Work-stealing algorithms are a popular approach for efficiently scheduling parallel threads and can be represented using a directed acyclic graph (DAG), where nodes represent tasks and edges represent dependencies. Research in this area has focused on the granularity of tasks, the locality of tasks, and the management of the task queue. Java also provides work-stealing thread pools as part of its ExecutorService. Implement a work-stealing algorithm using optimized techniques. Compare your version against Java’s built-in work-stealing thread pool. Discuss the effectiveness of your approach and the im- pact of the optimizations you applied.

Fig.1 - A threadPool creates many threads (workers) beforehand. A big task is recursively broken down into small sub-tasks until it is small enough to quickly processed by a single thread.
- Memo stealing : An approach to avoid looking for victim threads in every stealing attempt and thereby reduce overall CPU cycles spent in stealing.
- Dynamic Granularity Adjustment : In certain intervals, look for irregularity in task distribution across all threads and adjust granularity because of which the threadPool tries to break a task into more sub-tasks and distribute work load in a better manner.

Fig.2 - Interconnectedness of various components in this project
- The core of this implementation is an unbounded concurrent dequeue data structure which uses a resizable circular array to provide dequeue operations. This data structure is owned by each of the threads in the threadpool to store dedicated set of tasks for that particular thread.
- A ThreadPool implementation which takes in the fixed number of worker nodes to create and keep ready. To use this threapool, we will just create an object and push the big task which we want to execute but using parallel processing.
- As an example, a simple example of counting Prime Numbers in a range is used. This is an easy to understand but time consuming problem where time taken to find primes in range 1-1000 is not same as that of finding in range 10,000 - 11,000. This fact is particularly important here because the present optimization should be able to tackle tasks of varied and unequal loads.
- The Runner class uses the prime number task and performs benchmarking.
$ ./gradlew run
Throughput value, Runtime and other performance pointers.
Goto the Runner.java file and change the desired parameters
The final report and presentation is included in the docs directory. Refer to them for a detailed explaination along with evaluation of the proposed optimization.
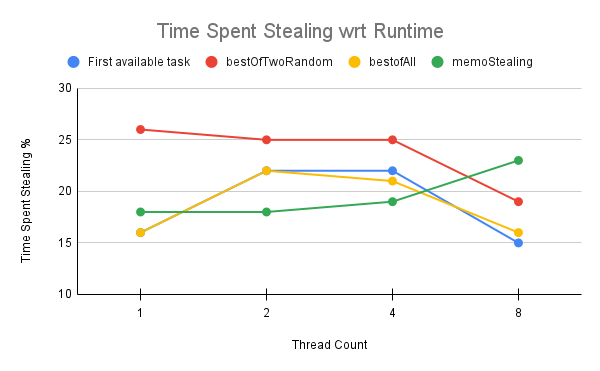
Fig.3 - Comparison between proposed *memoStealing* wrt other algorithms