- If you are new to Data Science
- Natural Language Processing (NLP)
- Statistics
- Blogs and other Community based resources
- ML Math
- Inspirational Stories of people breaking into Machine Learning and Data-Science
- General Datasets
- Finance Related Datasets
- Super Large Kaggle Datasets
- Numpy
- TensorFlow
- Machine Learning & Deep Learning Tutorials
- Interview-Related-Links
- Genetic Algorithms
- Kaggle Competitions WriteUp
- List of Most Starred Github Projects related to Deep Learning
- Linear Regression Tutorials
- Logistic Regression Tutorials
- K Nearest Neighbors Tutorials
- Best Courses
- Top Machine Learning Podcasts
- Most Important Deep Learning Papers
- Great Deep Learning Paper Year-wise
- Deep Learning Resources
- Best Deep Learning Courses
- Awesome Deep Learning Projects
- Project Ideas for deep learning and general machine learning
- Natural Language Project Ideas
- Forecasting Project Ideas
- Recommendation systems Project Ideas
- Some of the Best Kaggle Competitions for Beginners
- Kaggle Strategies and skills
| Preview | Description |
|---|---|
 |
Key differences of a data scientist vs. data engineer |
 |
A visual guide to Becoming a Data Scientist in 8 Steps by DataCamp (img) |
 |
Mindmap on required skills (img) |
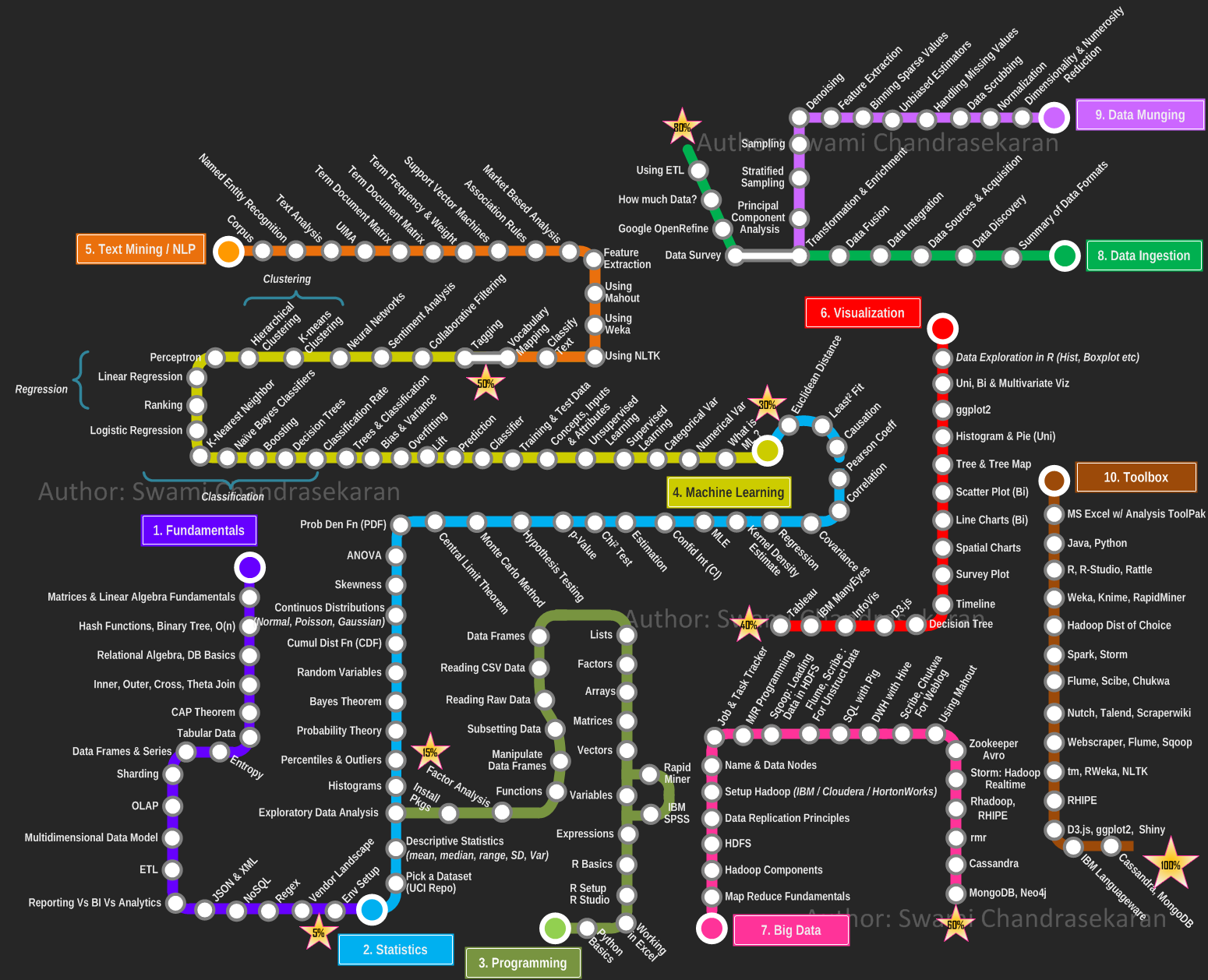 |
Swami Chandrasekaran made a Curriculum via Metro map. |
 |
by @kzawadz via twitter |
 |
By Data Science Central |
 |
From this article by Berkeley Science Review. |
 |
Data Science Wars: R vs Python |
|
By Data Science Central |
|
From this article by Berkeley Science Review. |
|
Data Science Wars: R vs Python |
- Datasets is a lightweight and extensible library to easily share and access datasets and evaluation metrics for Natural Language Processing (NLP) and more.
- The-NLP-Pandect-was created to help you find almost anything related to NLP that is available online.
-
Analytics India Magazine | Artificial Intelligence & Data Science stories
-
Blogs on Artificial Intelligence, Machine Learning, Python & Data Science
-
Data Science Community Newsletter – NYU Center for Data Science
-
Data Elixir - News and resources for data science practitioners
- Brian Ross - from Carpenter to Data-Engineer
- Krish Naik
- Success Story of Saugata Paul : A career break from Infosys to Data Scientist at SPi Global
- Success Story of Ramesh Vellanki: A non-programmer to Data Scientist @ CitiBank
- Success Story of Sriganesh: From 10+ years @ IT Services to a Data Scientist @ Amazon
- How I Got 4 Data Science Offers and Doubled my Income 2 Months after being Laid Off
- I got 7 job offers during the worst job market in history. Here’s the data
- MNIST Handwritten digits
- Google House Numbers from street view
- CIFAR-10 and CIFAR-100
- Academic Torrents
- hadoopilluminated.com
- data.gov - The home of the U.S. Government's open data
- IMAGENET
- Tiny Images 80 Million tiny images6.
- Flickr Data 100 Million Yahoo dataset
- Berkeley Segmentation Dataset 500
- UC Irvine Machine Learning Repository
- Flickr 8k
- Flickr 30k
- Microsoft COCO
- VQA
- enigma.com - Navigate the world of public data - Quickly search and analyze billions of public records published by governments, companies and organizations.
- datahub.io
- United States Census Bureau
- Image QA
- AT&T Laboratories Cambridge face database
- AVHRR Pathfinder
- usgovxml.com
- aws.amazon.com/datasets
- Air Freight - The Air Freight data set is a ray-traced image sequence along with ground truth segmentation based on textural characteristics. (455 images + GT, each 160x120 pixels). (Formats: PNG)
- Amsterdam Library of Object Images - ALOI is a color image collection of one-thousand small objects, recorded for scientific purposes. In order to capture the sensory variation in object recordings, we systematically varied viewing angle, illumination angle, and illumination color for each object, and additionally captured wide-baseline stereo images. We recorded over a hundred images of each object, yielding a total of 110,250 images for the collection. (Formats: png)
- Annotated face, hand, cardiac & meat images - Most images & annotations are supplemented by various ASM/AAM analyses using the AAM-API. (Formats: bmp,asf)
- Image Analysis and Computer Graphics
- Brown University Stimuli - A variety of datasets including geons, objects, and "greebles". Good for testing recognition algorithms. (Formats: pict)
- CAVIAR video sequences of mall and public space behavior - 90K video frames in 90 sequences of various human activities, with XML ground truth of detection and behavior classification (Formats: MPEG2 & JPEG)
- Machine Vision Unit
- CCITT Fax standard images - 8 images (Formats: gif)
- CMU CIL's Stereo Data with Ground Truth - 3 sets of 11 images, including color tiff images with spectroradiometry (Formats: gif, tiff)
- CMU PIE Database - A database of 41,368 face images of 68 people captured under 13 poses, 43 illuminations conditions, and with 4 different expressions.
- CMU VASC Image Database - Images, sequences, stereo pairs (thousands of images) (Formats: Sun Rasterimage)
- Caltech Image Database - about 20 images - mostly top-down views of small objects and toys. (Formats: GIF)
- Columbia-Utrecht Reflectance and Texture Database - Texture and reflectance measurements for over 60 samples of 3D texture, observed with over 200 different combinations of viewing and illumination directions. (Formats: bmp)
- Computational Colour Constancy Data - A dataset oriented towards computational color constancy, but useful for computer vision in general. It includes synthetic data, camera sensor data, and over 700 images. (Formats: tiff)
- Computational Vision Lab
- Content-based image retrieval database - 11 sets of color images for testing algorithms for content-based retrieval. Most sets have a description file with names of objects in each image. (Formats: jpg)
- Efficient Content-based Retrieval Group
- Densely Sampled View Spheres - Densely sampled view spheres - upper half of the view sphere of two toy objects with 2500 images each. (Formats: tiff)
- Computer Science VII (Graphical Systems)
- Digital Embryos - Digital embryos are novel objects which may be used to develop and test object recognition systems. They have an organic appearance. (Formats: various formats are available on request)
- Univerity of Minnesota Vision Lab
- El Salvador Atlas of Gastrointestinal VideoEndoscopy - Images and Videos of his-res of studies taken from Gastrointestinal Video endoscopy. (Formats: jpg, mpg, gif)
- FG-NET Facial Aging Database - Database contains 1002 face images showing subjects at different ages. (Formats: jpg)
- FVC2000 Fingerprint Databases - FVC2000 is the First International Competition for Fingerprint Verification Algorithms. Four fingerprint databases constitute the FVC2000 benchmark (3520 fingerprints in all).
- Biometric Systems Lab - University of Bologna
- Face and Gesture images and image sequences - Several image datasets of faces and gestures that are ground truth annotated for benchmarking
- German Fingerspelling Database - The database contains 35 gestures and consists of 1400 image sequences that contain gestures of 20 different persons recorded under non-uniform daylight lighting conditions. (Formats: mpg,jpg)
- Language Processing and Pattern Recognition
- Groningen Natural Image Database - 4000+ 1536x1024 (16 bit) calibrated outdoor images (Formats: homebrew)
- ICG Testhouse sequence - 2 turntable sequences from ifferent viewing heights, 36 images each, resolution 1000x750, color (Formats: PPM)
- Institute of Computer Graphics and Vision
- IEN Image Library - 1000+ images, mostly outdoor sequences (Formats: raw, ppm)
- INRIA's Syntim images database - 15 color image of simple objects (Formats: gif)
- INRIA
- INRIA's Syntim stereo databases - 34 calibrated color stereo pairs (Formats: gif)
- Image Analysis Laboratory - Images obtained from a variety of imaging modalities -- raw CFA images, range images and a host of "medical images". (Formats: homebrew)
- Image Analysis Laboratory
- Image Database - An image database including some textures
- JAFFE Facial Expression Image Database - The JAFFE database consists of 213 images of Japanese female subjects posing 6 basic facial expressions as well as a neutral pose. Ratings on emotion adjectives are also available, free of charge, for research purposes. (Formats: TIFF Grayscale images.)
- ATR Research, Kyoto, Japan
- JISCT Stereo Evaluation - 44 image pairs. These data have been used in an evaluation of stereo analysis, as described in the April 1993 ARPA Image Understanding Workshop paper ``The JISCT Stereo Evaluation'' by R.C.Bolles, H.H.Baker, and M.J.Hannah, 263--274 (Formats: SSI)
- MIT Vision Texture - Image archive (100+ images) (Formats: ppm)
- MIT face images and more - hundreds of images (Formats: homebrew)
- Machine Vision - Images from the textbook by Jain, Kasturi, Schunck (20+ images) (Formats: GIF TIFF)
- Mammography Image Databases - 100 or more images of mammograms with ground truth. Additional images available by request, and links to several other mammography databases are provided. (Formats: homebrew)
- ftp://ftp.cps.msu.edu/pub/prip - many images (Formats: unknown)
- Middlebury Stereo Data Sets with Ground Truth - Six multi-frame stereo data sets of scenes containing planar regions. Each data set contains 9 color images and subpixel-accuracy ground-truth data. (Formats: ppm)
- Middlebury Stereo Vision Research Page - Middlebury College
- Modis Airborne simulator, Gallery and data set - High Altitude Imagery from around the world for environmental modeling in support of NASA EOS program (Formats: JPG and HDF)
- NIST Fingerprint and handwriting - datasets - thousands of images (Formats: unknown)
- NIST Fingerprint data - compressed multipart uuencoded tar file
- NLM HyperDoc Visible Human Project - Color, CAT and MRI image samples - over 30 images (Formats: jpeg)
- National Design Repository - Over 55,000 3D CAD and solid models of (mostly) mechanical/machined engineering designs. (Formats: gif,vrml,wrl,stp,sat)
- Geometric & Intelligent Computing Laboratory
- OSU (MSU) 3D Object Model Database - several sets of 3D object models collected over several years to use in object recognition research (Formats: homebrew, vrml)
- OSU (MSU/WSU) Range Image Database - Hundreds of real and synthetic images (Formats: gif, homebrew)
- OSU/SAMPL Database: Range Images, 3D Models, Stills, Motion Sequences - Over 1000 range images, 3D object models, still images and motion sequences (Formats: gif, ppm, vrml, homebrew)
- Signal Analysis and Machine Perception Laboratory
- Otago Optical Flow Evaluation Sequences - Synthetic and real sequences with machine-readable ground truth optical flow fields, plus tools to generate ground truth for new sequences. (Formats: ppm,tif,homebrew)
- Vision Research Group
- ftp://ftp.limsi.fr/pub/quenot/opflow/testdata/piv/ - Real and synthetic image sequences used for testing a Particle Image Velocimetry application. These images may be used for the test of optical flow and image matching algorithms. (Formats: pgm (raw))
- LIMSI-CNRS/CHM/IMM/vision
- LIMSI-CNRS
- Photometric 3D Surface Texture Database - This is the first 3D texture database which provides both full real surface rotations and registered photometric stereo data (30 textures, 1680 images). (Formats: TIFF)
- SEQUENCES FOR OPTICAL FLOW ANALYSIS (SOFA) - 9 synthetic sequences designed for testing motion analysis applications, including full ground truth of motion and camera parameters. (Formats: gif)
- Computer Vision Group
- Sequences for Flow Based Reconstruction - synthetic sequence for testing structure from motion algorithms (Formats: pgm)
- Stereo Images with Ground Truth Disparity and Occlusion - a small set of synthetic images of a hallway with varying amounts of noise added. Use these images to benchmark your stereo algorithm. (Formats: raw, viff (khoros), or tiff)
- Stuttgart Range Image Database - A collection of synthetic range images taken from high-resolution polygonal models available on the web (Formats: homebrew)
- Department Image Understanding
- The AR Face Database - Contains over 4,000 color images corresponding to 126 people's faces (70 men and 56 women). Frontal views with variations in facial expressions, illumination, and occlusions. (Formats: RAW (RGB 24-bit))
- Purdue Robot Vision Lab
- The MIT-CSAIL Database of Objects and Scenes - Database for testing multiclass object detection and scene recognition algorithms. Over 72,000 images with 2873 annotated frames. More than 50 annotated object classes. (Formats: jpg)
- The RVL SPEC-DB (SPECularity DataBase) - A collection of over 300 real images of 100 objects taken under three different illuminaiton conditions (Diffuse/Ambient/Directed). -- Use these images to test algorithms for detecting and compensating specular highlights in color images. (Formats: TIFF )
- Robot Vision Laboratory
- The Xm2vts database - The XM2VTSDB contains four digital recordings of 295 people taken over a period of four months. This database contains both image and video data of faces.
- Centre for Vision, Speech and Signal Processing
- Traffic Image Sequences and 'Marbled Block' Sequence - thousands of frames of digitized traffic image sequences as well as the 'Marbled Block' sequence (grayscale images) (Formats: GIF)
- IAKS/KOGS
- U Bern Face images - hundreds of images (Formats: Sun rasterfile)
- U Michigan textures (Formats: compressed raw)
- U Oulu wood and knots database - Includes classifications - 1000+ color images (Formats: ppm)
- UCID - an Uncompressed Colour Image Database - a benchmark database for image retrieval with predefined ground truth. (Formats: tiff)
- UMass Vision Image Archive - Large image database with aerial, space, stereo, medical images and more. (Formats: homebrew)
- UNC's 3D image database - many images (Formats: GIF)
- USF Range Image Data with Segmentation Ground Truth - 80 image sets (Formats: Sun rasterimage)
- University of Oulu Physics-based Face Database - contains color images of faces under different illuminants and camera calibration conditions as well as skin spectral reflectance measurements of each person.
- Machine Vision and Media Processing Unit
- University of Oulu Texture Database - Database of 320 surface textures, each captured under three illuminants, six spatial resolutions and nine rotation angles. A set of test suites is also provided so that texture segmentation, classification, and retrieval algorithms can be tested in a standard manner. (Formats: bmp, ras, xv)
- Machine Vision Group
- Usenix face database - Thousands of face images from many different sites (circa 994)
- View Sphere Database - Images of 8 objects seen from many different view points. The view sphere is sampled using a geodesic with 172 images/sphere. Two sets for training and testing are available. (Formats: ppm)
- PRIMA, GRAVIR
- Vision-list Imagery Archive - Many images, many formats
- Wiry Object Recognition Database - Thousands of images of a cart, ladder, stool, bicycle, chairs, and cluttered scenes with ground truth labelings of edges and regions. (Formats: jpg)
- 3D Vision Group
- Yale Face Database - 165 images (15 individuals) with different lighting, expression, and occlusion configurations.
- Yale Face Database B - 5760 single light source images of 10 subjects each seen under 576 viewing conditions (9 poses x 64 illumination conditions). (Formats: PGM)
- Center for Computational Vision and Control
- DeepMind QA Corpus - Textual QA corpus from CNN and DailyMail. More than 300K documents in total. Paper for reference.
- YouTube-8M Dataset - YouTube-8M is a large-scale labeled video dataset that consists of 8 million YouTube video IDs and associated labels from a diverse vocabulary of 4800 visual entities.
- Open Images dataset - Open Images is a dataset of ~9 million URLs to images that have been annotated with labels spanning over 6000 categories.
- Visual Object Classes Challenge 2012 (VOC2012) - VOC2012 dataset containing 12k images with 20 annotated classes for object detection and segmentation.
- Fashion-MNIST - MNIST like fashion product dataset consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes.
- Large-scale Fashion (DeepFashion) Database - Contains over 800,000 diverse fashion images. Each image in this dataset is labeled with 50 categories, 1,000 descriptive attributes, bounding box and clothing landmarks
- FakeNewsCorpus - Contains about 10 million news articles classified using opensources.co types
- databib.org
- datacite.org
- quandl.com - Get the data you need in the form you want; instant download, API or direct to your app.
- figshare.com
- GeoLite Legacy Downloadable Databases
- Quora's Big Datasets Answer
- Public Big Data Sets
- Houston Data Portal
- Kaggle Data Sources
- A Deep Catalog of Human Genetic Variation
- A community-curated database of well-known people, places, and things
- Google Public Data
- World Bank Data
- NYC Taxi data
- Open Data Philly Connecting people with data for Philadelphia
- A list of useful sources A blog post includes many data set databases
- grouplens.org Sample movie (with ratings), book and wiki datasets
- UC Irvine Machine Learning Repository - contains data sets good for machine learning
-
BIS Statistics - BIS statistics, compiled in cooperation with central
-
Blockmodo Coin Registry - A registry of JSON formatted information files
-
Complete FAANG Stock data - This data set contains all the stock data
- Sketches and Strokes from the QuickDraw Game
- GloVe Reddit Comments
- melanoma 2019 orig
- Microsoft Malware Prediction
- LANL Earthquake Prediction
- APTOS 2019 Blindness Detection
- IEEE's Signal Processing Society - Camera Model Identification
- OPENML - An open science datasets for machine learning
- Spoken Language Identification
- COVID19-Engineering-Books-NLP-Dataset
- Lyft 3D Object Detection for Autonomous Vehicles
IPython Notebook(s) demonstrating NumPy functionality.
| Notebook | Description |
|---|---|
| numpy | Adds Python support for large, multi-dimensional arrays and matrices, along with a large library of high-level mathematical functions to operate on these arrays. |
| Introduction-to-NumPy | Introduction to NumPy. |
| Understanding-Data-Types | Learn about data types in Python. |
| The-Basics-Of-NumPy-Arrays | Learn about the basics of NumPy arrays. |
| Computation-on-arrays-ufuncs | Learn about computations on NumPy arrays: universal functions. |
| Computation-on-arrays-aggregates | Learn about aggregations: min, max, and everything in between in NumPy. |
| Computation-on-arrays-broadcasting | Learn about computation on arrays: broadcasting in NumPy. |
| Boolean-Arrays-and-Masks | Learn about comparisons, masks, and boolean logic in NumPy. |
| Fancy-Indexing | Learn about fancy indexing in NumPy. |
| Sorting | Learn about sorting arrays in NumPy. |
| Structured-Data-NumPy | Learn about structured data: NumPy's structured arrays. |
-
41 Essential Machine Learning Interview Questions (with answers)
-
How can a computer science graduate student prepare himself for data scientist interviews?
| Project Name | Stars | Description |
|---|---|---|
| tensorflow | 146k | An Open Source Machine Learning Framework for Everyone |
| keras | 48.9k | Deep Learning for humans |
| opencv | 46.1k | Open Source Computer Vision Library |
| pytorch | 40k | Tensors and Dynamic neural networks in Python with strong GPU acceleration |
| TensorFlow-Examples | 38.1k | TensorFlow Tutorial and Examples for Beginners (support TF v1 & v2) |
| tesseract | 35.3k | Tesseract Open Source OCR Engine (main repository) |
| face_recognition | 35.2k | The world's simplest facial recognition api for Python and the command line |
| faceswap | 31.4k | Deepfakes Software For All |
| transformers | 30.4k | 🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0. |
| 100-Days-Of-ML-Code | 29.1k | 100 Days of ML Coding |
| julia | 28.1k | The Julia Language: A fresh approach to technical computing. |
| awesome-scalability | 26.6k | The Patterns of Scalable, Reliable, and Performant Large-Scale Systems |
| basics | 24.5k | 📚 Learn ML with clean code, simplified math and illustrative visuals. |
| bert | 23.9k | TensorFlow code and pre-trained models for BERT |
| xgboost | 19.4k | Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Flink and DataFlow |
| Real-Time-Voice-Cloning | 18.4k | Clone a voice in 5 seconds to generate arbitrary speech in real-time |
| openpose | 17.8k | OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation |
| Qix | 13.3k | Machine Learning、Deep Learning、PostgreSQL、Distributed System、Node.Js、Golang |
| spleeter | 12.7k | Deezer source separation library including pretrained models. |
| Virgilio | 12.7k | Your new Mentor for Data Science E-Learning. |
-
Difference between logit and probit models, Logistic Regression Wiki, Probit Model Wiki
-
Pseudo R2 for Logistic Regression, How to calculate, Other Details
- Stanford CS 231N - CNNs
- Stanford CS 224D - Deep Learning for NLP
- Hugo Larochelle's Neural Networks Course
- David Silver's Reinforcement Learning Course
- Andrew Ng Machine Learning Course
- Stanford CS 229 - Pretty much the same as the Coursera course
- UC Berkeley Kaggle Decal
- Short MIT Intro to DL Course
- Udacity Deep Learning
- Deep Learning School Montreal 2016 and 2017
- Intro to Neural Nets and ML (Univ of Toronto)
- Deep RL Bootcamp
- CMU Neural Networks for NLP
- Bay Area Deep Learning School Day 1 2016 and Day 2
- Introduction to Deep Learning MIT Course
- Caltech CS 156 - Machine Learning
- Berkeley EE 227C - Convex Optimization
- Upskilling from Home · Data Crunch Corporation
- O’Reilly Data Show Podcast – O’Reilly
- Introduction · Data Skeptic
- Spotify – Data Stories | Podcast on Spotify
- Spotify – DataFramed | Podcast on Spotify
- Hunting for the Higgs · Linear Digressions
- Spotify – Not So Standard Deviations | Podcast on Spotify
- Spotify – Making Data Simple | Podcast on Spotify
- Spotify – Data Engineering Podcast | Podcast on Spotify
- Spotify – SuperDataScience | Podcast on Spotify
- Spotify – Data Science at Home | Podcast on Spotify
- Spotify – The Digital Analytics Power Hour | Podcast on Spotify
- Home - HumAIn Podcast
- Spotify – HumAIn Podcast - Artificial Intelligence, Data Science, and Developer Education | Podcast on Spotify
- Let's Reflect · Talking Machines
- Spotify – The TWIML AI Podcast (formerly This Week in Machine Learning & Artificial Intelligence) | Podcast on Spotify
- Spotify – Lex Fridman Podcast | Artificial Intelligence (AI) | Podcast on Spotify
- AI Today Podcast: The 2020 State of AI – Interview with Wilson Pang, CTO at Appen · AI Today Podcast: Artificial Intelligence Insights, Experts, and Opinion
- Spotify – AI in Business | Podcast on Spotify
Some of papers thought to be influential in getting deep learning ecosystem. I further added a couple important general ML papers to these list.
- AlexNet
- GoogLeNet
- VGGNet
- ZFNet
- ResNet
- R-CNN
- Fast R-CNN
- Adversarial Images
- Generative Adversarial Networks
- Spatial Transformer Networks
- DCGAN
- Synthetic Gradients
- Memory Networks
- Mixture of Experts
- Neural Turing Machines
- Alpha Go
- Atari DQN
- Word2Vec
- GloVe
- A3C
- Gradient Descent by Gradient Descent
- Rethinking Generalization
- Densely Connected CNNs
- EBGAN
- Wasserstein GAN
- Style Transfer
- Pixel RNN
- Dynamic Coattention Networks
- Convolutional Seq2Seq Learning
- Seq2Seq
- Dropout
- Batch Norm
- Large Batch Training
- Transfer Learning
- Adam
- Speech Recognition
- Relational Networks
- Influence Functions
- ReLu
- Xavier Initialization
- Saddle Points and Non-convexity of Neural Networks
- Overcoming Catastrophic Forgetting in NNs
- Quasi-Recurrent Neural Networks
- Escaping Saddle Points Efficiently
- Progressive Growing of GANs
- Attention is All You Need
- Dynamic Routing Between Capsules
- Unsupervised Machine Translation with Monolingual Corpora
- Population Based Training of NN's
- Learned Index Structures
- Visualizing Loss Landscapes
- DenseNet
- SqueezeNet
- WaveNet
- Hidden Technical Debt in ML Systems
- MobileNets
- Learning from Imbalanced Data
- deep-learning-glossary/
- deep-learning-roadmap
- awesome-deep-learning
- Awesome - Most Cited Deep Learning Papers
- Udacity's Deep Learning Nanodegree Foundation program
- [Berkeley]cs294: deep reinforcement learning
- [Berkeley]stat212b:topics course on deep learning
- [CUHK]eleg 5040: advanced topics in signal processing(introduction to deep learning)
- [CMU]deep reinforcement learning and control
- [CMU]neural networks for nlp
- UFLDL Tutorial 1
- UFLDL Tutorial 2 Deep Learning for NLP (without Magic)
- A Deep Learning Tutorial: From Perceptrons to Deep Networks
- Deep Learning from the Bottom up
- Theano Tutorial
- TensorFlow tutorials Deep Learning with R in Motion
- Grokking Deep Learning in Motion
- Machine Learning, Data Science and Deep Learning with Python
- 15 AI and Machine Learning Events
- 188 examples of artificial intelligence in action
- A curated list of automated machine learning papers, articles, tutorials, slides and projects
- A curated list of awesome places to learn and/or practice algorithms.
- A curated list of awesome SLAM tutorials, projects and communities.
- A curated list of resources dedicated to bridge between coginitive science and deep learning
- A curated list of resources dedicated to Natural Language Processing (NLP)
- A curated list of resources for NLP (Natural Language Processing) for Chinese
- Another curated list of deep learning resources
- A list of artificial intelligence tools you can use today
- A list of deep learning implementations in biology
- Awesome-2vec
- Awesome Action Recognition
-
Bing Coronavirus
- Classify Bing Queries as either specific (e.g. about a specific location) or generic. You might have to figure out a more exact definition of specific or generic though
- Dataset: BingCoronavirusQuerySet
-
Covid Clinical Data
- Rank and sort high risk patients using clinical data. Pick an interpretable approach if you can.
- Dataset: CovidClinicalData
If you haven't already, checkout Kaggle's Covid19 Section as well. It has datasets and ideas both.
-
Autonomous Tagging of StackOverflow Questions
- Make a multi-label classification system that automatically assigns tags for questions posted on a forum such as StackOverflow or Quora.
- Dataset: StackLite or 10% sample
-
Keyword/Concept identification
- Identify keywords from millions of questions
- Dataset: StackOverflow question samples by Facebook
-
Topic identification
- Multi-label classification of printed media articles to topics
- Dataset: Greek Media monitoring multi-label classification
- Automated essay grading
- The purpose of this project is to implement and train machine learning algorithms to automatically assess and grade essay responses.
- Dataset: Essays with human graded scores
- Sentence to Sentence semantic similarity
- Can you identify question pairs that have the same intent or meaning?
- Dataset: Quora question pairs with similar questions marked
-
Fight online abuse
- Can you confidently and accurately tell whether a particular comment is abusive?
- Dataset: Toxic comments on Kaggle
-
Open Domain question answering
- Can you build a bot which answers questions according to the student's age or her curriculum?
- Facebook's FAIR is built in a similar way for Wikipedia.
- Dataset: NCERT books for K-12/school students in India, NarrativeQA by Google DeepMind and SQuAD by Stanford
- Social Chat/Conversational Bots
- Can you build a bot which talks to you just like people talk on social networking sites?
- Reference: Chat-bot architecture
- Dataset: Reddit Dataset
- Automatic text summarization
- Can you create a summary with the major points of the original document?
- Abstractive (write your own summary) and Extractive (select pieces of text from original) are two popular approaches
- Dataset: CNN and DailyMail News Pieces by Google DeepMind
- Copy-cat Bot
- Generate plausible new text which looks like some other text
- Obama Speeches? For instance, you can create a bot which writes some new speeches in Obama's style
- Trump Bot? Or a Twitter bot which mimics @realDonaldTrump
- Narendra Modi bot saying "doston"? Start by scrapping off his Hindi speeches from his personal website
- Example Dataset: English Transcript of Modi speeches
Check mlm/blog for some hints.
- Sentiment Analysis
- Do Twitter Sentiment Analysis on tweets sorted by geography and timestamp.
- Dataset: Tweets sentiment tagged by humans
- De-anonymization
- Can you classify the text of an e-mail message to decide who sent it?
- Dataset: 150,000 Enron emails
- Univariate Time Series Forecasting
- How much will it rain this year?
- Dataset: 45 years of rainfall data
- Multi-variate Time Series Forecasting
- How polluted will your town's air be? Pollution Level Forecasting
- Dataset: Air Quality dataset
- Demand/load forecasting
- Find a short term forecast on electricity consumption of a single home
- Dataset: Electricity consumption of a household
- Predict Blood Donation
- We're interested in predicting if a blood donor will donate within a given time window.
- More on the problem statement at Driven Data.
- Dataset: UCI ML Datasets Repo
- Movie Recommender
- Can you predict the rating a user will give on a movie?
- Do this using the movies that user has rated in the past, as well as the ratings similar users have given similar movies.
- Dataset: Netflix Prize and MovieLens Datasets
- Search + Recommendation System
- Predict which Xbox game a visitor will be most interested in based on their search query
- Dataset: BestBuy
- Can you predict Influencers in the Social Network?
- How can you predict social influencers?
- Dataset: PeerIndex
Classification :
- Titanic (Can't miss it :) ) : https://www.kaggle.com/c/titanic
- Forest Cover Type Prediction (Late Submission): https://www.kaggle.com/c/forest-cover-type-prediction
- Don't Overfit 2 (Late Submission): https://www.kaggle.com/c/dont-overfit-ii
- CareerCon 2019 (Late Submission)(Multiclass): https://www.kaggle.com/c/career-con-2019
- IEEE-CIS Fraud Detection (Late Submission): https://www.kaggle.com/c/ieee-fraud-detection
- Instant Gratification (Late Submission): https://www.kaggle.com/c/instant-gratification
- Categorical Feature Encoding Challenge (Late Submission): https://www.kaggle.com/c/cat-in-the-dat
- University of Liverpool - Ion Switching (Late Submission): https://www.kaggle.com/c/liverpool-ion-switching
Binary Classification Tips and tricks
- House Prices (Ongoing): https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- Bike Sharing Demand (Late Submission): https://www.kaggle.com/c/bike-sharing-demand/data
- Predict Future Sales (Ongoing)(Time Series): https://www.kaggle.com/c/competitive-data-science-predict-future-sales
- TMDB Box Office Prediction (Late Submission): https://www.kaggle.com/c/tmdb-box-office-prediction
- ASHRAE - Great Energy Predictor III (Late Submission): https://www.kaggle.com/c/ashrae-energy-prediction/
Computer Vision :
- Jigsaw Toxic Comment Classification Challenge (Late Submission): https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
- Jigsaw Unintended Bias in Toxicity Classification (Late Submission): https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification
- Jigsaw Multilingual Toxic Comment Classification (Late Submission): https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification
- Real or Not? NLP with Disaster Tweets (Ongoing): https://www.kaggle.com/c/nlp-getting-started
- Word2Vec for movie reviews (Late Submission): https://www.kaggle.com/c/word2vec-nlp-tutorial
- Random Acts of Pizza (Late Submission): https://www.kaggle.com/c/random-acts-of-pizza
- Sentiment Analysis movies review (Late Submission): https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews
- Quora questions classification (Late Submission): https://www.kaggle.com/c/quora-insincere-questions-classification
- Top Computer Vision Google Colab Notebooks
Data preparation
After data exploration, the first thing to do is to use those insights to prepare the data. To tackle issues like class imbalance, encoding categorical data, etc. Let’s see the methods used to do it.
- Methods to tackle class imbalance.
- Data augmentation by Synthetic Minority Oversampling Technique.
- Fast inplace shuffle for augmentation.
- Finding synthetic samples in the dataset.
- Signal denoising used in signal processing competitions.
- Finding patterns of missing data.
- Methods to handle missing data.
- An overview of various encoding techniques for categorical data.
- Building model to predict missing values.
- Random shuffling of data to create new synthetic training set.
Dealing with larger datasets
One issue you might face in any machine learning competition is the size of your data set. If the size of your data is large, that is 3GB + for kaggle kernels and more basic laptops you could find it difficult to load and process with limited resources. Here is the link to some of the articles and kernels that may be very useful in such situations.
- Faster data loading with pandas.
- Data compression techniques to reduce the size of data by 70%.
- Optimize the memory by reducing the size of some attributes.
- Use open-source libraries such as Dask to read and manipulate the data, it performs parallel computing and saves up memory space.
- Use cudf.
- Convert data to parquet format.
- Converting data to feather format.
- Reducing memory usage for optimizing RAM.
Data exploration
Data exploration always helps to better understand the data and gain insights from it. Before starting to develop machine learning models, top competitors always read/do a lot of exploratory data analysis for the data. This helps in feature engineering and cleaning of the data.
- EDA for microsoft malware detection.
- Time Series EDA for malware detection.
- Complete EDA for home credit loan prediction.
- Complete EDA for Santader prediction.
- EDA for VSB Power Line Fault Detection.
Feature engineering
Next, you can check the most popular feature and feature engineering techniques used in these top kaggle competitions.
- Target encoding cross validation for better encoding.
- Entity embedding to handle categories.
- Encoding cyclic features for deep learning.
- Manual feature engineering methods.
- Automated feature engineering techniques using featuretools.
- Top hard crafted features used in microsoft malware detection.
- Denoising NN for feature extraction.
- Feature engineering using RAPIDS framework.
- Things to remember while processing features using LGBM.
- Lag features and moving averages.
- Principal component analysis for dimensionality reduction.
- LDA for dimensionality reduction.
- Best hand crafted LGBM features for microsoft malware detection.
- Generating frequency features.
- Dropping variables with different train and test distribution.
- Aggregate time series features for home credit competition.
- Time Series features used in home credit default risk.
- Scale, Standardize and normalize with sklearn.
- Handcrafted features for Home default risk competition.
- Handcrafted features used in Santander Transaction Prediction.
Feature selection
After generating many features from your data, you need to decide which all features to use in your model to get the maximum performance out of your model. This step also includes identifying the impact each feature is having on your model. Let’s see some of the most popular feature selection methods.
- Six ways to do features selection using sklearn.
- Permutation feature importance.
- Adversarial feature validation.
- Feature selection using null importances.
- Tree explainer using SHAP.
- DeepNN explainer using SHAP.
Modeling
After handcrafting and selecting your features, you should choose the right Machine learning algorithm to make your prediction. These are the collection of some of the most used ML models in structured data classification challenges.
- Random forest classifier.
- XGBoost : Gradient boosted decision trees.
- LightGBM for distributed and faster training.
- CatBoost to handle categorical data.
- Naive bayes classifier.
- Gaussian naive bayes model.
- LGBM + CNN model used in 3rd place solution of Santander Customer Transaction Prediction
- Knowledge distillation in Neural Network.
- Follow the regularized leader method.
- Comparison between LGB boosting methods (goss, gbdt and dart).
- NN + focal loss experiment.
- Keras NN with timeseries splitter.
- 5th place NN architecture with code for Santander Transaction prediction.