This work addresses the challenge of producing chip level predictions on satellite imagery when only label proportions at a coarser spatial geometry are available, typically from statistical or aggregated data from administrative divisions (such as municipalities or communes). This kind of tabular data is usually widely available in many regions of the world and application areas and, thus, its exploitation may contribute to leverage the endemic scarcity of fine grained labelled data in Earth Observation (EO). Learning from Label Proportions (LLP) applied to EO data is still an emerging field and performing comparative studies in applied scenarios remains a challenge due to the lack of standardized datasets. In this work, first, we show how simple deep learning and probabilistic methods generally perform better than standard more complex ones, providing a surprising level of finer grained spatial detail when trained with much coarser label proportions. Second, we provide a set of benchmarking datasets enabling comparative LLP applied to EO, providing both fine grained labels and aggregated data according to existing administrative divisions. Finally, we argue how this approach might be valuable when considering on-orbit inference and training.
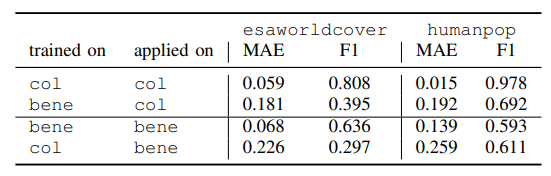
The Sentinel 2 image chips are the same in both colombia-ne datasets and both benelux, they differ on the labels. Observe that we train our models with label proportions that we obtain from these labels at coarser geometries (communes or municipalities). We only use the actual labels at to compute chip level performance metrics. In a real world scenario these fine grained labels would not be available, only the label proportions.
Running the experiments (tranining models)
Download the zip file any of the datasets above and unzip, for instance under /opt/data
Under scripts select the script for esaworldcover or humanpop that you want to run, and check the location of the DATASET variable is correct. The TAG will be used to report results to wandb
Have your wandb token ready.
Run the experiment:
cd scripts
sh run_esaworldcover.sh
while running, hiting ctrl-c once will abort training, but will still loop through the train, val and test datasets to measure and report results to wandb
you can also use the Docker files under docker to start a container configured with tensorflow to run your experiments on a GPU enabled machine.
Results and figures
The IPython notebooks under notebooks contain the code to generate the figures used in the paper (maps, metrics, etc.), run inference on saved models, etc.