![]()
- What is PyTorch
- Tensor
- Automatic Differentiation and Autograd
- Referances
PyTorch is an open source machine learning library based on the Torch library.
It's an improvement overTorch framework, however, the most notable change is the adoption of a Dynamic Computational Graph.

Developed by Facebook's AI Research lab (FAIR) .PyTorch emphasizes flexibility and allows DL models to be expressed in idiomatic Python.
PyTorch is a Python package that provides two high-level features:
- Tensor computation (like NumPy) with strong GPU acceleration
- Deep neural networks built on a tape-based autograd system
Similarly to NumPy, it also has a C backend, so they are both much faster than native Python, It's a replacement for NumPy to use the power of GPUs providing the max fexibility and speed.
A torch.Tensor is a specialized data structure that 1D or 2D matrix containing elements of a single data type .
PyTorch provides Tensors that can live either on the CPU or the GPU and accelerates the computation by a huge amount.
In PyTorch, we use tensors to encode the inputs and outputs of a model, as well as the model’s parameters.
- There are a few main ways to create a tensor, depending on your use case.
- To create a tensor From a NumPy array , use
np.array(data) - To create a tensor With random or constant values, use
torch.rand(shape). - To create a tensor From another tensor ,
torch.rand_like(shape, datatype). - In-place operations Operations that have a _ suffix are in-place. For example:
x.copy_(y),x.t_(), will change x.
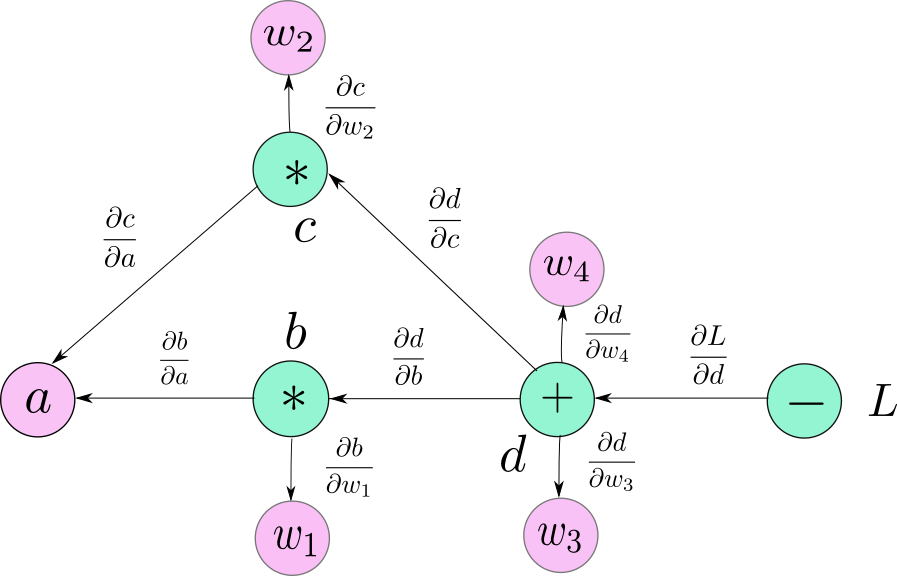
torch.autograd is PyTorch’s automatic differentiation engine that powers neural network training.
A tensor can be created with requires_grad=True so that torch.autograd records operations on them for automatic differentiation.
Autograd has multiple goals:
- Full integration with neural network modules: mix and match auto-differentiation with user-provided gradients
- The main intended application of Autograd is gradient-based optimization
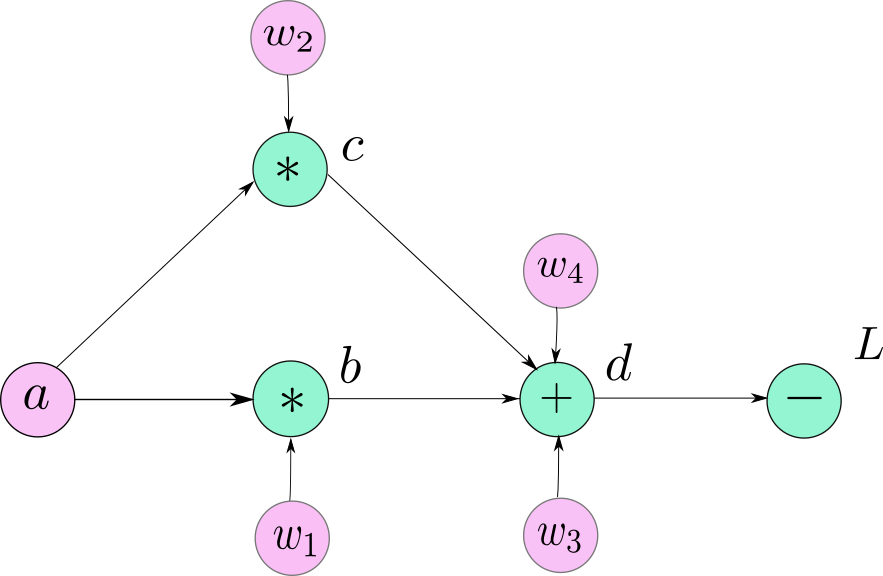
To get a conceptual understanding of how autograd helps a neural network train:
-
Neural networks (NNs) are a collection of functions that are executed on input data and parameters (consisting of weights and biases),
-
Training a NN happens in two steps:
-
A forward pass to compute the value of the loss function.
The forward pass is pretty straight forward. The output of one layer is the input to the next and so forth.
-
A backward pass to compute the gradients of the learnable parameters
-