UDapter is a multilingual dependency parser that uses "contextual" adapters together with language-typology features for language-specific adaptation. This repository includes the code for "UDapter: Language Adaptation for Truly Universal Dependency Parsing"
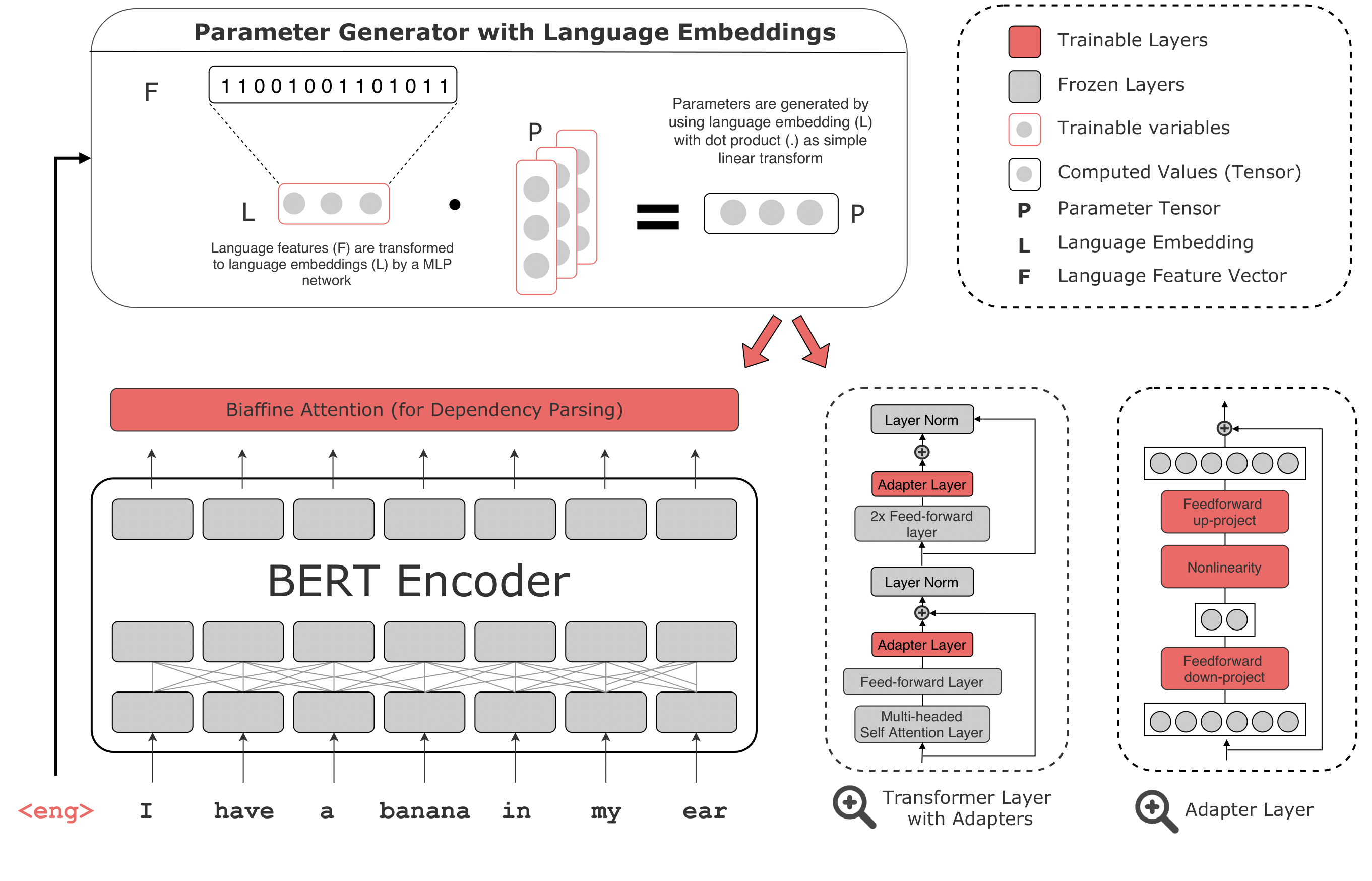
This project is built on UDify using AllenNLP and Huggingface Transformers. The code is tested on Python v3.6
Install the Python packages in requirements.txt.
pip install -r ./requirements.txtAfter downloading the UD corpus from universaldependencies.org, please run scripts/concat_ud_data.sh with --add_lang_id to generate the multilingual UD dataset with language ids.
Before training, make sure the dataset is downloaded and extracted into the data directory and the multilingual
dataset is generated with scripts/concat_ud_data.sh. To indicate training and zero-shot languages use languages/in-langs and languages\oov-langs respectively. To train the multilingual model,
run the command
python train.py --config config/ud/multilingual/udapter-test.json --name udapterTo predict UD annotations, one can supply the path to the trained model and an input conllu-formatted file with a language id as the last column. To split concatenated treebanks with language id, use scripts/split_file_by_lang.py. For prediction:
python predict.py <archive> <input.conllu> <output.conllu> [--eval_file results.json]If you use UDify for your research, please cite this work as:
@inproceedings{ustun2020udapter,
title={UDapter: Language Adaptation for Truly Universal Dependency Parsing},
author={{\"U}st{\"u}n, Ahmet and Bisazza, Arianna and Bouma, Gosse and van Noord, Gertjan},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing},
year = {2020}
}