Assets for Cognos Analytics project
This requires an IBM Cloud Pak for Data cluster, and the following services:
- Watson Discovery
- Db2 Warehouse
- Clone the repo
- Create your services on IBM Cloud Pak for Data
- Configure Watson Discovery
- Configure Db2 Warehouse
- Add service credentials to environment file
- Run scripts to generate data
git clone https://github.com/rhagarty/ca-assets.gitCreate the following services:
- Watson Discovery
- Db2 Warehouse
Use the following instructions for each of the services.
The services are not available by default. An administrator must install them on the IBM Cloud Pak for Data platform, and you must be given access to the service. To determine whether the service is installed, Click the Services icon (![]() ) and check whether the service is enabled.
) and check whether the service is enabled.
Find the Discovery service in your list of Provisioned Instances in your IBM Cloud Pak for Data Dashboard.
Click on View Details from the options menu associated with your Discovery service.

Click on Open Watson Discovery.

Create a new project by clicking the New Project tile.
Give the project a unique name and select the Document Retrieval option, then click Next.
For data source, click on the Upload data tile and click Next.
Enter a unique name for your collection and click Finish.
NOTE: on IBM Cloud Pak for Data, Discovery service queries are defaulted to be performed on all collections within a project. For this reason, it is advised that you create a new project to contain the collection we will be creating for this code pattern.
On the Configure Collection panel, click the Select documents button to select all 1000 json review files located in the data directory of your local repo.
Be patient as this process make take several minutes.
To access the collection, make sure you are in the correct project, then click the Manage Collections tab in the left-side of the panel.

Click the collection tile to access it.

Turn on sentiments.

Click Apply changes and reprocess
Wait for all the of the documents to be reprosessed.
NEED TO ADD
Next, you'll need to add the Watson Discovery and Db2 Warehouse credentials to the .env file.
1. From the home directory of your cloned local repo, create a .env file by copying it from the sample version.
cp env.sample .env-
Create a user to use for authentication. From the IBM Cloud Pak for Data main navigation menu (☰), select
Administer > Manage usersand then+ New user. -
From the main navigation menu (☰), select
My instances. -
On the
Provisioned instancestab, find your service instance, and then hover over the last column to find and click the ellipses icon. ChooseView details. -
Copy the
URLto use as the{SERVICE_NAME}_URLwhen you configure credentials. -
Use the
Menuand selectUsersand+ Add userto grant your user access to this service instance. This is the user name (and password) you will enter into your.envfile.
-
From your Watson Discovery service instance, click on your project.
-
From the main navigation menu (☰), select
Integrate and deploy, and then click on theView API Informationtab.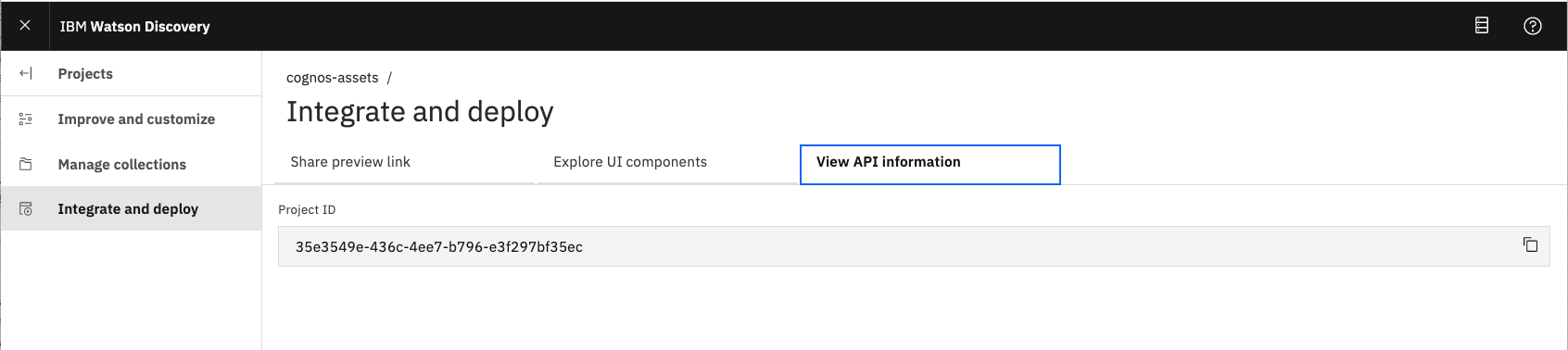
-
Copy the
Project IDto enter into your.envfile.

NEED TO ADD
# Copy this file to .env and replace the credentials with
# your own before starting the app.
# Watson Discovery
DISCOVERY_AUTH_TYPE=cp4d
DISCOVERY_AUTH_URL=https://my-cpd-cluster.ibmcodetest.us
DISCOVERY_USERNAME=my-username
DISCOVERY_PASSWORD=my-password
DISCOVERY_URL=https://my-cpd-cluster.ibmcodetest.us/assistant/assistant/instances/1576274722862/api
# # If you use a self-signed certificate, you need to disable SSL verification.
# # This is not secure and not recommended.
#DISCOVERY_AUTH_DISABLE_SSL=true
#DISCOVERY_DISABLE_SSL=true
DISCOVERY_PROJECT_ID=<add_project_id>
# Db2 Warehouse access
DB2WH_DSN='<add_db2_warehouse_instance'
# Optional settings
WRITE_TO_CSV_FILE=true
WRITE_TO_DB=trueThe provided scripts can be used to generate sample data for a facticious company, Named "Golden Cereals". The company offers 10 types of cereal, which is sold in grocery stores. Product inventory is stored in multiple warehouses, which the company continuosly stocks.
The scripts build the following data, which will be output to local .csv files, and also to Db2 Warehouse tables.
- Reviews - this contains all of the reviews for each of the products. Includes rating and sentiment score.
- Products - this is information about each of our products. Includes product_id, name, and unit price.
- Stores - this is information about each of our stores. Includes store_id and location.
- Sales - this is the sales data from each of the stores. Includes store_id, product_id, data, and amount of items sold.
- Orders - this is orders generated by our stores. Includes store_id, product_id, date, and number of items.
- Warehouses - this is information about each of our warehouses, which are used to supply our stores with product. Includes warehouse_id, the amout of each product, and the amount of product that comes in on a monthly basis.
Flow:
Golden Cerealsstocks it's warehouses with products- Stores orders the products and sells to customers
- Stores make additional orders as more products are sold
Golden Cerealsfulfills store orders by shipping products from their warehousesGolden Cerealsre-stocks the warehouses as inventory drops
To run the script you will need to install Node.js, an open-source JavaScript run-time environment for executing server-side JavaScript code.
cd ca-assets/scripts
node GenerateAndSaveDataOutside of the scripts used to build the product and sales data listed above, there are additonal scripts which were used to generate product review data. The end result of the scripts is the generation of 1000 food review json files that can be loaded into Watson Discovery (see Step #3). Since we have included the 1000 json files in this repo, there is no need to run the scripts again, but it is worth discussing how they work.
- Download Amazon food review data from Kaggle.
- Save as local file
data/Reviews-full.csv. - Process all reviews and log the number of reviews per product, along with how useful each review is based on
helpfullness factor. - Print out the list of products in order of useful reviews.
- Use the top 10 reviews determined by
csv-find-product-with-most-reviews. - Cut and paste the product ID of the top 10 products.
- Add a more user-readable product ID for each.
- Process all reviews in
data/Reviews-full.csv, and only process the top 100 useful reviews for the products we have identified. - Create a json file for each review and store it in the
data/food_reviewsdirectory.
Note: The actual review dates were spread out from 2008-20017. In order to make the data more relevant to our needs, we modified all dates to be in 2019.
TO BE ADDED
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.