#Welcome
Data provenance - information about entities, activities, and people involved in producing a piece of data or thing - is becoming a crucial component in information systems. Whether it's the version history of software ((like github) or maintaining attribution as documents are created (think CC-BY), provenance is becoming widely available.
To help work with provenance coming from multiple different systems, the W3C specified a common model and serializations for provenance, PROV.
The aim of this tutorial is to provide a hands-on introduction to PROV by working with provenance from existing sources. Concretely, you will (hopefully):
- learn the core concepts of PROV;
- obtain provenance from existing data sources;
- query PROV provenance;
- using multiple PROV serializations.
This tutorial is primarily focused on working with provenance from the web in a hands on fashion. The tutorial builds on a number of existing resources:
- Provenance: An Introduction to PROV - a book about PROV by myself and Luc Moreau.
- Tutorials focused on the PROV model introducing it:
- IPAW 2014 - from a UML perspective;
- ESWC 2013- from a semantic web perspective;
- EDBT 2014 - from a relational perspective.
- Provenance Techniques for CRUD - from a web app perspective
- PROV Python tutorial
#Prerequisites
The tutorial assumes:
- Working with the unix command line
- Familiarity with RDF and SPARQL
- Familiarity with git
##Installation The tutorial assumes that you have a unix environment (Mac OSX or Linus) and a number of installed packages. To make it easy to get started I've packaged all the necessary components into virtual machine deployable using vagrant.
Let's get started!
- Install the Virtual Box virtualization software for your platform.
- Install vagrant
Clone the repository and move to the PROVTutorial directory
$ git clone https://github.com/pgroth/PROVTutorial.git
$ cd PROVTutorial
Instantiate the virtual machine. This might take a while.
$ vagrant up
Once established you can connect to the virtual machine
$ vagrant ssh
Note that the virtual machine shares the PROVTutorial directory under the /vagrant directory. This allows you to move between your machine and another.
To logout of the VM, just type exit
$ exit
For more commands for using vagrant see their documentation.
The VM has installed the following packages and dependencies:
The VM also sets the appropriate environment variables.l
The figure below (taken from the PROV Primer) shows the 3 core classes of PROV and how they are related. The PROV Primer provides more details and a working example. Here, we'll go with the basics so we can start querying datasets.
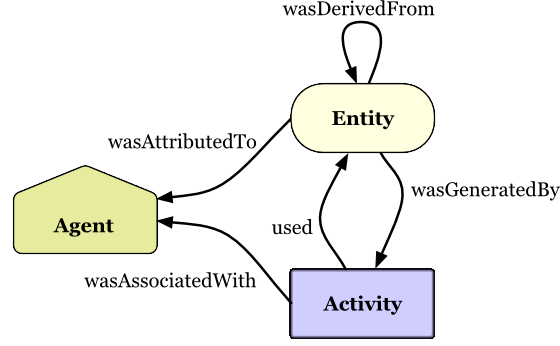
These three classes correspond to three views of provenance.
-
The data flow view helps us represent the flow of information within a system. Entities are the things we want to describe the provenance of (
prov:Entity). Entities are derived from other entities (prov:wasDerivedFrom). For example, within a version control system, we would describe that each revision as an entity and the newer version was derived from the older revision. e.g.:newer prov:wasRevisionOf :older -
The process flow view helps us represent the processes that took place in a system and associated timing.
prov:Activitydenotes these processes. Activities are related to the information (i.e. entities) they take as input and generate as output. Represented respectively byprov:usedandprov:wasGeneratedBy. For example, we might have a program such as curl take some input (a url) and generate some output (a downloaded web page). -
The responsibility view helps us represent the assignment of responsibility in a system. Entities or activities that are assigned responsibility are denoted as
prov:Agent.For example, a person, Bob, might be responsible for a particular web page. The web page's attribution is written as:webpage prov:wasAttributedTo :bob. Similarly, the activity of web page creation might also be Bob's responsibility written as:bob prov:wasAssociatedWith :webPageCreation
With these core concepts, let's run some simple queries over the example from the PROV Primer about a the provenance of an online newspaper article. We've made available the turtle file in this repository.
Before querying, let's first get a visual overview of the example. To do this will use provconvert
$ cd /vagrant
$ provconvert -infile primer-example.ttl -outfile primer-example.svg
You can now view the svg of the example in your browser.
Similarly, you can make a pdf
$ provconvert -infile primer-example.ttl -outfile primer-example.pdf
More importantly, you can convert to other serializations/file formats like JSON.
$ provconvert -infile primer-example.ttl -outfile primer-example.json
This is an important design decision behind PROV. It always one to interchange provenance between different common web formats.
Now that we have a view of the example, let's see what we can access. Will look at the data flow of the example. First, we'll find all the entities using SPARQL.
$ roqet -i sparql -e 'select ?s where {?s a <http://www.w3.org/ns/prov#Entity>}' -r csv --data primer-example.ttl
Let's now find which entities were derived from other entities.
$ roqet -i sparql -e 'select ?e2 ?e1 where {?e2 <http://www.w3.org/ns/prov#wasDerivedFrom> ?e1 .}' -r csv --data primer-example.ttl
The results are surprising. Only two results are returned. PROV includes a number of sub-properties of prov:wasDerivedForm so we need to query for those as well (or use an inference engine). For example, we could find all the revisions in the dataset.
$ roqet -i sparql -e 'select ?e2 ?e1 where {?e2 <http://www.w3.org/ns/prov#wasRevisionOf> ?e1 .}' -r csv --data primer-example.ttl
There are a number of interesting things to try out on this example:
- Can you compose queries for the responsibility and process flow views?
- Can you use SPARQL to walk back through the chain of derivation edges? (note this is not possible using roqet)
- What queries can you write with or without having knowledge of the data?
Let's expand this to using some data from the web to show how having a common language can help us write some interesting queries.
DBPedia extracts structured data from Wikipedia. As a good web citizen they document which wikipedia pages particular dbpedia pages are extracted from using PROV.
Let's first grab the a Turtle version of the dbpedia page for Amsterdam
$ cd ~/
$ curl -sH "Accept: text/turtle" -L http://dbpedia.org/resource/Amsterdam > adam.ttl
We can find the corresponding web page using the prov:wasDerivedFrom relation as before.
$ roqet -i sparql -e 'select ?o where {?s <http://www.w3.org/ns/prov#wasDerivedFrom> ?o}' -r csv --data adam.ttl
The results of that query give us a wikipedia page url: http://en.wikipedia.org/wiki/Amsterdam?oldid=548577509
We can use the wikipedia-provenance tool to convert the revision history of the page into PROV. The following command retrieves the last 10 revisions starting at the given revision start id.
$ java -jar ./wikipedia-provenance/target/wikipedia-provenance-0.0.5-jar-with-dependencies.jar -startid 548577509 -o . -pAmsterdam -r 10
With the output, using queries like the ones we've seen before we can extract who's involved in creating the Amsterdam wiki page (the responsibility view).
$ roqet -i sparql -e 'select * where {?s a <http://www.w3.org/ns/prov#Agent>. ?s ?p ?o}' -r csv --data Amsterdam-startid548577509-r10-u1-d1.ttl
This demonstrates that by using a common model for provenance, we can write historical queries that extend beyond the reach beyond one data source. This is particularly important when dealing with data on the web as it often involves munging data from multiple sources.
- What other kinds of queries can we write against these two data sets?
- This dataset is rather large to visualize, could you extract a subset that can be visualized as a graph?
As we saw in the previous section, by expressing provenance information using a common model, we can use the same constructs to query over provenance from different data sources. In this section, we will apply our provenance to github - version histories for software.
Here we'll use git2prov to convert this PROVTutorial repository to PROV.
$ git2prov https://github.com/pgroth/PROVTutorial.git PROV-O > provtutorial-git.ttl
Let's use the same query that we used with the wikipedia datasets to get all the agents involved:
$ roqet -i sparql -e 'select * where {?s a <http://www.w3.org/ns/prov#Agent>. ?s ?p ?o}' -r csv --data provtutorial-git.ttl
Let's do something more complicated. Let's find all the commits and their associated labels:
$ roqet -i sparql -e 'select * where {?s a <http://www.w3.org/ns/prov#Activity>. ?s <http://www.w3.org/2000/01/rdf-schema#label> ?o}' -r csv --data provtutorial-git.ttl
- What kind of queries would it be useful to run over source code version histories?
You can also experiment with git2prov interactively. Run:
$ git2prov-server
On your local machine navigate to localhost:8080
In the GIT Repo field, enter the PROVTutorial github url. Click PROV-JSON
Let's take a look at this in a json editor. (An online one is available at http://www.jsoneditoronline.org)
An interesting thing here is that you can now use this an input to a web visualization tool or to work with programming languages that have JSON support.
- What are some constructs of interest or that you are curious about? Can you figure out their usage and what they are for?
All the constructs of PROV are defined in an open namespace. If you navigate to http://www.w3.org/ns/prov - you'll see how the terms that are defined by PROV, their English language definition, and links to their definition in the various specs.
One nice thing is that the same page is also available in computer parsable formats through content negotiation. You can grab the XSD and OWL definitions of PROV from this page. Try it out by doing:
$ curl -sH "Accept: application/xml" -L http://www.w3.org/ns/prov
- The tutorials and books above can give you more background on the language and uses for the various constructs.
- If you're interested in programming with PROV, I suggest the PROV Python Short Tutorial by Trung Dong Huynh
- For java fans: the PROV toolbox (installed with the VM) provides a whole API for dealing with PROV
- The Provenance Store provides a nice API for storing and retriving provenance.
Here are some current ideas for projects to do with provenance:
- Extend NoWorkflow to export PROV
- Do something cool with the provenance for the National Climate Change Assessment 2014.
- Do something cool with the Gazette's - the UK's public record - provenance. Checkout this blog post and the DevDocs
prov:wasAttributedTo Paul Groth
This project was supported by the Dutch national programme COMMIT in the Data2Semantics project .