![]()

![]()

Please first discuss with us on the issue page about your feature request before implementing the actual pull request, so we can discuss about how to achieve the functionality. If we did not discuss about the detail, it is highly possible that we are not accepting the pull request due to the difficulty of maintenance.
We support the following environments. The test cases are ran with tox locally and on github action:
| Env | versions |
|---|---|
| os | ubuntu-18.04, ubuntu-20.04 |
| python | 3.7, 3.8, 3.9, 3.10 |
| pytorch | 1.8.1, 1.9.1, 1.10.2, 1.11.0, 1.12.1 |
- Mar 2022: Introduce SUPERB-SG, see Speech Translation, Out-of-domain ASR, Voice Conversion, Speech Separation and Speech Enhancement for more info.
- Nov 2021: Introduce S3PRL-VC, see Any-to-one and Any-to-any docs for more info.
- Oct 2021: Support DistilHuBERT, see docs for more info
- Sep 2021: We host a challenge in AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing! See SUPERB official site for the challenge details and the SUPERB documentation in this toolkit!
- Aug 2021: We now have a tutorial that introduces our toolkit, you can watch it on Youtube!
- July 2021: We are now working on packaging s3prl and reorganizing the file structure in v0.3. Please consider using the stable v0.2.0 for now. We will test and release v0.3 before August.
- June 2021: Support SUPERB: Speech processing Universal PERformance Benchmark, submitted to Interspeech 2021. Use the tag superb-interspeech2021 or v0.2.0.
- June 2021: Support extracting multiple hidden states from the SSL pretrained models
- Jan 2021: Readme updated with detailed instructions on how to use our latest version!
- Dec 2020: We are migrating to a newer version for a more general, flexible, and scalable code. See the introduction below for more information! The legacy version can be accessed the tag v0.1.0.
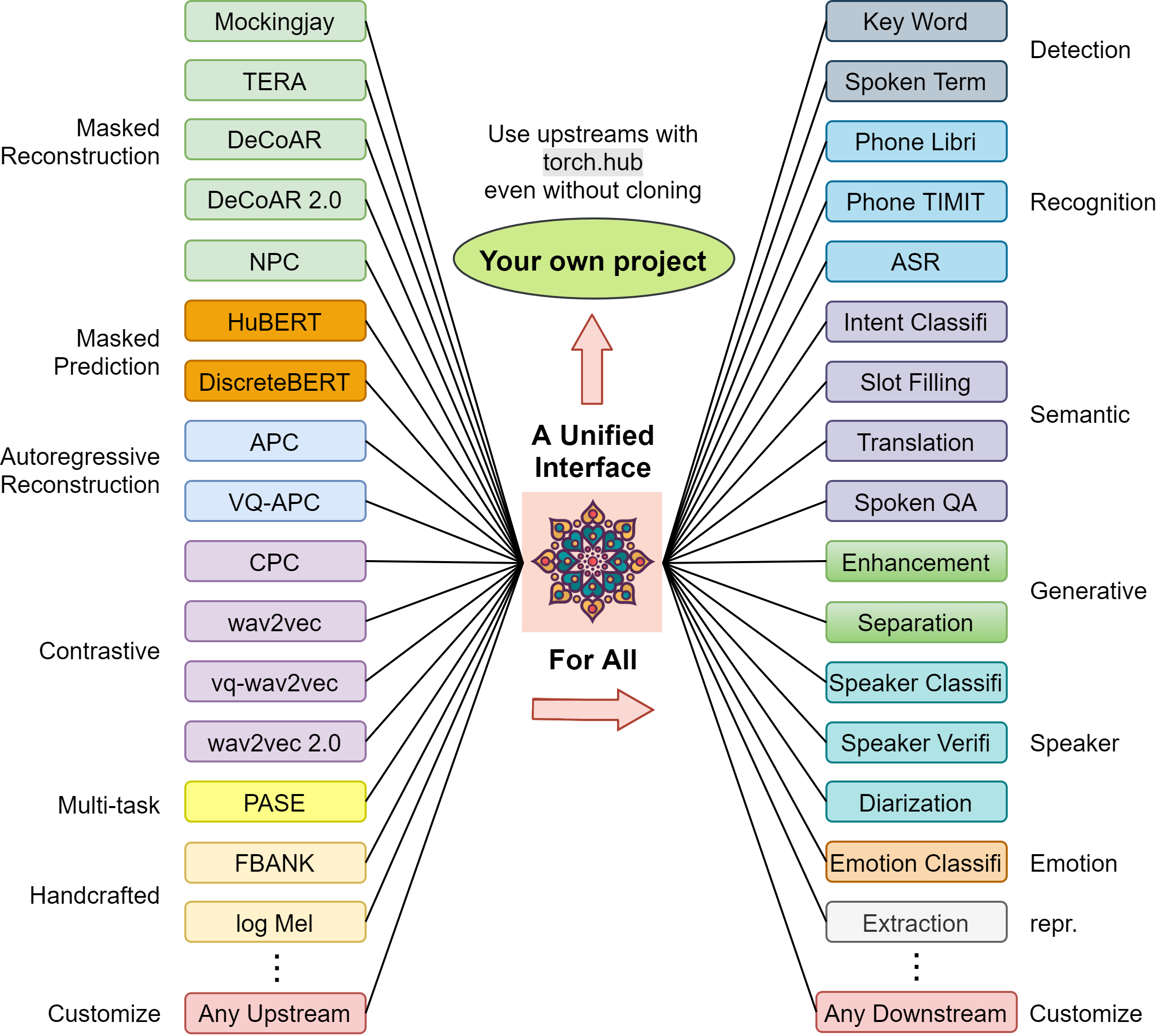
This is an open source toolkit called s3prl, which stands for Self-Supervised Speech Pre-training and Representation Learning. Self-supervised speech pre-trained models are called upstream in this toolkit, and are utilized in various downstream tasks.
The toolkit has three major usages:
- Pretrain upstream models, including Mockingjay, Audio ALBERT and TERA.
- Document: pretrain/README.md
- Easily load most of the existing upstream models with pretrained weights in a unified I/O interface.
- Pretrained models are registered through torch.hub, which means you can use these models in your own project by one-line plug-and-play without depending on this toolkit's coding style.
- Document: upstream/README.md
- Utilize upstream models in lots of downstream tasks
- Benchmark upstream models with SUPERB Benchmark
- Document: downstream/README.md
Below is an intuitive illustration on how this toolkit may help you:
Feel free to use or modify our toolkit in your research. Here is a list of papers using our toolkit. Any question, bug report or improvement suggestion is welcome through opening up a new issue.
If you find this toolkit helpful to your research, please do consider citing our papers, thanks!
- Python >= 3.6
- Install sox on your OS
- Install s3prl: Read doc or
pip install -e ".[all]" - (Optional) Some upstream models require special dependencies. If you encounter error with a specific upstream model, you can look into the
README.mdunder eachupstreamfolder. E.g.,upstream/pase/README.md
- Create a personal fork of the main S3PRL repository in GitHub.
- Make your changes in a named branch different from
master, e.g. you create a branchnew-awesome-feature. - Contact us if you have any questions during development.
- Generate a pull request through the Web interface of GitHub.
- Please verify that your code is free of basic mistakes, we appreciate any contribution!
- Pytorch, Pytorch.
- Audio, Pytorch.
- Kaldi, Kaldi-ASR.
- Transformers, Hugging Face.
- PyTorch-Kaldi, Mirco Ravanelli.
- fairseq, Facebook AI Research.
- CPC, Facebook AI Research.
- APC, Yu-An Chung.
- VQ-APC, Yu-An Chung.
- NPC, Alexander-H-Liu.
- End-to-end-ASR-Pytorch, Alexander-H-Liu
- Mockingjay, Andy T. Liu.
- ESPnet, Shinji Watanabe
- speech-representations, aws lab
- PASE, Santiago Pascual and Mirco Ravanelli
- LibriMix, Joris Cosentino and Manuel Pariente
The majority of S3PRL Toolkit is licensed under the Apache License version 2.0, however all the files authored by Facebook, Inc. (which have explicit copyright statement on the top) are licensed under CC-BY-NC.
List of papers that used our toolkit (Feel free to add your own paper by making a pull request)
- Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders (Liu et al., 2020)
@article{mockingjay, title={Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders}, ISBN={9781509066315}, url={http://dx.doi.org/10.1109/ICASSP40776.2020.9054458}, DOI={10.1109/icassp40776.2020.9054458}, journal={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, publisher={IEEE}, author={Liu, Andy T. and Yang, Shu-wen and Chi, Po-Han and Hsu, Po-chun and Lee, Hung-yi}, year={2020}, month={May} } - TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech (Liu et al., 2020)
@misc{tera, title={TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech}, author={Andy T. Liu and Shang-Wen Li and Hung-yi Lee}, year={2020}, eprint={2007.06028}, archivePrefix={arXiv}, primaryClass={eess.AS} } - Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation (Chi et al., 2020)
@inproceedings{audio_albert, title={Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation}, author={Po-Han Chi and Pei-Hung Chung and Tsung-Han Wu and Chun-Cheng Hsieh and Shang-Wen Li and Hung-yi Lee}, year={2020}, booktitle={SLT 2020}, }
- Understanding Self-Attention of Self-Supervised Audio Transformers (Yang et al., 2020)
@inproceedings{understanding_sat, author={Shu-wen Yang and Andy T. Liu and Hung-yi Lee}, title={{Understanding Self-Attention of Self-Supervised Audio Transformers}}, year=2020, booktitle={Proc. Interspeech 2020}, pages={3785--3789}, doi={10.21437/Interspeech.2020-2231}, url={http://dx.doi.org/10.21437/Interspeech.2020-2231} }
-
Defense for Black-box Attacks on Anti-spoofing Models by Self-Supervised Learning (Wu et al., 2020), code for computing LNSR: utility/observe_lnsr.py
@inproceedings{mockingjay_defense, author={Haibin Wu and Andy T. Liu and Hung-yi Lee}, title={{Defense for Black-Box Attacks on Anti-Spoofing Models by Self-Supervised Learning}}, year=2020, booktitle={Proc. Interspeech 2020}, pages={3780--3784}, doi={10.21437/Interspeech.2020-2026}, url={http://dx.doi.org/10.21437/Interspeech.2020-2026} } -
@misc{asv_ssl, title={Adversarial defense for automatic speaker verification by cascaded self-supervised learning models}, author={Haibin Wu and Xu Li and Andy T. Liu and Zhiyong Wu and Helen Meng and Hung-yi Lee}, year={2021}, eprint={2102.07047}, archivePrefix={arXiv}, primaryClass={eess.AS}
- S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations (Lin et al., 2021)
@misc{s2vc, title={S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations}, author={Jheng-hao Lin and Yist Y. Lin and Chung-Ming Chien and Hung-yi Lee}, year={2021}, eprint={2104.02901}, archivePrefix={arXiv}, primaryClass={eess.AS} }
-
SUPERB: Speech processing Universal PERformance Benchmark (Yang et al., 2021)
@misc{superb, title={SUPERB: Speech processing Universal PERformance Benchmark}, author={Shu-wen Yang and Po-Han Chi and Yung-Sung Chuang and Cheng-I Jeff Lai and Kushal Lakhotia and Yist Y. Lin and Andy T. Liu and Jiatong Shi and Xuankai Chang and Guan-Ting Lin and Tzu-Hsien Huang and Wei-Cheng Tseng and Ko-tik Lee and Da-Rong Liu and Zili Huang and Shuyan Dong and Shang-Wen Li and Shinji Watanabe and Abdelrahman Mohamed and Hung-yi Lee}, year={2021}, eprint={2105.01051}, archivePrefix={arXiv}, primaryClass={cs.CL} } -
Utilizing Self-supervised Representations for MOS Prediction (Tseng et al., 2021)
@misc{ssr_mos, title={Utilizing Self-supervised Representations for MOS Prediction}, author={Wei-Cheng Tseng and Chien-yu Huang and Wei-Tsung Kao and Yist Y. Lin and Hung-yi Lee}, year={2021}, eprint={2104.03017}, archivePrefix={arXiv}, primaryClass={eess.AS} }
}
If you find this toolkit useful, please consider citing following papers.
- If you use our pre-training scripts, or the downstream tasks considered in TERA and Mockingjay, please consider citing the following:
@misc{tera,
title={TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech},
author={Andy T. Liu and Shang-Wen Li and Hung-yi Lee},
year={2020},
eprint={2007.06028},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
@article{mockingjay,
title={Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders},
ISBN={9781509066315},
url={http://dx.doi.org/10.1109/ICASSP40776.2020.9054458},
DOI={10.1109/icassp40776.2020.9054458},
journal={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
publisher={IEEE},
author={Liu, Andy T. and Yang, Shu-wen and Chi, Po-Han and Hsu, Po-chun and Lee, Hung-yi},
year={2020},
month={May}
}
- If you use our organized upstream interface and features, or the SUPERB downstream benchmark, please consider citing the following:
@inproceedings{yang21c_interspeech,
author={Shu-wen Yang and Po-Han Chi and Yung-Sung Chuang and Cheng-I Jeff Lai and Kushal Lakhotia and Yist Y. Lin and Andy T. Liu and Jiatong Shi and Xuankai Chang and Guan-Ting Lin and Tzu-Hsien Huang and Wei-Cheng Tseng and Ko-tik Lee and Da-Rong Liu and Zili Huang and Shuyan Dong and Shang-Wen Li and Shinji Watanabe and Abdelrahman Mohamed and Hung-yi Lee},
title={{SUPERB: Speech Processing Universal PERformance Benchmark}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={1194--1198},
doi={10.21437/Interspeech.2021-1775}
}