SOM (Simple Object Machine) Smalltalk is a nice little Smalltalk dialect which is file-based and independent of the Bluebook bytecode and interpreter. There are already different implementations of the SOM VM (see http://som-st.github.io/) and also a framework for performance comparisons of the SOM implementations with other languages (see https://github.com/smarr/are-we-fast-yet).
I recently implemented two versions of the Smalltalk-80 Bluebook interpreter (one in C++ and one in Lua/LuaJIT) and a couple of analysis tools (see https://github.com/rochus-keller/Smalltalk/). I'm still trying to implement a Smalltalk-80 VM which directly compiles the Bluebook bytecode to Lua or LuaJIT bytecode to get rid of the interpreter without modifying the original Xerox Smalltalk-80 Virtual Image or source code files; this turned out to be tricky; the main problem is that a significant part of the VM (e.g. the scheduler, execution contexts and stacks) is implemented directly in Smalltalk and part of the virtual image, and that the virtual image makes many concrete assumptions about the interpreter and the memory model, so these cannot be replaced easily. Smalltalk-80 is a very impressive piece of work and worth studying in detail; but it is also a rather closed world and difficult to reuse. At the moment I assume that it is much easier and faster to build a compiler for SOM that directly generates LuaJIT bytecode. SOM also has the advantage of few dependencies, so that it is suited for embedded use in applications as an alternative to Lua. But first of all I want to find out how good the performance of this approach is compared to the existing benchmark results (see https://github.com/smarr/are-we-fast-yet), especially those based on Lua.
Interim conclusion September 2020: I have implemented a SOM to Lua transpiler and a SOM to LuaJIT bytecode compiler with different optimizations/attempts. My experiments have shown that the runtimes with and without JIT switched on differ only marginally. Especially the are-we-fast-yet benchmark suite has shown that hand-crafted Lua code runs 24 times faster than the LuaJIT bytecode generated from the SOM source code. The primary reason is that the Tracing JIT compiler of LuaJIT does not support instantiation of closures, but Smalltalk and SOM require closures for almost any purpose. I therefore have reached the limits of the current versions of LuaJIT. See here for more information. To work around this limitation LuaJIT closures have to be avoided (i.e. replaced by alternative implementations).
Final conclusion December 2020: after implementing a work-around for closures and conducting more measurements I conclude that even with JIT support for closures the SOM version of the benchmark would still run more than factor 7 slower than the corresponding plain Lua implementation. Pharo 7 in comparison runs about 20% faster (factor 1.2) than the plain Lua implementation, see this report and this section. From this I conclude that another speed-up can only be achieved when applying similar optimizations on bytecode and VM level as done in Cog/Spur.
This is a hand-crafted lexer and parser. I started with the version from https://github.com/rochus-keller/Smalltalk/ and modified it until it was able to successfully parse all SOM files provided in https://github.com/SOM-st/som. Unfortunately there doesn't seem to be a "SOM language report" (such as e.g. this one, whereby the related investigations have not yet been completed) so the exploration of the functionality of language and VM so far is largely based on trial and error.
Usually I start with an EBNF syntax and transform it to LL(1) using my own tools (see https://github.com/rochus-keller/EbnfStudio). There is actually an ANTLR grammar for SOM which I could have used. But since I already had a proven Smalltalk parser with code model I decided to reuse that one. Parsing all of the SOM TestSuite and Smalltalk files takes about 55ms on my old HP EliteBook 2530p machine. Since there is no formal language specification I took the examples, test harness and existing implementations as a reference. Compared to these my parser deviates in the following aspects:
- The 'super' keyword cannot be assigned to a variable (thus I had to modify SuperTest.som);
- 'system' and the meta classes are the only global variables; no other globals can be directly accessed; thus it is possible to load all required classes at compile time, and the original GlobalTest>>testUnknownGlobalHandler causes a parser error;
There is also an AST and a visitor which I will use for the code generator.
I also plan to implement simple (optional) type annotations for parameters and variables (a subset of this paper).
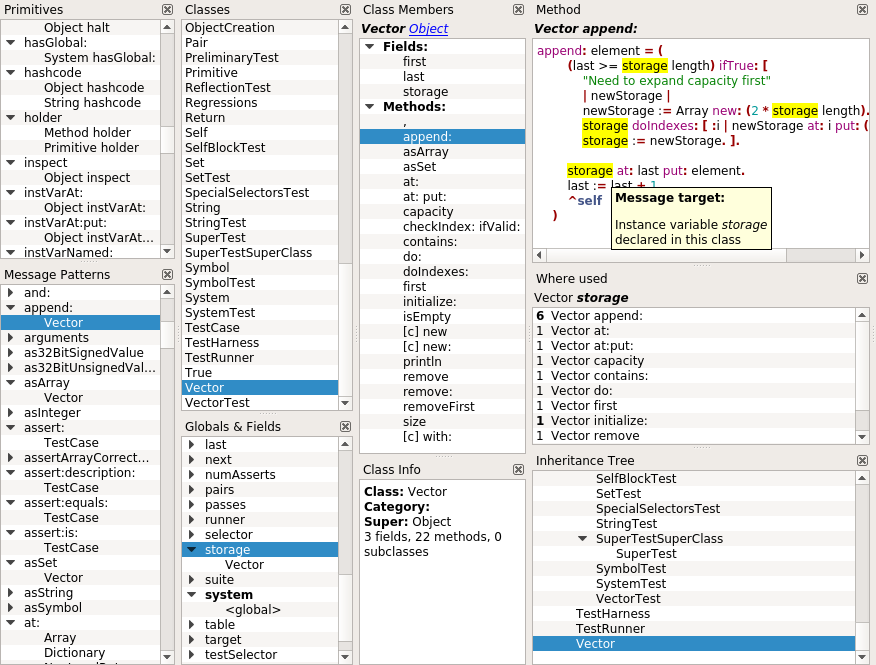
The Class Browser is essentially the same as the https://github.com/rochus-keller/Smalltalk/#a-smalltalk-80-class-browser-written-in-c one. See there for the supported features. The main difference: there are no categries in SOM, and primitives are named, not numbered.
Here is a screenshot:
This is work in progress. Hello.som, the Benchmarks package and most of the TestHarness tests work. The focus is not (yet) on performance, but on the most direct mapping from Smalltalk to Lua syntax constructs possible. There is no inlining yet. The object model mapping is described in the comments of SomLjObjectManager.cpp. Starting from the main SOM file (provided by command line) all explicitly referenced classes are loaded at compile time.
Note that this is the same application as the bytecode compiler (see below) and the -lua command line option is required to run it (default is the bytecode compiler).
See the Benchmarks_All_*.txt files in the Results folder for performance comparisons with CSOM and SOMpp. Even though my LuaJIT based SOM implementation is not optimized for performance yet it performs pretty well compared to the original C/C++ VMs provided on http://som-st.github.io/. On my test machine (HP EliteBook 2530p, Intel Core Duo L9400 1.86GHz, 4GB RAM, Linux i386) I get the following results when running Examples/Benchmarks/All.som:
| Version | (Fixed) Summed Average Runtime [ms] | Speed-down factor |
|---|---|---|
| CSOM | 8604 | 12 |
| SOM++ copying collector | 3425 | 5 |
| SOM++ mark-sweep | 1874 | 3 |
| SomLjVirtualMachine v0.2 | 746 | 1 |
Note that there is an issue in Benchmarks/All.som line 54 which causes Summed Average Runtime only to consider the last benchmark.
The transpiled methods are written to Lua files in the Lua subdirectory relative to the main SOM file for inspection.
This VM deviates in the following aspects from CSOM and SOM++:
- apparently a call to an unknown method should call the method "doesNotUnderstand: selector arguments: arguments"; this VM instead reports a Lua error like "attempt to call method 'foo' (a nil value)"; apparently subsequent calls to the unknown method should just return the argument Array, which is not implemented here; I thus disabled DoesNotUnderstandTest.som;
- call to escaped blocks with non-local returns doesn't work, because the non-local return requires pcall and a method local closure which is different if the block is called within another method; thus BlockTest>>testEscapedBlock is deactivated (there seem to be other issues in this test as well);
- primitive implementations also have the class Method; class Primitive is not used; thus ClassStructureTest>>testThatCertainMethodsArePrimitives modified;
- Block1 is not used; each block has class Block instead; thus ClassStructureTest>>testClassIdentity is modified;
- see the parser section above for more deviations;
- all other failed tests are subject to further analysis and debugging.
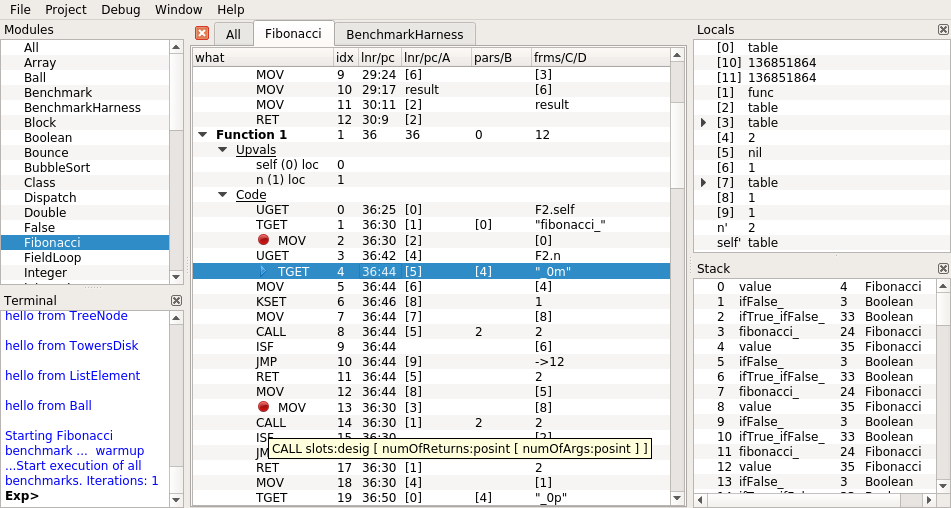
The VM includes my Lua IDE (see https://github.com/rochus-keller/LjTools#lua-parser-and-ide-features); the IDE can be enabled by the -ide or -pro command line option. The source level debugger is available; you can set breakpoints and step through the Lua code, watching the stack trace and the local variable values.
Here is a screenshot:
This is currently work in progress. Hello.som, the Benchmarks package and most of the TestHarness tests work. I implemented the same inlining of ifTrue/ifFalse as in SOM++ (CSOM doesn't seem to make inlining) plus inlining of whileTrue/whileFalse as in ST80. The performance is currently about factor two of the Lua transpiler version (see table), so not really good yet, because the influence of the JIT is rather minimal (see below). The object model mapping is identical to the one used by the Lua transpiler (see above). In contrast to the Lua transpiler the bytecode compiler doesn't use pcall, but a second return arugument to implement non-local returns. The same deviations from CSOM/SOM++ apply like in the Lua transpiler version (see above). Here are the results of running Examples/Benchmarks/All.som on my test machine:
| Version | (Fixed) Summed Average Runtime [ms] | Speed-down factor |
|---|---|---|
| CSOM | 8604 | 18.4 |
| SOM++ copying collector | 3425 | 7.3 |
| SOM++ mark-sweep | 1874 | 4.0 |
| LjVM Lua | 746 | 1.6 |
| LjVM bytecode (bc) | 733 | 1.6 |
| LjVM bytecode nojit | 835 | 1.8 |
| LjVM bc if inlined | 485 | 1.0 |
| LjVM bc if & while inlined | 468 | 1.0 |
| LjVM bc if & while inl. nojit | 494 | 1.1 |
| LjVM bc 0.8.0 | 146 | 0.3 |
The VM includes my bytecode debugger (see https://github.com/rochus-keller/LjTools/#luajit-bytecode-debugger); it can be enabled by the -dbg command line option; you can set breakpoints and step through the Lua code, watching the stack trace and the local variable values.
Here is a screenshot:
There is also a commandline version of the virtual machine called LjSOM. It supports both the Lua transpiler and LuaJIT bytecode compiler described above. LjSOM is easier to integrate in a performance measurement setup like https://github.com/smarr/are-we-fast-yet. Of the 14 benchmarks 12 already work (note that CD neither works on SOM++); the remaining two are DeltaBlue and CD and are further investigated. I was able to run the 12 benchmarks on LjSOM, SOM++ and CSOM on my test machine (see above) using run_are-we-fast-yet.sh (see Results folder). The results are documented in Are-we-fast-yet_Results.ods; here is a summary table:
| Version | Runtime geometric mean [us] | Speed-down factor |
|---|---|---|
| CSOM | 155'018* | 15.9* |
| SOM++ copying collector | 206'990 | 7.9 |
| SOM++ mark-sweep | 111'867 | 4.3 |
| LjSOM -nojit | 32'389 | 1.2 |
| LjSOM 0.7.2 | 26'140 | 1 |
| LjSOM 0.8 | (13'070, estimate) | (0.5, estimate) |
| Plain Lua/LuaJIT | 1'092 | 0.042 (factor 12 to LjSOM 0.8) |
*Note: CSOM wasn't able to run Json (run out of lexer reading buffer space) and Havlak (not enough heap), so the overall comparison makes no sense; the provided values only represent the subset.
Note that CSOM and SOM++ with copying collector were built with default settings (i.e. just cloned the Github repository and run the build script). I assume these were the versions used to obtain the measurement results presented on http://som-st.github.io/. Since I didn't use the same number of iterations as suggested in rebench.conf of https://github.com/smarr/are-we-fast-yet I use the geometric mean of the 12 benchmark averages for comparison (as it is e.g. recommended by The Computer Language Benchmarks Game).
Concerning the present LuaJIT performance it has to be noted that with the current implementation of my bytecode compiler Blocks are represented by closures (unless inlined) and each run potentially requires a closure instantiation (FNEW bytecode) which is not supported by the current version of the LuaJIT tracing compiler (NYI). It is therefore not surprising that the JIT has only a minimal influence (factor 0.1 to 0.2). The version of the benchmark written in Lua performs much better, with a speedup factor of 24 (see Results/Are-we-fast-yet_Results.ods). Here is a log recorded with LjSOM running Benchmarks/All.som: LjSOM_0.7.3_Benchmarks_All_trace_log.pdf. Bytecode 48 (n=227) is UCLO and bytecode 49 (n=251) is FNEW, both required to instantiate closures. Of the 892 attempts of the JIT tracer 767 failed; 493 of which directly because of the not supported bytecodes, and 185 because of re-attempting blacklisted traces. I will next try to take FNEW and UCLO out of loops as far as possible.
I instrumented the code to find out whether I could take out FNEW from loops and move it to superordinate functions (method or module level). The results of this analysis are in LjSOM_0.7.3_Benchmarks_All_FNEW_optimization_analysis.ods. The Benchmarks code includes 198 Block literals of which 129 can be inlined; only 14 can be relocated to a higher level; in only 3 of these FNEW is called in a loop, and only one seems to be performance relevant; from that I concluded that modifying the bytecode generator is not worth the effort.
So I have reached the limits of the current versions of LuaJIT with closures. I therefore implemented yet another bytecode generator which replaces closures by normal functions with concatenated tables which represent arguments and locals; the generator is still work in progress, but the benchmarks which already work show a speed-up between a factor two and three (geomean) compared to the previous version. Examples/Benchmarks and TestSuite work with the closure based code generator with a speed-up factor three. The are-we-fast-yet suite only partially works (Richards, Json and Havlak give errors) with a speed-up factor two. See Results/Benchmarks_All_Results.ods and this report. Since the Examples/Benchmarks results based on the FNEW closures are nearly the same with and without JIT (i.e. we mostly run in the interpreter), this is a good reason to assume that in case of closure support by the tracing JIT the result would be about factor 4 faster (as observed in http://luajit.org/performance_x86.html between interpreter and JIT mode); our closure substitute is therefore quite close already, i.e. even with JIT support for closures the SOM version of the benchmark would still run more than factor 7 slower than the corresponding Lua implementation, or the current Smalltalk implementations based on Cog/Spur.
Here is a binary version of the class browser and the virtual machine for Windows: http://software.rochus-keller.ch/Som_win32.zip. Just unpack the ZIP somewhere on your drive and double-click SomClassBrowser.exe or one of the batch files; Qt libraries are included as well as the SOM Benchmarks example.
Follow these steps if you want to build the software yourself:
- Make sure a Qt 5.x (libraries and headers) version compatible with your C++ compiler is installed on your system.
- Create an empty directory, call it e.g. Build.
- Download https://github.com/rochus-keller/Som/archive/master.zip and unpack it to the Build directory. Rename it Som.
- Download https://github.com/rochus-keller/GuiTools/archive/master.zip and unpack to in the Build directory. Rename it GuiTools.
- Download https://github.com/rochus-keller/LjTools/archive/master.zip and unpack it to the Build directory. Rename it LjTools.
- Download https://github.com/rochus-keller/LuaJIT/archive/LjTools.zip and unpack it to the Build directory. Rename it LuaJIT. Go to the src subdirectory and run the build script appropriate for your platform (see LuaJIT/doc/install.html for more information).
- Goto the Build/Som directory and execute e.g.
QTDIR/bin/qmake SomClassBrowser.proor any other pro file in the directory (see the Qt documentation concerning QTDIR). - Run make; after a couple of seconds you will find the executable in the build directory.
Alternatively you can open the pro file using QtCreator and build it there. Note that there are different pro files in this project.
If you need support or would like to post issues or feature requests please use the Github issue list at https://github.com/rochus-keller/Som/issues or send an email to the author.