This is a TensorFlow implementation of fixed size kernels network described in this paper.
Figure 1. Hyperspectral image cube

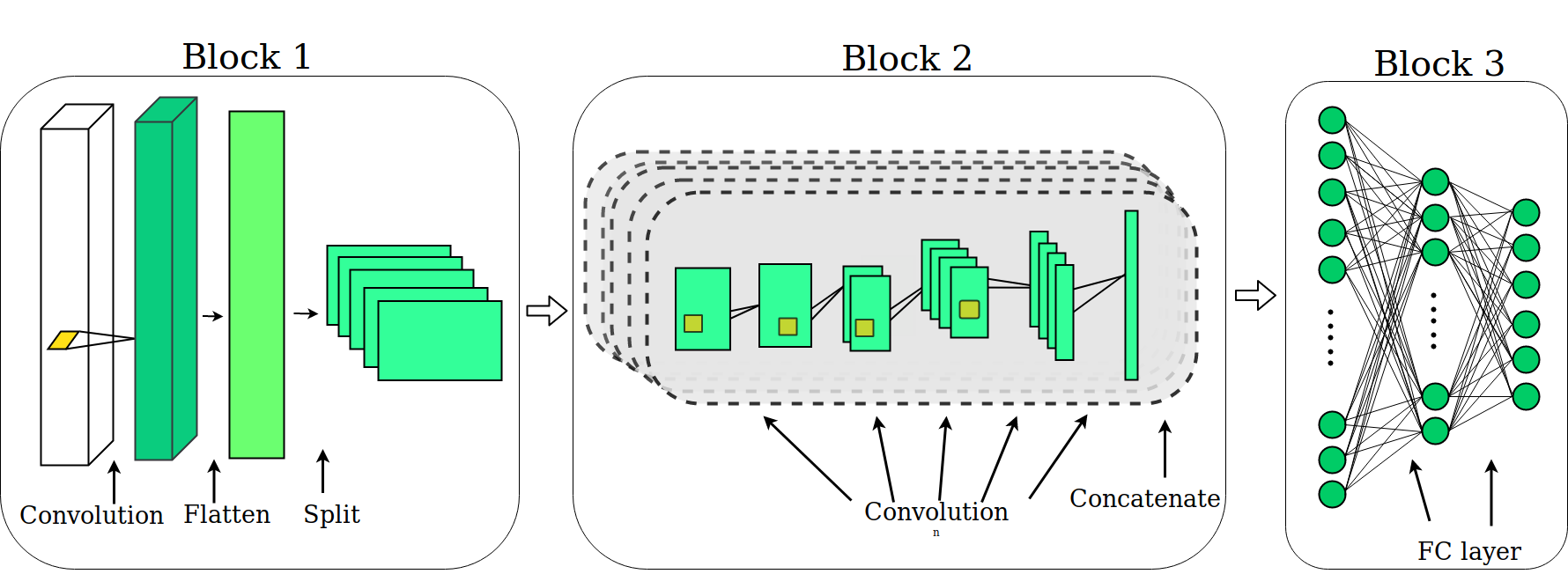
Figure 2. Our fixed size kernel network
- Python3.5+
- TensorFlow 1.10
- Dependencies listed in requirement.txt
- (Optional) CUDA v9.0 and cuDNN v7.0
We recommend you to create a Python Virtual environment and issue the following command in your command prompt/terminal to install dependencies.
pip install -r requirement.txt
Several hyperspectral datasets are available on the UPV/EHU wiki. The default dataset folder is data.
In our paper, we have used the following dataset
- Indian Pines
- Salinas
- Kennedy Space Centre
- Botswana
If you choose to run the run the model on CPU, you can run this script to download and preprocess the dataset.
python preprocess.py --data Indian_pines --train_ratio 0.15 --validation_ratio 0.05
--datato select which dataset to process (e.g. 'Indian_pines','Salinas', 'KSC', 'Botswana'')--train_ratioto configure the percentage of samples use in training.--validation_ratioto configure the percentage of samples use in validation.
To train the model, run this script
python network.py --data Indian_pines --epochs 650
--datato select which dataset to train--epochsto specify number of iterations in training
If you have CUDA or GPU configurations which TensorFlow supports. The convergence of training can be accelerated. However, the optimization requires different arrangement.
To reconfigure the dataset, set the --channel_first tag to True
Example:
python preprocess.py --channel_first True --data Indian_pines --train_ratio 0.15 --validation_ratio 0.05
and run the special script for GPU
python network_GPU.py --data Indian_pines --epochs 650
If you enjoyed our paper, you could cite it via this bibtex ❤
@inproceedings{arc19liu,
author = {Shuanglong Liu and Ringo S.W. Chu and Xiwen Wang and Wayne Luk},
title = {Optimizing CNN-based Hyperspectral Image Classification on FPGAs},
booktitle = {{ARC}},
year = {2019}
}