TL;DR Dotted Version Vector Sets are similar to Version Vectors (Vector Clocks for some), but prevent false conflicts that can occur with Version Vectors. It also has a more complete API and is better suited to distributed databases with a get/put interface (as shown below).
- Intro
- Why not Version Vectors (Vector Clocks)?
- The Solution: Dotted Version Vector Sets
- Real World with Riak
- How to Use
- Variations:
{ ... } is a set (no order or duplicates)
[ ... ] is a list (like an array, has order)
( ... ) is a n-tuple (pair, triples, etc.)
We are presenting the compact version of the original Dotted Version Vectors(DVV), which we call Dotted Version Vector Sets (DVVSet). Like its predecessor, DVVSet still accurately describes causality between related or conflicting values (values that reflect concurrent updates and that must be all kept until a future reconciliation supersedes them), but now with a smaller representation, very similar to Version Vectors in size.
Lets assume the scenario of a Distributed Key-Value Store (Ex: Riak, Cassandra, etc), where we have clients, servers and we can write ( PUT ) and read ( GET ) values. We also want to track the causality information of these values, so that causally descendant values replace older values and causally concurrent values are all kept (for further reconciliation).
We can use DVVSet to keep the values and their causal history together, with support for multiple conflicting values (siblings). One DVVSet has 1 value (a single sibling) if there are no conflicts. Otherwise, it stores all siblings and their relevant causal information in a single DVVSet. Thus, this data structure encapsulates the tracking, maintaining and reasoning about the values' causality.
First, Version Vectors are not Vector Clocks; both have similar structure but different semantics. In our context, the relevant mechanism is Version Vectors (VV).
Every key/value has an associated VV and sometimes conflicts arise, because values for the same key can reflect concurrent updates and thus have conflicting VVs (there isn't a single VV that dominates all others). Considering that we want to keep all conflicting values until something (a conflict resolution algorithm) or someone (the user) decides how to reconcile, the question is: How do we represent conflicts in the server?
There are two different approaches when using VV or similar causality tracking mechanisms: use Server IDs (SI) or use Client IDs (CI).
VV need identifiers to track the entities responsible for the events. We can either make the servers responsible for events to a value (SI), or we can make clients responsible (CI).
A false conflict occurs when a set of values contains values that should be discard, if the causality were correctly preserved, as they are related in a causal evolution chain and do not contain concurrent updates. VVs with CI don't have false conflicts like VVs with SI. However, they don't scale well. On the other hand, VV with SI scale, but don't have a good support for the identification of conflicting values.
Lets illustrate the different VV approaches to track events in a simple client/server interaction.
Using VV with CI, you don't have any problem representing conflicts in the server, because each write is associated with the client that did it (one has as many IDs as the potential sources of concurrent writes). We can see that v3 correctly superseded v1, thus no false conflict occurred.

Problem: If 1000 different clients write to a key/value, its VV will have
1000 (client_id, counter) entries. We could prune older entries when a limit
is reached, to bound growth and improve scalability, but it would introduce
false conflict problems (showing causally related values as concurrent).
Additionally, the same client could write to different servers and, if R/W
quorum setup do not ensure read-your-writes session guaranties, each could end
up with the same VV, although depicting different writes. We could combine the
identifier to be a pair client_id/server_id, but that would actually worsen
the VV growth problem even more.
Using SI, you could keep both VVs when conflicts occur, but you would consume more space. More importantly, VV are not sufficient to represent conflicts created by two "concurrent writes".

Problem: As we can see, there is no way for VV-SI to represent two conflicting values, since we can only increment the VV with the server id: if we use (A,1) for both, we are saying that they are causally equal, which is not true; using (A,2) implies that v2 is causally newer than v1, which is also not true. If we assume (A,1) for both values v1 and v2, we then have an additional problem where the behavior is undefined or incorrect: in the 3rd write, we receive a value that read v1 ~ (A,1), so it should conflict with v2 and overwrite v1; however, when writing v2, we did not increment its VV to (A,2), thus the new write v3 wins over (A,1) and overwrites both v1 and v2.
A possible solution could be to use some metadata to tell us where the values came from and how to deal with conflicting values, but it would not be straightforward and would be full of corner cases and prone to bugs. We should not put the burden on the developer to implement proper causal behavior for conflicting values on top of VV.
Another solution is to keep both values and merge their VV into one, which saves space when compared to the previous approach. If a new write conflicts with an existing VV, then merge both VV and increment it normally using the server id. Both values are now related to this new merged VV.

Problem: We lose the information that v1 was associated with (A,1) and not (A,2). In the third write we can see how this approach could lead to false conflicts. v3 is being written with (A,1), therefore we know that it should win over v1 and conflict with v2, but since we lost information about the causal past of v1, the server has no other option but to keep all three values and merge the VV again. Now the problem is even worse, since we are saying that all three values are related to (A,3). It's easy to see that this could lead to undesired behavior and an explosion of false conflicts.
The problems described above are the reasons that made us develop the original Dotted Version Vectors (DVV) in the first place. It uses Server Ids but without the problems stated above, and allowing precise causality tracking. Lets give a brief explanation about DVV.
A VV is a set of pairs (id, counter). The value of counter means that we
know all events done by id until counter. Thus, if counter is 3, we know
about events #1, #2 and #3, done by that id.
The novelty of DVV is to provide the context where the last event happened. To
do that, we separate the last event from the VV itself. This last event is what
we call the Dot (hence Dotted Version Vectors). It's a pair (id, counter) and only represents the event of that exact counter and not previous
events; the (A, 3) Dot only represents the event 3 by A, and nothing else
(like event 1 and 2 by A). Thus, this Dot allows the representation of non-
contiguous set of events, for each sibling. Using this, we can solve our
previous problem:

On the first write, since v1 had no causal context, the VV in the DVV is also
empty. The Dot captures the last event, which in this case, is (A,1). When
v2 is written, it also doesn't have causal history, so the DVV also has a
empty VV, but with the Dot (A,2), since its the second event recorded by A for
this key. Both values coexist without confusion and preserve their context.
Finally, when v3 arrives with the context (A,1), we know that it already
read v1, thus it can be safely discarded. We keep v2 because it has events
(updates) that v3 does not know. The DVV for v3 is the VV given by the
client, and the Dot is the next available event by A : (A,3).
We have solved this problem by allowing values to have non-contiguous set of causal events (however, all DVVs combined should have a set of contiguous events).
For more information about VV/SI vs VV/CI vs DVV see this article: Dotted Version Vectors: Efficient Causality Tracking for Distributed Key-Value Stores).
Dotted Version Vector Sets (DVVSet) solves the exact same problems as DVV, but is much more concise and simple. Instead of having a DVV of each sibling, lets combine all the causal information in the DVVs into a single VV, while retaining the Dots information.
We really only want two different things from a causality mechanism: (1) assign new causal events to new siblings, and (2) remove outdated siblings. To have (1) we only need one causal event per sibling (the Dot), and for (2) we only need to know which causal events we already know (a global VV), since it doesn't matter which sibling obsoletes another one, the end result is the same; thus, we can lose the information of the specific causal context of each sibling and store only the aggregate of that information.
Now, instead of:
v2 ~ ([],(A,2))
v3 ~ ([(A,1)],(A,3))

like the last result in our previous example, we have:
v2 ~ (A,2)
v3 ~ (A,3)
global ~ (A,1)

So, we have 2 Dots and a global VV. Taking it a step further, we can use implicit value placement to represent the Dots like so:
(A,1,[v2,v3])

meaning that (A,1) is the global VV and [v2,v3] are the Dots. They are
constructed using the id of the triplet they're in, and each counter is
obtained by their position in the list. v2 is the first
element, so we add 1 to the global VV and have the Dot (A,2). v3 is second
element, so we add 2 to the global VV and have the Dot (A,3).
Well, actually, for implementation purposes, it is more practical to have the VV as the whole set of events and the list of values reversed. Our example becomes:
(A,3,[v3,v2])

where each Dot is the zero-based index position in the list, minus the counter
of the VV. Thus, v3 ~ (A,3-0) and v2 ~ (A,3-1), the same as before.
Recapping, a DVVSet is a set of triplets (ID, Counter, Values): ID is a
unique server identifier; Counter is a regular monotonically increasing
counter, starting at 1 for the first event; Values is an ordered list of
values, where new values are added to the head. Considering the triplet (I, C, V), the Dot for each value in V at position i is (I, C-i) (V is zero-based
index).
Now, let's see how DVVSet would manage in our previous example:

We have a compact representation like the approach based on VV with SI #2, while preserving sufficient per value causality information to infer that v1 could be discard, since it can detect that the 3rd write already knows the causal information associated with v1, and thus can replace it.
We actually simplified the DVVSet structure a bit for explanation purposes. The complete DVVSet is a list of triplets (ID, Counter, Values) like before, with an additional set of values. We call this the Anonymous List (AL), because it stores values that are not associated any Dot, but is instead related to the global VV. Thus, the only way to supersede values in the AL, is to dominate the global VV.
If you pay attention, having values in the AL is exactly like having a normal VV. This makes the conversion from a DB with VV to DVVSets painless, since we can gradually and deterministically transform them with every new write, avoiding the need have an offline rewrite of every key.
As an example, the VV [(A,2), (B,3)] associated with siblings {v4,v6} can be
represented by this DVVSet ([(A,2,[]), (B,3,[])], {v4,v6}).
Sometimes need the flexibility of saying that a value does not have a Dot, like when we simplify siblings into a single value. For example, applying a deterministic conflict resolution algorithm, like the reconciliations captured in Conflict Free Replicated Data Types (CRDTs).
reconcile is a function that receives a DVVSet and another function. The
latter takes a list of values and returns a new value (the winner). The result
can be a completely new value (one that was not created directly by a client
event), thus we don't advance the causal history, and instead store it in the
AL. We also don't store the winner in a preexistent Dot, since writes that read
the pre-reconciled DVVSet would supersede the new value.
Also, the function that returns the new value should be deterministic! If
not, we can have incoherent DVVSets. For example, applying reconcile with a
non-deterministic function to two replicas could yield two different values with
the same causal history. This is dangerous and is a similar situation to VV with
SI #1, where we keep equal VVs for different values.
Here is an (Erlang) example using reconcile:
F = fun (L) -> lists:sum(L) end,
DVVSet = {[{a,4,[5,2]}, {b,1,[]}], [10,1]},
Res = dvvset:reconcile(F, DVVSet),
{[{a,4,[]}, {b,1,[]}], [18]} = Res.We pass a function to reconcile that adds all values. The returning DVVSet has
the same causal information, but now has only one value (18), which was not
present in the previous DVVSet.
There is a special case of reconcile, named last-write-wins (lww), where we
also want to reduce all values to a single one, but that value must be already
present in the DVVSet. Thus, we let the winning value stay in the same Dot as
before. This function named lww has the same parameters as reconcile, but
the function it receives is a less or equal ordering function.
Thus, this Fun(A,B) returns true if A compares less than or equal to B,
false otherwise. Using that, we keep the greatest value (note: we
preemptively discard values besides the first Dot in each triplet).
Here is an (Erlang) example of using lww in a DVVSet with values types
{Value, Timestamp}:
Fun = fun ({_,TS1}, {_,TS2}) -> TS1 =< TS2 end,
DVVSet = {[{a,4,[{5, 1002345}, {7, 1002340}]}, {b,1,[{4, 1001340}]}], [{2, 1001140}]},
Res = dvvset:lww(Fun, DVVSet),
{[{a,4,[{5, 1002345}]}, {b,1,[]}], []} = Res.We define a less or equal function for our type of values and use it in lww.
It returns a DVVSet with the same causal information, but only with the
greatest value remaining. Naturally, in this case it's {5, 1002345}, which has
the highest timestamp. Notice how the winning value stays in its original
triplet instead of going to the AL, unlike reconcile.

When a client wants to read a key/value, we extract the global causal
information (a VV) from DVVSet using a function called join. Then, we
extract all values using the function values. The VV should be treated as an
opaque object that should be returned in a subsequent write. In the example,
join gives the VV (A,3) and values gives the list of values [v2,v3].

When a client wants to write to a key/value, he gives a value and a VV. We first
create a new DVVSet to represent the new write, using new. It returns a DVVSet
with the same causal information as the VV and the new value in the AL. Then, we
call a function update on that new DVVSet and the server's DVVSet. It
synchronizes both, discarding old values. In this case, v1 is outdated because
the client VV already knows (A,1), therefore we discard it. After this, we
advance the causal information in DVVSet and insert a new Dot to reflect the new
event. In the example, we advance the VV from (A,2) to (A,3) and create a
Dot for v3.
We implemented DVVSet in our fork of Basho's Riak NoSQL database, as an alternative to their VV implementation, as a proof of concept.
The Riak version using VV is here, and the DVVset is here. Or see a diff here.
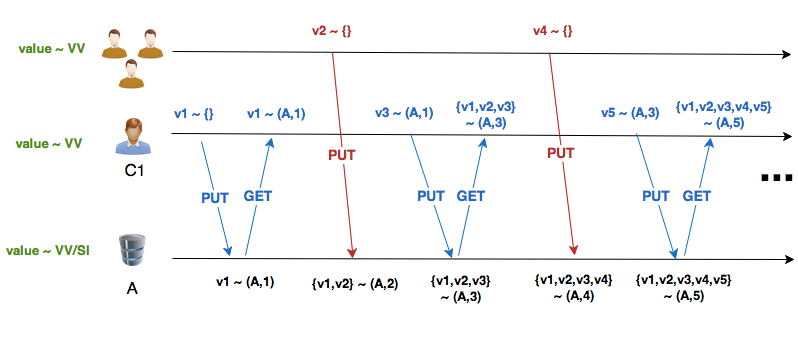
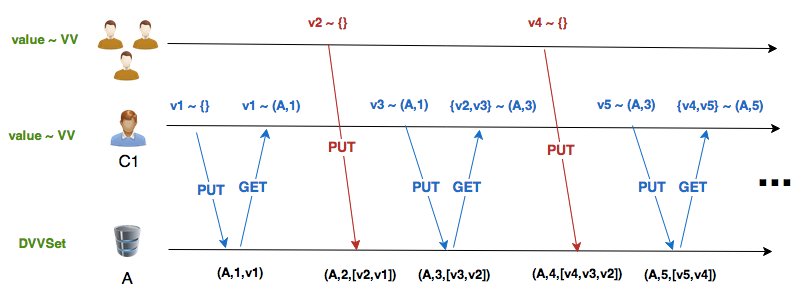
Lets take a look at 2 different scenarios, where we can clearly see real world advantages of DVVSet:
-
Scenario 1
- Client C1 writes, then reads;
- Meanwhile, another client writes a new value (without causal information);
- Repeat 1 and 2.
Version Vector:
Dotted Version Vector Set:
-
Scenario 2
- Client A writes, then reads;
- Next, client B writes, then reads;
- Repeat 1 and 2.
Version Vector:
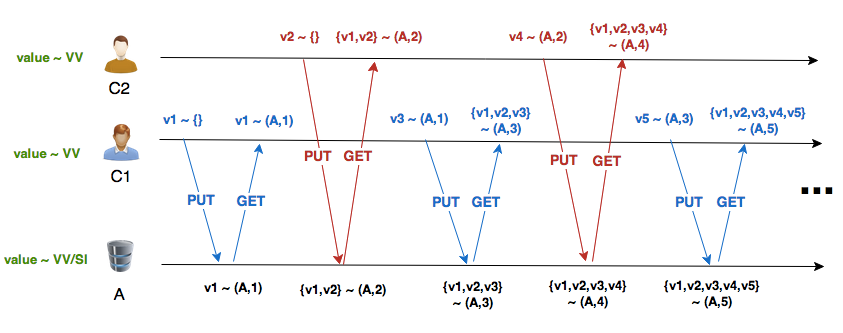
Dotted Version Vector Set:
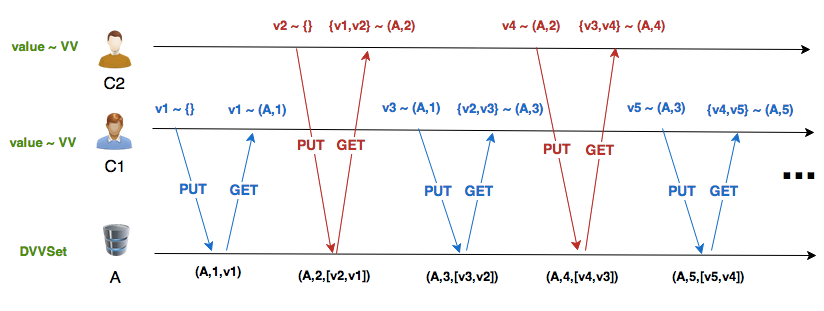




These are two patterns where traditional VV degenerates badly, while DVVSet behaves well. Lets run these scenarios for some time, writing to real Riak nodes:
$ erlc sib.erl; erl sib -pa ebin deps/*/ebin
Erlang R15B02 (erts-5.9.2) [source] [64-bit] [smp:4:4] [async-threads:0] [hipe]
[kernel-poll:false] [dtrace]
Eshell V5.9.2 (abort with ^G)
1> %% Riak with Version Vectors ; Scenario 1
1> sib:run1(101).
Siblings: 101
Values: v79 v10 v18 v34 v61 v68 v45 v1 v25 v30 v19 v55 v63 v29 v53 v89 v90 v49
v14 v67 v36 v65 v31 v27 v91 v72 v2 v86 v99 v11 v21 v20 v85 v22 v71 v3 v26 v7 v59
v93 v57 v40 v17 v9 v77 v4 v41 v62 v80 v33 v43 v54 v76 v37 v98 v92 v15 v56 v16
v66 v60 v46 v48 v52 v5 v13 v44 v8 v32 v101 v70 v69 v97 v28 v73 v50 v83 v6 v42
v51 v75 v81 v74 v100 v64 v12 v88 v94 v78 v47 v82 v95 v96 v23 v35 v39 v87 v24 v58
v38 v84
2> %% Riak with Version Vectors ; Scenario 2
2> sib:run2(101).
Siblings: 101
Values: v32 v75 v49 v19 v83 v50 v72 v1 v33 v22 v14 v26 v92 v64 v9 v86 v37 v85
v16 v17 v99 v43 v24 v47 v56 v11 v87 v52 v67 v94 v35 v81 v95 v6 v28 v27 v8 v20
v10 v100 v53 v97 v13 v62 v38 v93 v55 v34 v31 v74 v5 v3 v54 v25 v59 v84 v12 v76
v23 v42 v36 v39 v58 v45 v73 v78 v96 v66 v51 v48 v41 v80 v71 v101 v79 v57 v30 v7
v68 v77 v82 v65 v15 v89 v63 v40 v18 v91 v60 v21 v29 v70 v46 v98 v4 v2 v69 v90
v88 v61 v44
3> %% Riak with DVVSet ; Scenario 1
3> sib:run1(101).
Siblings: 2
Values: v101 v100
4> %% Riak with DVVSet ; Scenario 2
4> sib:run2(101).
Siblings: 2
Values: v101 v100As we can see, both scenarios have similar results: with VV you have an exploding number of siblings in your Riak database; with DVVSet you have always 2 or 3 siblings.
The test code can be found here.
The major use case that DVVSet targets is a client-server system over a distributed database. So here are the common uses of DVVSet to implement in that case:
-
A client writes a new value
%% create a new DVVSet for the new value V NewDVVSet = dvvset:new(V), %% update the causal history of DVVSet using the server identifier DVVSet = dvvset:update(NewDVVSet, ServerID), %% store DVVSet...
-
A client writes an updated value and an opaque (unaltered) version vector (obtained from a previous read on this key)
%% create a new DVVSet for the new value V, using the client's context NewDVVSet = dvvset:new(Context, V), %% update the new DVVSet with the local server DVVSet and the server ID DVVSet = dvvset:update(NewDVVSet, LocalDVVSet, ServerID), %% store DVVSet...
-
A client reads a value
%% synchronize from different server DVVSet DVVSet = dvvset:sync(ListOfDVVSet), %% get the value(s) Val = dvvset:values(DVVSet), %% get the causal information (version vector) VV = dvvset:join(DVVSet), %% return both to client...
-
A replica receives a DVVSet from the coordinator to (synchronize and) store locally
%% synchronize the new DVVSet with the local DVVSet DVVSet = dvvset:sync([NewDVVSet, LocalDVVSet]), %% store DVVSet...
-
A replica receives a DVVSet from another replica to synchronize for anti- entropy (keeps replicas up-to-date)
%% test if the local DVVSet is causally newer than the remote DVVSet case dvvset:less(NewDVVSet, LocalDVVSet) of %% we already have the newest DVVSet so do nothing true -> do_nothing; %% reconcile both and write locally the resulting DVVSet false -> DVVSet = dvvset:sync([NewDVVSet, LocalDVVSet]), %% store DVVSet... end.
-
A client writes a new value V with the last-write-wins policy
%% create a new DVVSet for the new value, using the client's context NewDVVSet = dvvset:new(Context, V), %% update the new DVVSet with the local server DVVSet and the server ID UpdDVVSet = dvvset:update(NewDVVSet, LocalDVVSet, ServerID), %% preserve the causal information of UpdDVVSet, but keep only 1 value %% according to the ordering function F DVVSet = dvvset:lww(F, UpdDVVSet), %% store DVVSet...
We could do only
DVVSet = dvvset:new(V)and write DVVSet immediately, saving the cost of a local read, but generally its safer to preserve causal information, especially if the lww policy can be turned on and off per request or changed during a key lifetime;
If we really want to bound the number of entries of a dvvset, we can use the
function prune, which takes a dvvset and the maximum number of entries (MAX)
we want to have. If the dvvset exceeds MAX, we throw away the oldest entry that
has no values (if there isn't any, don't do anything). We can know the oldest
entry because we keep a logical time (LT) for each one. LT provides everything
we wanted with realtime timestamps, but with 2 advantages: there is no need to
get / calculate the realtime for every update, and with logical time, we are
immune to system clock skews.
This LT is updated in 3 situations:
- The node serving a PUT executes
update, we calculate the maximum LT for all entries, add 1 and associate it to the entry of that node's ID; - A node receives a replicated PUT to store, so it syncs it with the local
object and calls the function
update_timewith its node ID, before saving; it updates the entry of that node ID with the maximum LT of the dvvset (only if its node ID is present); - A node receives a PUT to synchronize locally (e.g anti-entropy). If the
remote object is not obsolete, use the
update_timeas before and save locally. Thus, we only update the LT if we were already going to save a new version of that object.
The update_time copies the maximum LT in the dvvset to the entry with the ID
that was passed. Nodes IDs that were retired (e.g. a node crashed)
will never update their LT again. On the other hand, every node that serves
PUTs and also saves new versions for that object, will have an increasing LT.
Over time the oldest entries according to LT, would the ones that didn't recently save new versions for this key. Thus, when pruning, we should remove this entries first, since they are from the least participative nodes (or retired nodes).
If you want to use this version of DVVSet, then use the file dvvset_prune instead of dvvset. Then, add two function to your code:
-
Call
prunewith MAX after callingupdatein the coordinating node.%% create a new DVVSet for the new value V, using the client's context NewDVVSet = dvvset:new(Context, V), %% update the new DVVSet with the local server DVVSet and the server ID DVVSet0 = dvvset:update(NewDVVSet, LocalDVVSet, ServerID), %% call prune with MAX = 5 DVVSet1 = dvvset:prune(DVVSet0, 5), %% store DVVSet1...
-
When locally updating / synchronizing a new version (for a replicated PUT, or anti-entropy), call
update_timewith the local node ID after callingsync.%% synchronize the new DVVSet with the local DVVSet DVVSet0 = dvvset:sync([NewDVVSet, LocalDVVSet]), %% call update_time to flag this node as "alive" DVVSet1 = dvvset:update_time(DVVSet0, ServerID), %% store DVVSet...
A write can acknowledge to the client if it succeeded. It can also return the causal information for that key (context), without the values/siblings, which avoids the need to read from the system to do a new write. This returned context after a successful put has one limitation: if the server ends up with siblings after a write, the returned context cannot be used to do new writes, since it represents siblings the client did not read or knows their values. We have to read those siblings, otherwise we would overwrite them, causing information loss for other clients.
The point here is that the context returned from a put should represent the causal information known by that write, including the new value, and not contain causal information about siblings created concurrently from others clients.
We modified DVVSets to support consecutive and concurrent writes, at the expense of losing some of the compactness in the original DVVSets. The file dvvset_put_ack implements this version, which we call DVVSetAck below, for brevity.
The main difference between them is that DVVSetAck supports non-contiguous causal information. Thus, we can now acknowledge a write to the client with the same context provided for that operation, plus the a new single dot that represents the new value/sibling written. With this, multiple clients can do consecutive writes without being forced to read, if siblings were generated from other sources. Clients now don't even have to check if there are siblings before writing again, since we don't return contexts after a put that represent and overwrite siblings which this client does not know about.
Each entry of the DVVSetAck is a 4-tuple (id, base, dots, values). The base
represents the largest contiguous causal events without values, beginning at 0.
The dots are all the individual causal events without values, that aren't
contiguous with the base. Finally, values are the single events (dots) with
values, represented by tuples (dot, value).
We also provide an implementation of both variations: dvvset_prune_put_ack.
(Unlike previous illustrations, lets make responses to client requests explicit.)
With DVVSet:

With DVVSetAck:

With DVVSets (or VV), when client C2 wants to write v3 it can't do it immediately, because the acknowledgment from writing v2 tells that there are siblings, thus writing v3 with that context would overwrite them (in this case v1). Thus, C2 must read that key to obtain all the siblings and their respective context, resolve them and maybe write v3 (the client may want to write another value, after resolving the conflicts, which were unknown when the intention was to write v3). It forces the client to resolve conflicts before being able to write again!
With our modification to DVVSets, we can write multiple times without doing reading or resolving conflicts, as we can see from the second put by client C2, where we overwrite v2 without reading or losing the sibling v1.
We have a new function event that is used exactly as update, but returns a
DVVSet containing only the context and the new dot for the value. Now we can
call join to extract the causal information and return that as acknowledgment
to the client. Finally, we call sync to synchronize with the local DVVSet.
The function update still exists and can be used as before. All it does is
encapsulate event and sync in one function.
-
A client writes a new value
%% create a new DVVSet for the new value V NewDVVSet = dvvset:new(V), %% update the causal history of DVVSet using the server identifier NewDVVSet2 = dvvset:event(NewDVVSet, ServerID), AckContext = dvvset:join(NewDVVSet2), %% acknowledge the write with the context AckContext... %% store NewDVVSet2...
-
A client writes an updated value and an opaque (unaltered) version vector (obtained from a previous read on this key or from a put's ack)
%% create a new DVVSet for the new value V, using the client's context NewDVVSet = dvvset:new(Context, V), %% create a new DVVSet with a new Dot for the new value %% the result is only the previous context plus a new dot NewDVVSet2 = dvvset:event(NewDVVSet, LocalDVVSet, ServerID), AckContext = dvvset:join(NewDVVSet2), %% acknowledge the write with the context AckContext DVVSet = dvvset:sync([LocalDVVSet, Dot]), %% store DVVSet...