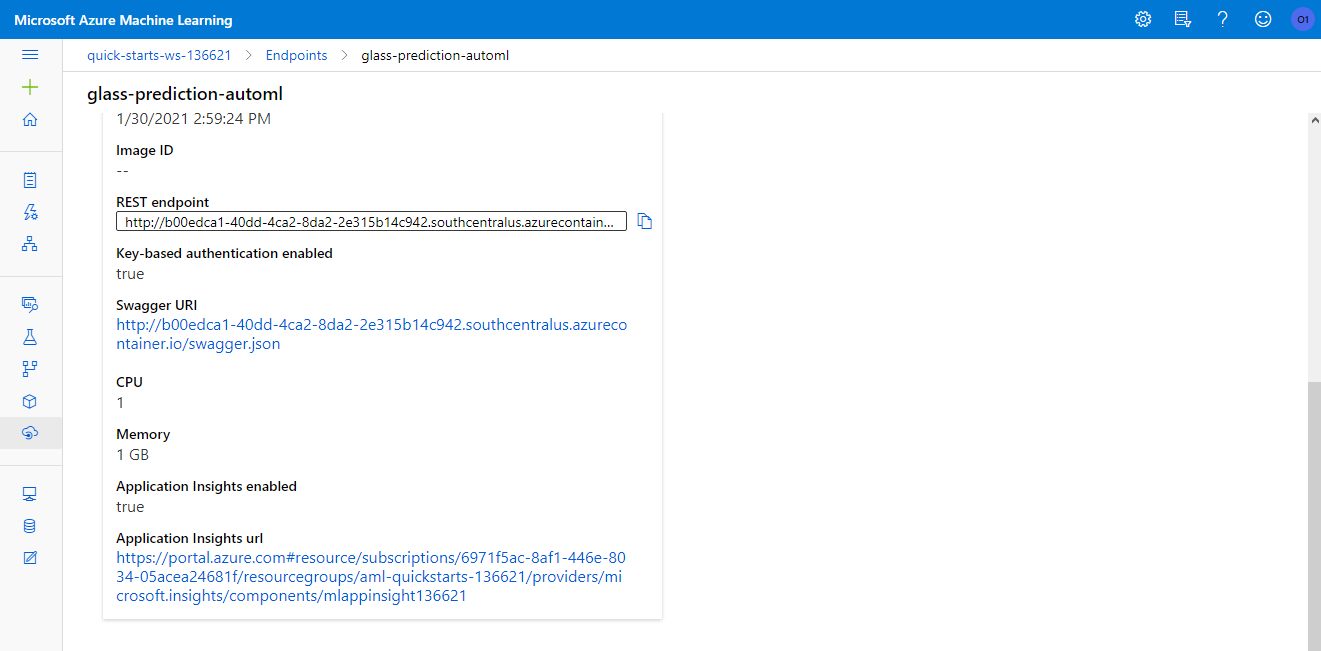
The deployed model was the AutoML model, which obtained better accuracy. The model was deployed to an Azure Container Instance (ACI). The ACI provides a fast deployment ideal for development situations. The deployment was made using authentication and with Application Insights enabled.
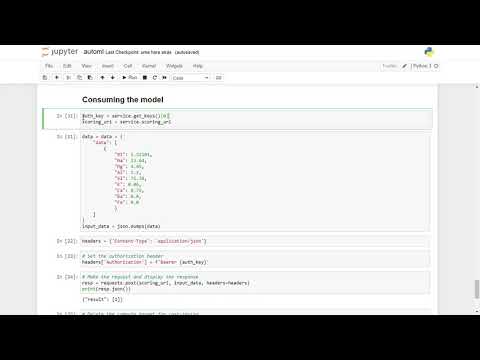
Using the Azure ML Studio we can check the status of our deployed service, as well as get the swagger documentation in a json file, see the web address of the endpoint and authorization keys. For consuming the model inside the notebook, we took all this data from the azureml.core.webservice.aci object itself and used the requests library to execute the call, the code looks like:
# Get the primary authorization key
auth_key = service.get_keys()[0]
# Get the API end point address
scoring_uri = service.scoring_uri
# Setup request headers
headers = {'Content-Type': 'application/json'}
# Set the authorization header
headers['Authorization'] = f'Bearer {auth_key}'
# Make the request and display the response
resp = requests.post(scoring_uri, input_data, headers=headers)
print(resp.json())
The return was {"result": [1]}, which indicates glass type 1. Our model is successfully deployed and working.
The model was deployed with Applications Insights, which enables advanced logging. Application Insights helps identifying errors and fixing them.
For each of the models, there are some experiments that could improve performance:
-
The results of the Automated ML run could probably improve having AutoML run for more time, but for our purposes this is good enough. Deep learning, besides being more resource-intensive, also could get better results.
-
The Hyperdrive run model may be better using Grid sampling instead of Random sampling, but that would take longer (and more computing power) to train.