Install from master branch (if you want to try the latest features):
git clone https://github.com/lalitpagaria/obsei.git
cd obsei
pip install --editable .
Step 3: Configure Source/Observer
Twitter
fromobsei.source.twitter_sourceimportTwitterCredentials, TwitterSource, TwitterSourceConfig# initialize twitter source configsource_config=TwitterSourceConfig(
keywords=["issue"], # Keywords, @user or #hashtagslookup_period="1h", # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)credential=TwitterCredentials(
# Enter your twitter consumer key and secret. Get it from https://developer.twitter.com/en/apply-for-accessconsumer_key="<twitter_consumer_key>",
consumer_secret="<twitter_consumer_secret>"
)
)
# initialize tweets retrieversource=TwitterSource()
Email
fromobsei.source.email_sourceimportEmailConfig, EmailCredInfo, EmailSource# initialize email source configsource_config=EmailConfig(
# List of IMAP servers for most commonly used email providers# https://www.systoolsgroup.com/imap/# Also, if you're using a Gmail account then make sure you allow less secure apps on your account -# https://myaccount.google.com/lesssecureapps?pli=1# Also enable IMAP access -# https://mail.google.com/mail/u/0/#settings/fwdandpopimap_server="imap.gmail.com", # Enter IMAP servercred_info=EmailCredInfo(
# Enter your email account username and passwordusername="<email_username>",
password="<email_password>"
),
lookup_period="1h"# Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
)
# initialize email retrieversource=EmailSource()
AppStore Reviews Scrapper
fromobsei.source.appstore_scrapperimportAppStoreScrapperConfig, AppStoreScrapperSource# initialize app store source configsource_config=AppStoreScrapperConfig(
# Need two parameters app_id and country. # `app_id` can be found at the end of the url of app in app store. # For example - https://apps.apple.com/us/app/xcode/id497799835# `310633997` is the app_id for xcode and `us` is country.countries=["us"],
app_id="310633997",
lookup_period="1h"# Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
)
# initialize app store reviews retrieversource=AppStoreScrapperSource()
Play Store Reviews Scrapper
fromobsei.source.playstore_scrapperimportPlayStoreScrapperConfig, PlayStoreScrapperSource# initialize play store source configsource_config=PlayStoreScrapperConfig(
# Need two parameters package_name and country. # `package_name` can be found at the end of the url of app in play store. # For example - https://play.google.com/store/apps/details?id=com.google.android.gm&hl=en&gl=US# `com.google.android.gm` is the package_name for xcode and `us` is country.countries=["us"],
package_name="com.google.android.gm",
lookup_period="1h"# Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
)
# initialize play store reviews retrieversource=PlayStoreScrapperSource()
Reddit
fromobsei.source.reddit_sourceimportRedditConfig, RedditSource, RedditCredInfo# initialize reddit source configsource_config=RedditConfig(
subreddits=["wallstreetbets"], # List of subreddits# Reddit account username and password# You can also enter reddit client_id and client_secret or refresh_token# Create credential at https://www.reddit.com/prefs/apps# Also refer https://praw.readthedocs.io/en/latest/getting_started/authentication.html# Currently Password Flow, Read Only Mode and Saved Refresh Token Mode are supportedcred_info=RedditCredInfo(
username="<reddit_username>",
password="<reddit_password>"
),
lookup_period="1h"# Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
)
# initialize reddit retrieversource=RedditSource()
Reddit Scrapper
Note: Reddit heavily rate limit scrappers, hence use it to fetch small data during long period
fromobsei.source.reddit_scrapperimportRedditScrapperConfig, RedditScrapperSource# initialize reddit scrapper source configsource_config=RedditScrapperConfig(
# Reddit subreddit, search etc rss url. For proper url refer following link -# Refer https://www.reddit.com/r/pathogendavid/comments/tv8m9/pathogendavids_guide_to_rss_and_reddit/url="https://www.reddit.com/r/wallstreetbets/comments/.rss?sort=new",
lookup_period="1h"# Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
)
# initialize reddit retrieversource=RedditScrapperSource()
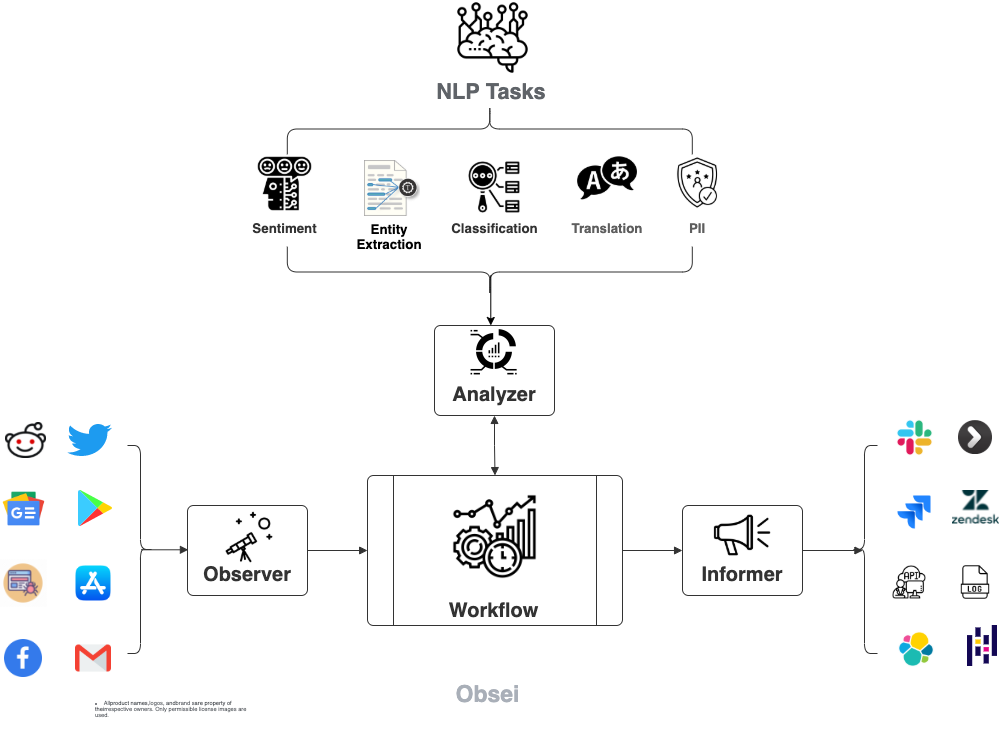
Text classification, classify text into user provided categories.
fromobsei.analyzer.classification_analyzerimportClassificationAnalyzerConfig, ZeroShotClassificationAnalyzer# initialize classification analyzer config# It can also detect sentiments if "positive" and "negative" labels are added.analyzer_config=ClassificationAnalyzerConfig(
labels=["service", "delay", "performance"],
)
# initialize classification analyzer# For supported models refer https://huggingface.co/models?filter=zero-shot-classificationtext_analyzer=ZeroShotClassificationAnalyzer(
model_name_or_path="joeddav/bart-large-mnli-yahoo-answers"
)
Sentiment Analyzer
Sentiment Analyzer, detect the sentiment of the text. Text classification can also perform sentiment analysis but if you don't want to use heavy-duty NLP model then use less resource hungry dictionary based Vader Sentiment detector.
fromobsei.analyzer.sentiment_analyzerimportVaderSentimentAnalyzer# Vader does not need any configuration settingsanalyzer_config=None# initialize vader sentiment analyzertext_analyzer=VaderSentimentAnalyzer()
NER Analyzer
NER (Named-Entity Recognition) Analyzer, extract information and classify named entities mentioned in text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc
fromobsei.analyzer.ner_analyzerimportNERAnalyzer# NER analyzer does not need configuration settingsanalyzer_config=None# initialize ner analyzer# For supported models refer https://huggingface.co/models?filter=token-classificationtext_analyzer=NERAnalyzer(
model_name_or_path="elastic/distilbert-base-cased-finetuned-conll03-english"
)
Translator
fromobsei.analyzer.translation_analyzerimportTranslationAnalyzer# Translator does not need analyzer configanalyzer_config=None# initialize translator# For supported models refer https://huggingface.co/models?pipeline_tag=translationanalyzer=TranslationAnalyzer(
model_name_or_path="Helsinki-NLP/opus-mt-hi-en"
)
PII Anonymizer
fromobsei.analyzer.pii_analyzerimportPresidioEngineConfig, PresidioModelConfig, \
PresidioPIIAnalyzer, PresidioPIIAnalyzerConfig# initialize pii analyzer's configanalyzer_config=PresidioPIIAnalyzerConfig(
# Whether to return only pii analysis or anonymize textanalyze_only=False,
# Whether to return detail information about anonymization decisionreturn_decision_process=True
)
# initialize pii analyzeranalyzer=PresidioPIIAnalyzer(
engine_config=PresidioEngineConfig(
# spacy and stanza nlp engines are supported# For more info refer # https://microsoft.github.io/presidio/analyzer/developing_recognizers/#utilize-spacy-or-stanzanlp_engine_name="spacy",
# Update desired spacy model and languagemodels=[PresidioModelConfig(model_name="en_core_web_lg", lang_code="en")]
)
)
Dummy Analyzer
Dummy Analyzer, do nothing it simply used for transforming input (AnalyzerRequest) to output (AnalyzerResponse) also adding user supplied dummy data.
fromobsei.sink.slack_sinkimportSlackSink, SlackSinkConfig# initialize slack sink configsink_config=SlackSinkConfig(
# Provide slack bot/app token# For more detail refer https://slack.com/intl/en-de/help/articles/215770388-Create-and-regenerate-API-tokensslack_token="<Slack_app_token>",
# To get channel id refer https://stackoverflow.com/questions/40940327/what-is-the-simplest-way-to-find-a-slack-team-id-and-a-channel-idchannel_id="C01LRS6CT9Q"
)
# initialize slack sinksink=SlackSink()
Zendesk
fromobsei.sink.zendesk_sinkimportZendeskSink, ZendeskSinkConfig, ZendeskCredInfo# initialize zendesk sink configsink_config=ZendeskSinkConfig(
# For custom domain refer http://docs.facetoe.com.au/zenpy.html#custom-domains# Mainly you can do this by setting the environment variables:# ZENPY_FORCE_NETLOC# ZENPY_FORCE_SCHEME (default to https)# when set it will force request on:# {scheme}://{netloc}/endpoint# provide zendesk domaindomain="zendesk.com",
# provide subdomain if you have onesubdomain=None,
# Enter zendesk user detailscred_info=ZendeskCredInfo(
email="<zendesk_user_email>",
password="<zendesk_password>"
)
)
# initialize zendesk sinksink=ZendeskSink()
Jira
fromobsei.sink.jira_sinkimportJiraSink, JiraSinkConfig# For testing purpose you can start jira server locally# Refer https://developer.atlassian.com/server/framework/atlassian-sdk/atlas-run-standalone/# initialize Jira sink configsink_config=JiraSinkConfig(
url="http://localhost:2990/jira", # Jira server url# Jira username & password for user who have permission to create issueusername="<username>",
password="<password>",
# Which type of issue to be created# For more information refer https://support.atlassian.com/jira-cloud-administration/docs/what-are-issue-types/issue_type={"name": "Task"},
# Under which project issue to be created# For more information refer https://support.atlassian.com/jira-software-cloud/docs/what-is-a-jira-software-project/project={"key": "CUS"},
)
# initialize Jira sinksink=JiraSink()
ElasticSearch
fromobsei.sink.elasticsearch_sinkimportElasticSearchSink, ElasticSearchSinkConfig# For testing purpose you can start Elasticsearch server locally via docker# `docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.2`# initialize Elasticsearch sink configsink_config=ElasticSearchSinkConfig(
# Elasticsearch server hostnamehost="localhost",
# Elasticsearch server portport=9200,
# Index name, it will create if not existindex_name="test",
)
# initialize Elasticsearch sinksink=ElasticSearchSink()
Http
fromobsei.sink.http_sinkimportHttpSink, HttpSinkConfig# For testing purpose you can create mock http server via postman# For more details refer https://learning.postman.com/docs/designing-and-developing-your-api/mocking-data/setting-up-mock/# initialize http sink config (Currently only POST call is supported)sink_config=HttpSinkConfig(
# provide http server urlurl="https://localhost:8080/api/path",
# Here you can add headers you would like to pass with requestheaders={
"Content-type": "application/json"
}
)
# To modify or converting the payload, create convertor class# Refer obsei.sink.dailyget_sink.PayloadConvertor for example# initialize http sinksink=HttpSink()
Logger
This is useful for testing and dry run checking of pipeline.
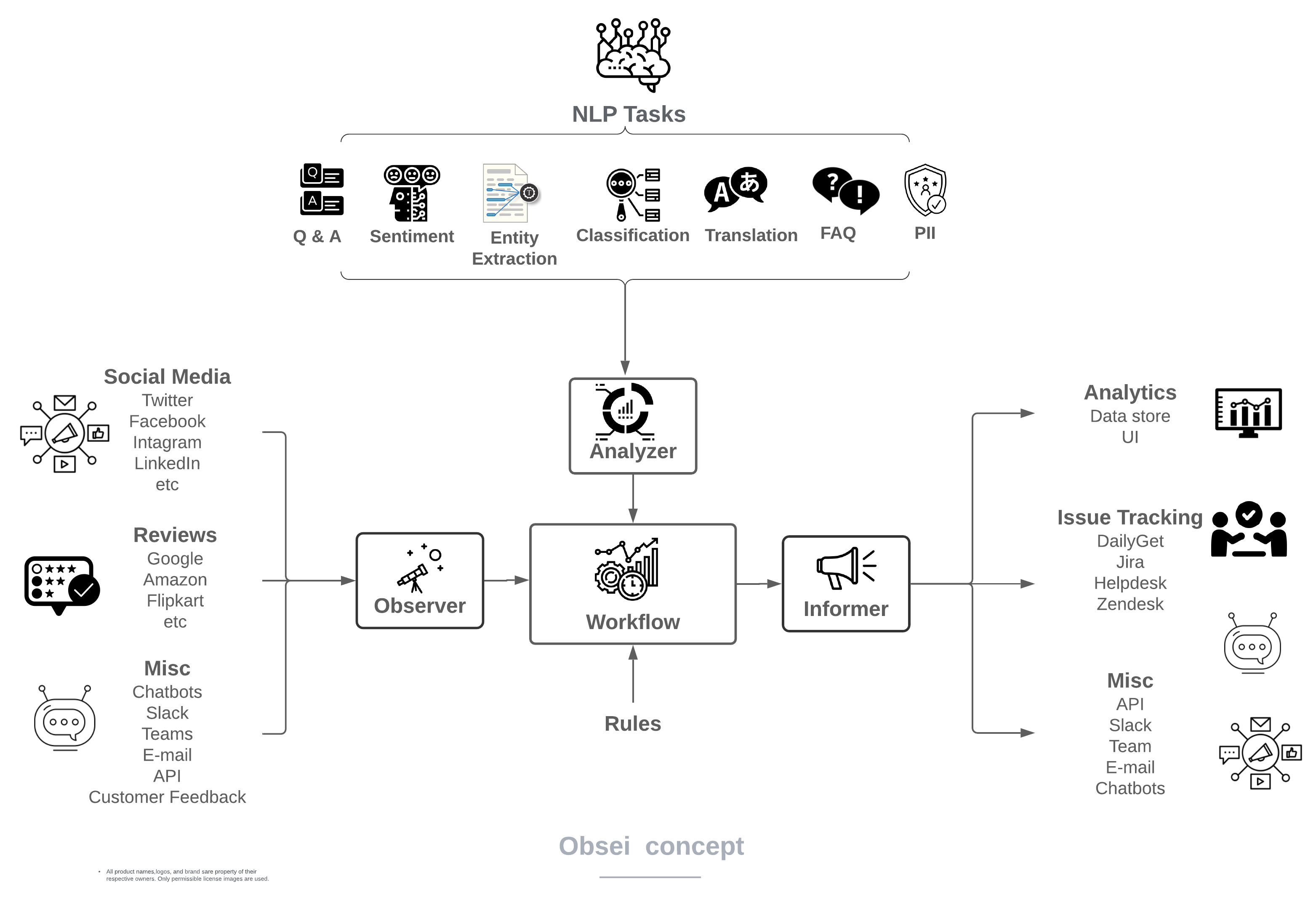
source will fetch data from selected the source, then feed that to analyzer for processing, whose output we feed into sink to get notified at that sink.
# Uncomment if you want logger# import logging# import sys# logger = logging.getLogger(__name__)# logging.basicConfig(stream=sys.stdout, level=logging.INFO)# This will fetch information from configured source ie twitter, app store etcsource_response_list=source.lookup(source_config)
# Uncomment if you want to log source response# for idx, source_response in enumerate(source_response_list):# logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")# This will execute analyzer (Sentiment, classification etc) on source data with provided analyzer_configanalyzer_response_list=text_analyzer.analyze_input(
source_response_list=source_response_list,
analyzer_config=analyzer_config
)
# Uncomment if you want to log analyzer response# for idx, an_response in enumerate(analyzer_response_list):# logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")# Analyzer output added to segmented_data# Uncomment inorder to log it# for idx, an_response in enumerate(analyzer_response_list):# logger.info(f"analyzed_data#'{idx}'='{an_response.segmented_data.__dict__}'")# This will send analyzed output to configure sink ie Slack, Zendesk etcsink_response_list=sink.send_data(analyzer_response_list, sink_config)
# Uncomment if you want to log sink response# for sink_response in sink_response_list:# if sink_response is not None:# logger.info(f"sink_response='{sink_response}'")
Step 7: Execute workflow
Copy code snippets from Step 3 to Step 6 into python file for example example.py and execute following command -
python example.py
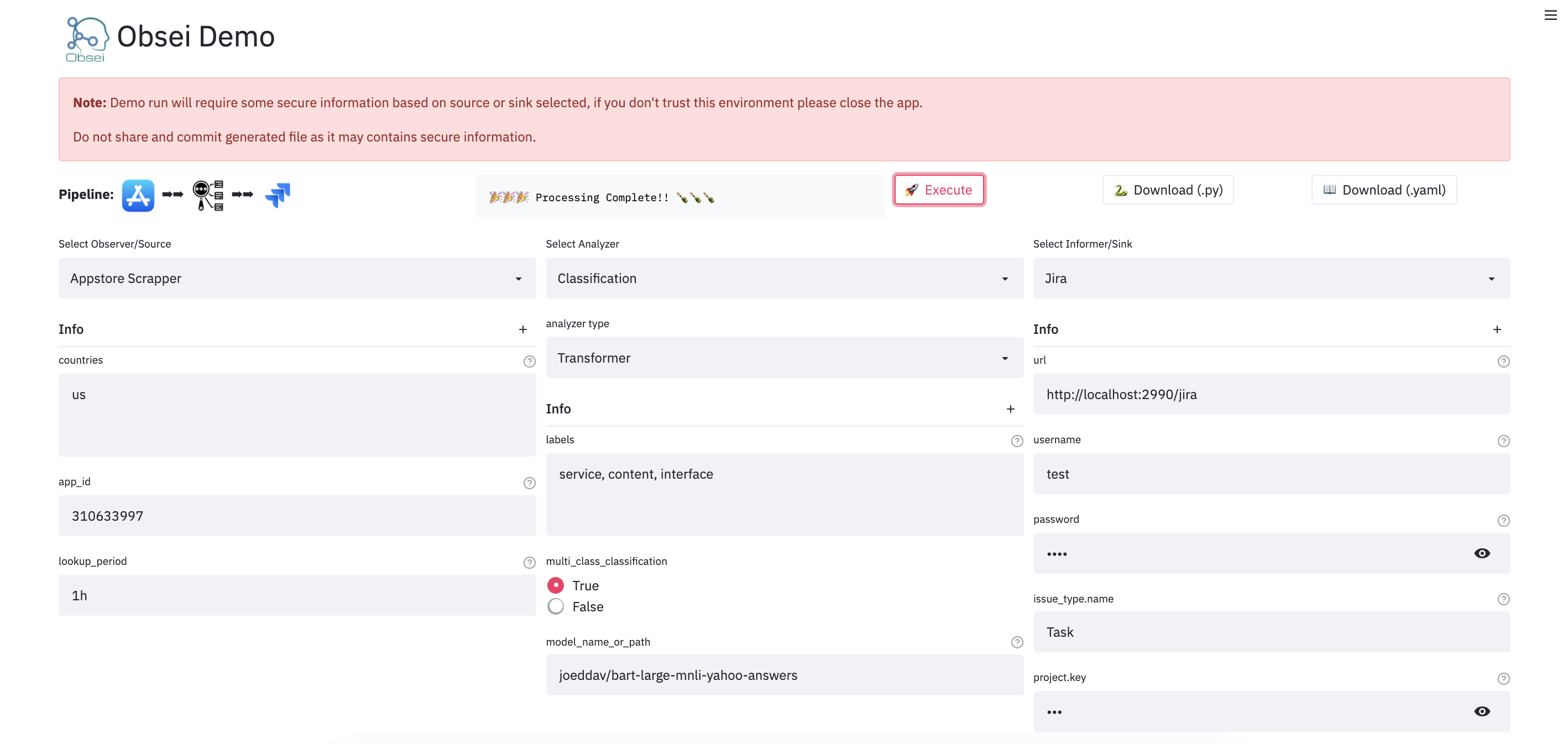
Demo UI
We have a minimal UI that can spin up to test Obsei. It's based on streamlit and is very easy to extend for your purposes.
As project is in very early stage, so we are not accepting any pull requests. First we want to shape the project with community's active suggestion and feedback.
If you want a feature or something doesn't work, please create an issue.
For any security issue please contact us via email
Citing Obsei
If you use obsei in your research please use the following BibTeX entry:
@Misc{Pagaria2020Obsei,
author = {Lalit Pagaria},
title = {Obsei - A workflow automation tool for text analysis need},
howpublished = {Github},
year = {2020},
url = {https://github.com/lalitpagaria/obsei}
}
Stargazers over time
Acknowledgement
We would like to thank DailyGet for continuous support and encouragement.
Please check DailyGet out. it is a platform which can easily be configured to solve any business process automation requirements.