![]()
Random Forest models can be difficult to interpret, and Bellatrex addresses this challenge by generating explanations that are easy to understand, and by providing insights into how the model arrived at its predictions. Bellatrex does so by Building Explanations through a LocalLy AccuraTe Rule EXtractor (hence the name: Bellatrex) for a given test instance, by extracting only a few, diverse rules. See the published paper for more details.
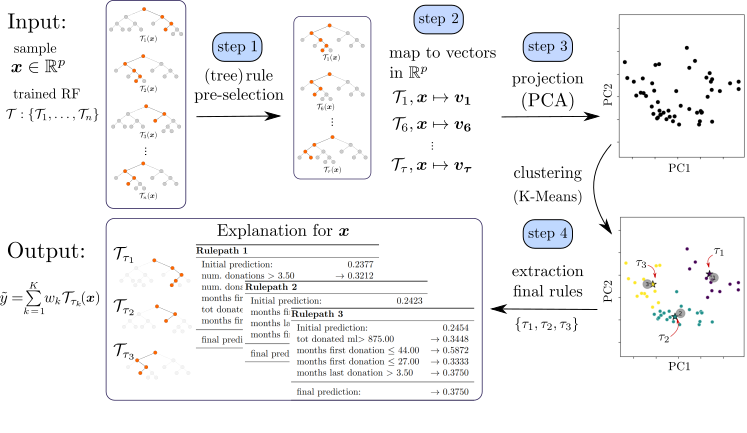
To illustrate how Bellatrex works, let's consider an example: when a user provides a test instance to Bellatrex, the tool begins by 1) pre-selecting a subset of the rules used to make the prediction; it then creates 2) a vector representation of such rules and 3) projects them to a low-dimensional space; Bellatrex then 4) clusters such representations to pick a rule from each cluster to explain the instance prediction. One rule per cluster is shown to the end user through visually appealing plots, and the tool's GUI allows users to explore similar rules to those extracted.
|
| Overview representation of Bellatrex, starting from top left, proceeding clockwise, we reach the output and explanation on the bottom left. |
Another strength of Bellatrex lies in its ability to handle several prediction tasks within scikit-learn implementations of Random Forests. For instance, Bellatrex can generate explanations for binary classification and multi-label predictions tasks with RandomForestClassifier, as well as single- or multi-output regression tasks with RandomForestRegressor. Moreover, Bellatrex is compatible with scikit-survival's RandomSurvivalForest, allowing it to generate explanations for time-to-event predictions in the presence of right-censored data.
This repository contains:
- instructions to run Bellatrex on your machine
- an overwview of the datasets used to test the effectiveness of the method
- accesss to such datasets, as they appear after the pre-processing step.
To ensure that Bellatrex runs correctly, use a Python environment that matches the requirements indicated in requirements.txt. To minimize the chances of encountering compatibility issues, we advice to install the packages on a new (conda) environment with Anaconda:
conda create --name bellatrex-tutorial python=3.9
activare the environment and proceed by installing the packages listed in the requirements.txt file, namely:
conda install scikit-learn==1.1.3
conda install scikit-survival==0.19.0
conda install matplotlib==3.6.2
The scikit-survival package allows to run time-to-event predictions withRandomSurvivalForest. In case of errors it can also be installed by executing the command conda install -c sebp scikit-survival.
Install the Orange library with conda install orange3==3.30 to replicate the statistical tests reported in the manuscript.
For an enhanced user experience that includes interactive plots, install the following packages through pip (not available on conda):
pip install dearpygui==1.6.2
pip install dearpygui-ext==0.9.5
To activate the GUI, set the plot_gui = True.
Note: When running Bellatrex with the GUI for multiple test samples, the program will generate an interactive window. The process may take a couple of seconds, and the the user has to click at least once within the generated window in order to activate the interactive mode. Once this is done, the user can choose to explore the generated rules by clicking on the corresponding representation. To show the Bellatrex explanation for the next sample, close the interactive window and wait until Bellatrex generates the explanation for the new sample.
After downloading the content of this folder and installing the packages, we can dive into the tutorial.py code.
Import the required libraries and set the parameters for the grid search, data folder paths, and other configuration variables.
import os
import numpy as np
import pandas as pd
os.environ["OMP_NUM_THREADS"] = "1" # avoids memory leak UserWarning caused by KMeans
from utilities import score_method, output_X_y
from utilities import format_targets, format_RF_preds
from LocalMethod_class import Bellatrex
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
from sksurv.ensemble import RandomSurvivalForest
# reduce MAX_TEST_SIZE for quick code testing
MAX_TEST_SIZE = 10 #if set >= 100, it takes the (original) value X_test.shape[0]
p_grid = {
"n_trees": [20, 50, 80],
"n_dims": [2, 5, None],
"n_clusters": [1, 2, 3]
}
##########################################################################
root_folder = os.getcwd()
data_folder = os.path.join(root_folder, "datasets")
'''
choose appropriate learning task wth SETUP parameter
for this tutorial, choose between
- 'bin' for explaining binary classification prediction
performed by a RandomForestClassifier
- 'surv' for explaining time-to-event predictions
made by a RandomSurvivalForest
- 'mtr' for explainiing multi-outoput regression prediction
performed by a RandomForestRegressor
'''
SETUP = "bin"
VERBOSE = 3
PLOT_GUI = False
''' levels of verbosity in this script:
- >= 1.0: print best params, their achieved fidelity,
and the scoring method used to compute such performance
- >= 2.0 print final tree idx cluster sizes
GRAPHICAL EXPLANATIONS START FROM HERE:
- >= 3.0: plot representation of the extracted trees (two plots)
- >= 4.0 plot trees without GUI (if PLOT_GUI == False)
- >= 4.0 plot trees with GUI (if PLOT_GUI == True)
- >= 5.0: print params and performance during GridSearch
'''
Load training and testing data from the .csv files, split them into features X and targets (y), and preprocess the data by formatting the target variables according to the prediction scenarios. Load and instantiate the appropriate RandomForest model.
df_train = pd.read_csv(os.path.join(data_folder, SETUP + '_tutorial_train.csv'))
df_test = pd.read_csv(os.path.join(data_folder, SETUP + '_tutorial_test.csv'))
X_train, y_train = output_X_y(df_train, SETUP)
X_test, y_test = output_X_y(df_test, SETUP)
# (for quick testing, set a small MAX_TEST_SIZE)
X_test = X_test[:MAX_TEST_SIZE]
y_test = y_test[:MAX_TEST_SIZE]
orig_n_labels = y_test.shape[1] # meaningful information for multi-output
y_train, y_test = format_targets(y_train, y_test, SETUP, VERBOSE)
####### instantiate R(S)F whose predictions will be explained #######
if SETUP.lower() in ['surv']:
rf = RandomSurvivalForest(n_estimators=100, min_samples_split=10,
random_state=0)
elif SETUP.lower() in ['bin','mlc']:
rf = RandomForestClassifier(n_estimators=100, min_samples_split=5,
random_state=0)
elif SETUP.lower() in ['regress', 'mtr']:
rf = RandomForestRegressor(n_estimators=100, min_samples_split=5,
random_state=0)
Once the Random Forest is instantiated, the fit method in Bellatrex trains the Random Forest and set the parameters for Bellatrex.
# fit RF here. The hyperparameters are given
Bellatrex_fitted = Bellatrex(rf, SETUP,
p_grid=p_grid,
proj_method="PCA",
dissim_method="rules",
feature_represent="weighted",
n_jobs=1,
verbose=VERBOSE,
plot_GUI=PLOT_GUI,
plot_max_depth=5,
dpi_figure=100).fit(X_train, y_train)
# store, for every sample in the test set, the predictions from the
# local method and the original R(S)F
N = min(X_test.shape[0], MAX_TEST_SIZE)
y_pred = []
Loop through the test set, make predictions using the Bellatrex local method, and store the results.
'''
call the .predict method. The hyperparamters were given in the .fit.
and are now tuned for every instance, the .predict method ouputs:
1) the local prediction
2) info about the Bellatrex instance: optimal parameters,
final extracted trees/rules, their weight in the prediction etc.
'''
for i in range(N): #for every sample in the test set: call .predict
y_pred_i, _ = Bellatrex_fitted.predict(X_test, i) #tuning is also done
y_pred.append(y_pred_i)
y_ens_pred = format_RF_preds(rf, X_test, SETUP)
# adapt to numpy array (N, L) where N = samples, L = labels (if L>1)
# and make sure y_pred is a (N,l)-shaped array (and not a list of arrays)
if SETUP.lower() not in multi_label_key_list + mt_regression_key_list :
y_pred = np.array(y_pred).ravel() #force same array format
y_pred = np.array(y_pred)
The output explanation consists in a few rules extracted from the original Random Forest. Most of the computation happens at this stage whithin the .predict method, more explicitly within the TreeExtraction class that is instantiated at this stage. It is worth diving into it more details,
and look into the preselect_represent_cluster_trees method, that does most of the job.
The first step consists in selecting a subset of trees from the RF, with the goal of eliminating outliers.
This is performed by computing, for a given instance x to explain, how far a single tree prediction is cmapred to the ensemble prediction. This is performed by calcul_tree_proximity_loss function, and the best
The second step consists in representing each of the preselected trees x. More specifically, we follow x as it traverses the tree and we keep track of the input covariates used to perform each split.
Next, we assign for each split at node tree_splits_to_vector function. For more details, refer to the paper.
Next, we project such tree vector representations to a low-dimensional space using Principal Component Analysis (PCA). The idea is to remove noise, to improve computational efficiency for later steps, and to enable a better visualisation of the subsequent clustering.
Finally, we perform clustering on the vector representations using a standard clustering method, such as K-Means++. By doing so, we group the vectors into

|
| Situation after the pre-selected trees have been clustered adn projected to a lower dimensional space. For this instance, 3 clusters lead to the most faithful prediction (highlighted on the left). The 3 rules clostest to the cluster center are selected and shown to the end user as an explanation (starred shape). The right side of the plot highlights the predicted labels of the single trees. |
Finally, given the x, we build a surrogate model prediction as follows:
Where
Let's run Bellatrex on sample 1 of the blood dataset
X_0 X_1 X_2 X_3
id:1 7 9 2250 89
The output expalanation of Bellatrex of this sample consists of 3 final rules, these rules are shown to the end user.

|
| Situation after the pre-selected trees have been clustered adn projected to a lower dimensional space. For this instance, 3 clusters lead to the most faithful prediction (highlighted on the left). The 3 rules clostest to the cluster center are selected and shown to the end user as an explanation (starred shape). The right side of the plot highlights the predicted labels of the single trees. |
In this example, the final rules extracted are the ones generated by trees of index 58, 62 and 73 of the original Random Forest.
With weight:
Baseline prediction: 0.1898 (weight = 0.30)
node 0: w: 1.000 3 > 51.50 (3 = 89.00) --> 0.0779
node 142: w: 0.223 2 <= 7125.00 (2 = 2250.00) --> 0.0600
node 143: w: 0.216 2 > 1625.00 (2 = 2250.00) --> 0.0833
node 147: w: 0.134 0 <= 16.50 (0 = 7.00) --> 0.0588
node 148: w: 0.124 0 > 5.00 (0 = 7.00) --> 0.0250
node 160: w: 0.062 3 > 85.00 (3 = 89.00) --> 0.1429
node 162: w: 0.012 1 > 8.50 (1 = 9.00) --> 0.0000
leaf 164: predicts:0.0000
With weight:
Baseline prediction: 0.2330 (weight = 0.50)
node 0: w: 1.000 0 > 6.50 (0 = 7.00) --> 0.1020
node 108: w: 0.484 2 > 875.00 (2 = 2250.00) --> 0.1527
node 132: w: 0.223 0 <= 24.50 (0 = 7.00) --> 0.1395
node 133: w: 0.220 1 <= 9.50 (1 = 9.00) --> 0.1837
node 134: w: 0.167 3 > 18.50 (3 = 89.00) --> 0.1684
node 136: w: 0.162 0 <= 11.50 (0 = 7.00) --> 0.2500
node 137: w: 0.063 0 <= 8.50 (0 = 7.00) --> 0.0000
leaf 138: predicts:0.0000
With weight:
Baseline prediction: 0.2346 (weight = 0.20)
node 0: w: 1.000 1 > 4.50 (1 = 9.00) --> 0.3536
node 74: w: 0.442 0 > 4.50 (0 = 7.00) --> 0.1513
node 134: w: 0.182 1 > 5.50 (1 = 9.00) --> 0.0750
node 148: w: 0.128 3 > 71.50 (3 = 89.00) --> 0.1600
node 154: w: 0.044 3 > 74.00 (3 = 89.00) --> 0.0526
node 156: w: 0.034 2 <= 2250.00 (2 = 2250.00) --> 0.2500
leaf 157: predicts:0.2500
Finally, we can compute the performance of Bellatrex compared to the original RandomForest model.
cv_fold_local = score_method(y_test, y_pred, #list or array, right?
SETUP) #workaround for now
cv_fold_ensemble = score_method(y_test, y_ens_pred, #list or array, right?
SETUP)
performances = pd.DataFrame({
"Original R(S)F" : np.round(np.nanmean(cv_fold_ensemble),4),
"Bellatrex": np.round(np.nanmean(cv_fold_local),4),
}, index=[0]
)
if SETUP.lower() in multi_label_key_list + mt_regression_key_list:
performances.insert(1, "n labels", orig_n_labels) # add extra info
print(performances)