
Real-time is the future. Dlink is born for Apache Flink, allowing Flink SQL to enjoy silky smoothness, and is committed to the construction of a real-time computing platform.
Dinky implements Dlink based on Apache Flink, enhances the application and experience of Flink, and explores streaming data warehouses. That is to stand on the shoulders of giants to innovate and practice, Dinky has unlimited potential under the development trend of batch and flow integration in the future.
In the end, Dinky's development is due to the guidance and results of other excellent open source projects such as Apache Flink.
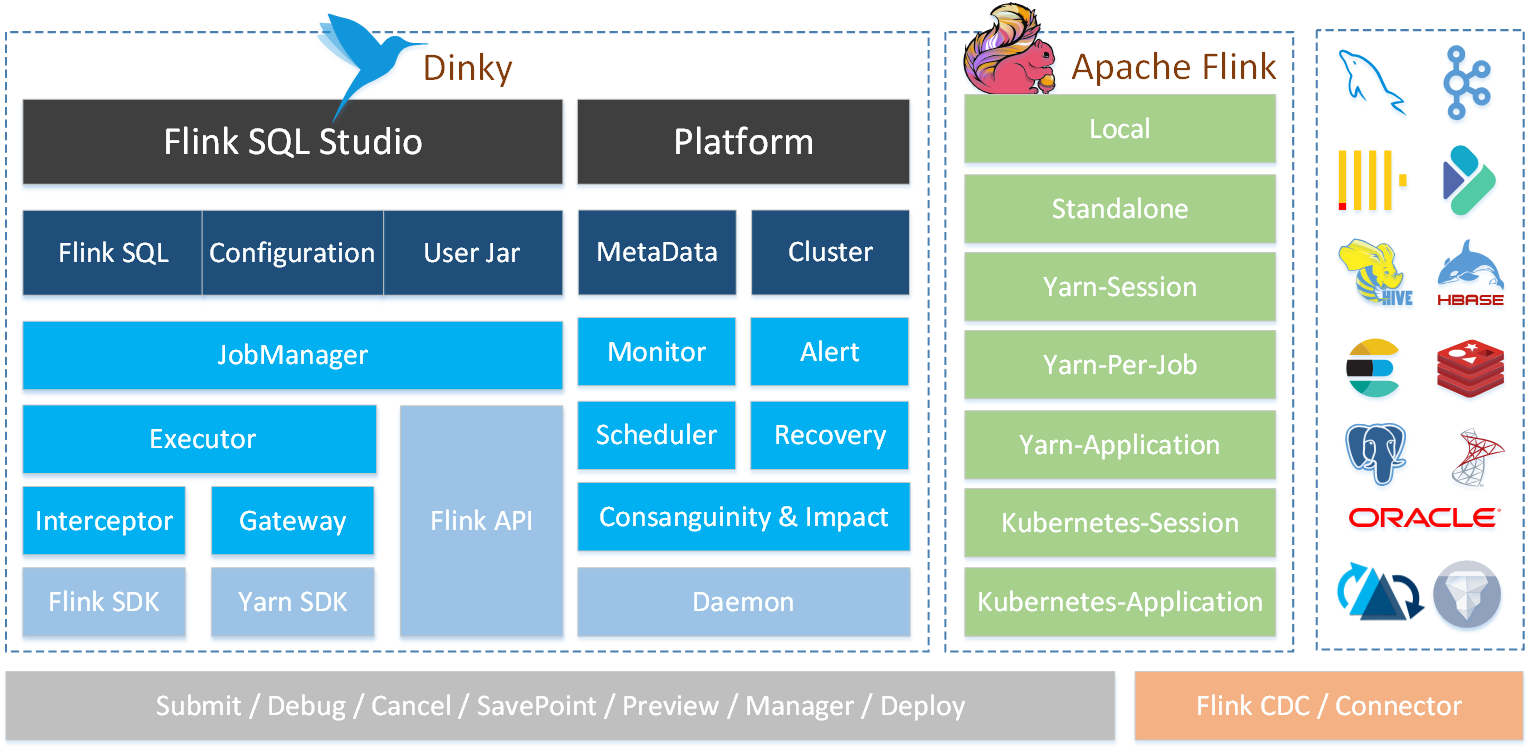
A out-of-the-box, easy to extend, based on Apache Flink, a one-stop real-time computing platform connecting with many frameworks such as OLAP and data lake, dedicated to stream-batch integration The construction and practice of Lake and Warehouse Integration.
Its main objectives are as follows:
-
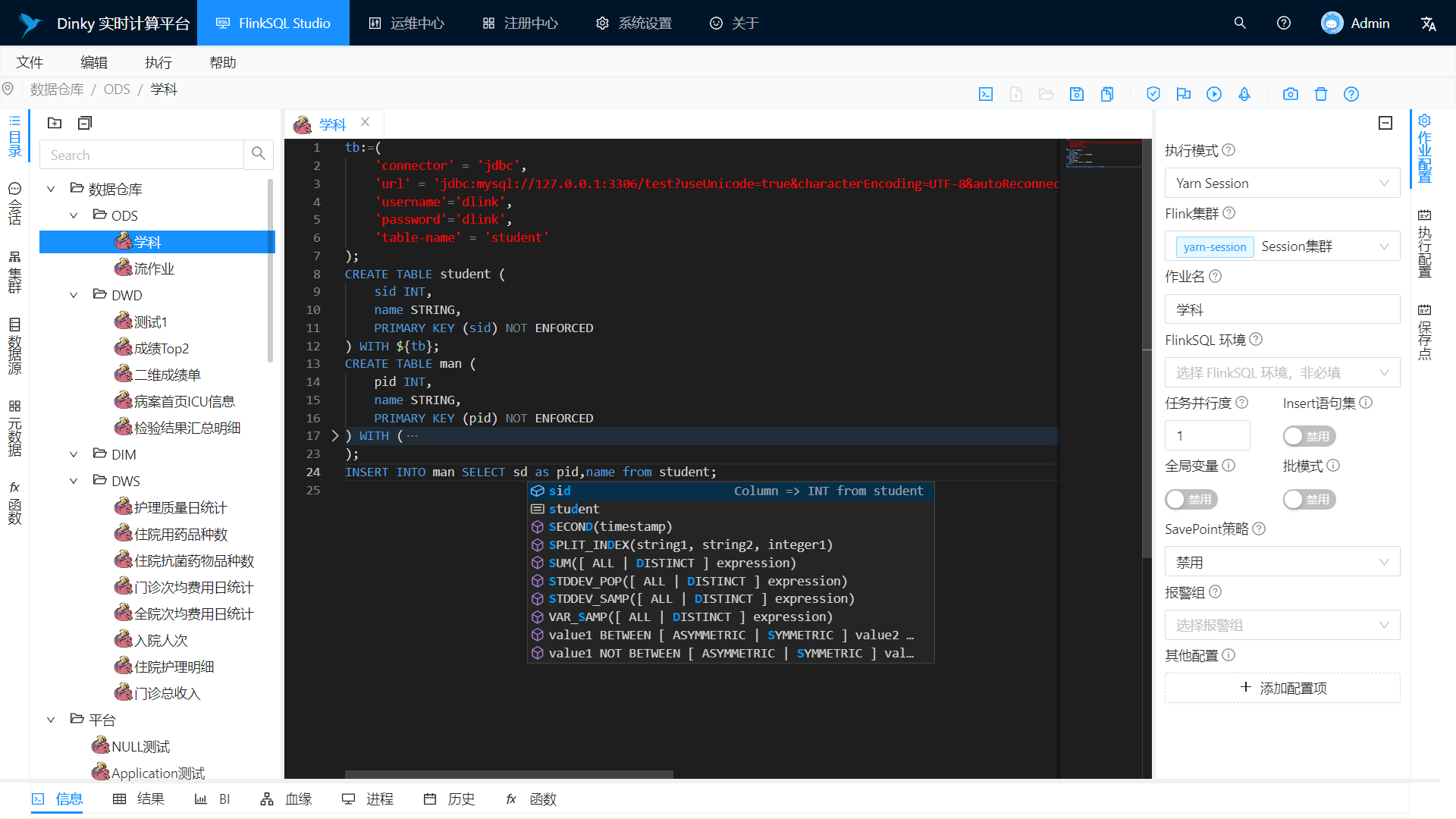
Visual interactive FlinkSQL and SQL data development platform: automatic prompt completion, syntax highlighting, debugging execution, syntax verification, statement beautification, global variables, etc.
-
Supports comprehensive multi-version FlinkSQL job submission methods: Local, Standalone, Yarn Session, Yarn Per-Job, Yarn Application, Kubernetes Session, Kubernetes Application
-
Support all Connectors, UDFs, CDCs, etc. of Apache Flink
-
Support FlinkSQL syntax enhancement: compatible with Apache Flink SQL, table-valued aggregate functions, global variables, CDC multi-source merge, execution environment, statement merge, shared session, etc.
-
Supports easily extensible SQL job submission methods: ClickHouse, Doris, Hive, Mysql, Oracle, Phoenix, PostgreSql, SqlServer, etc.
-
Support FlinkCDC (Source merge) real-time warehousing into the lake
-
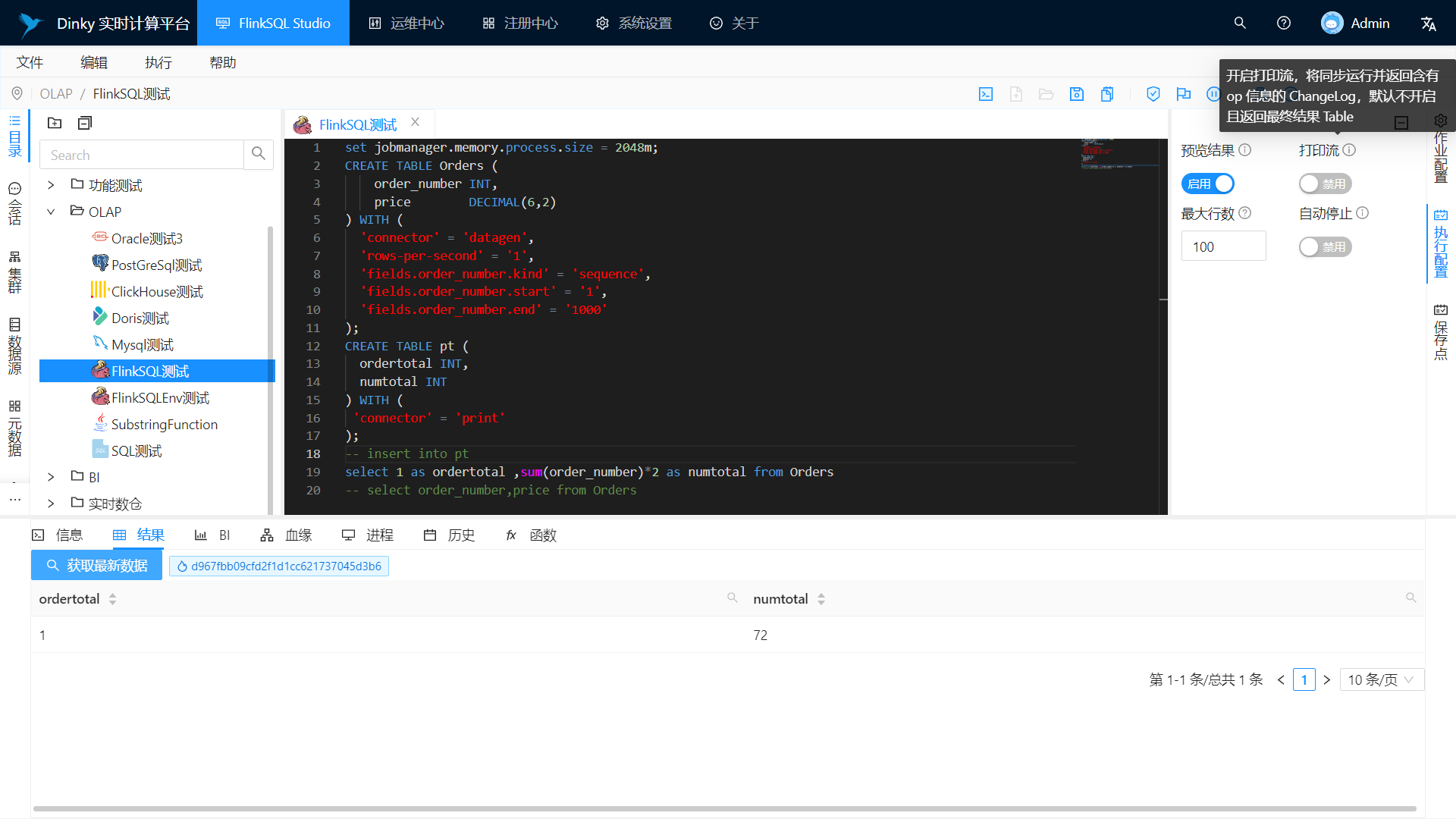
Support real-time debugging preview Table and ChangeLog data and graphics display
-
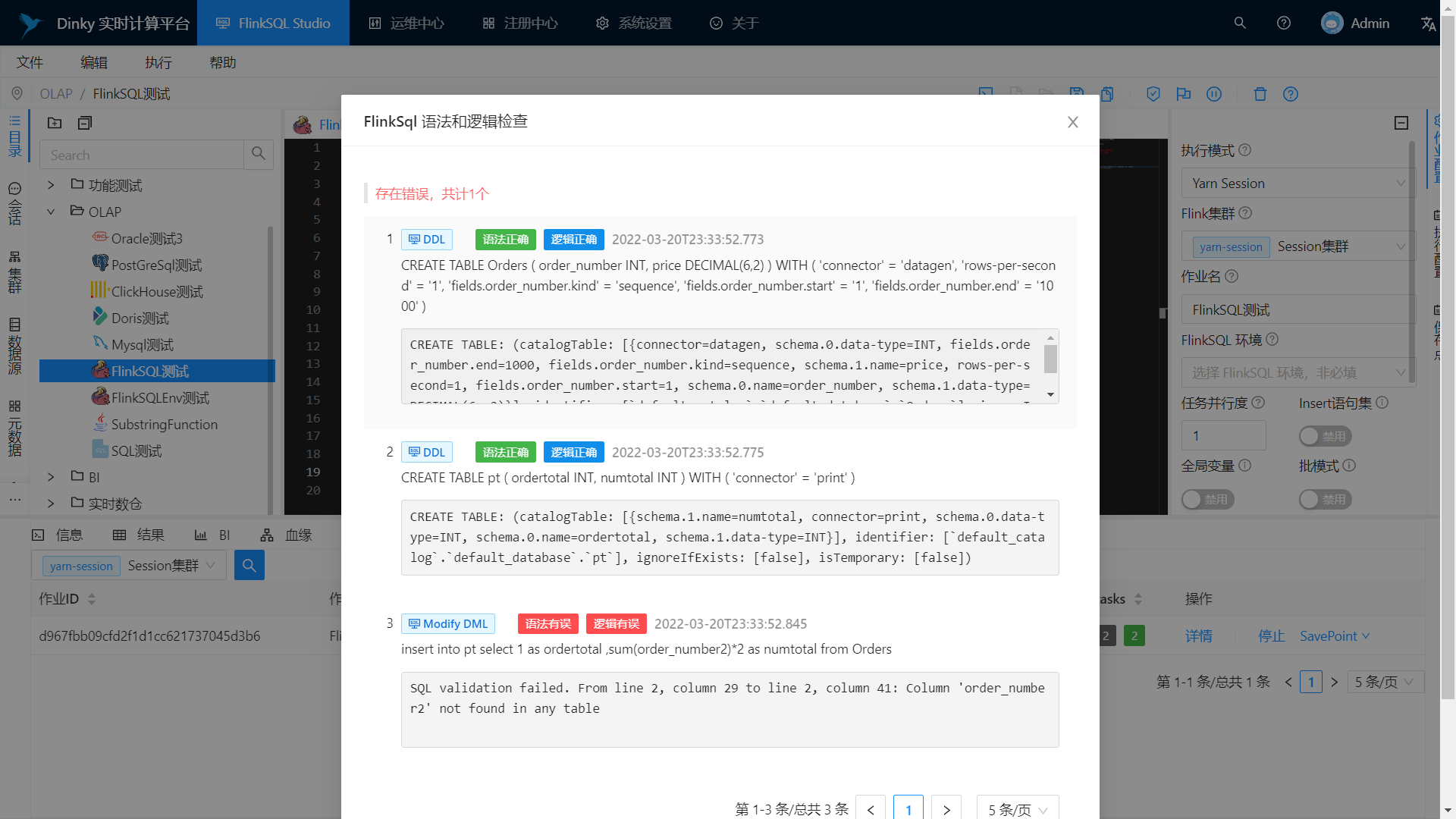
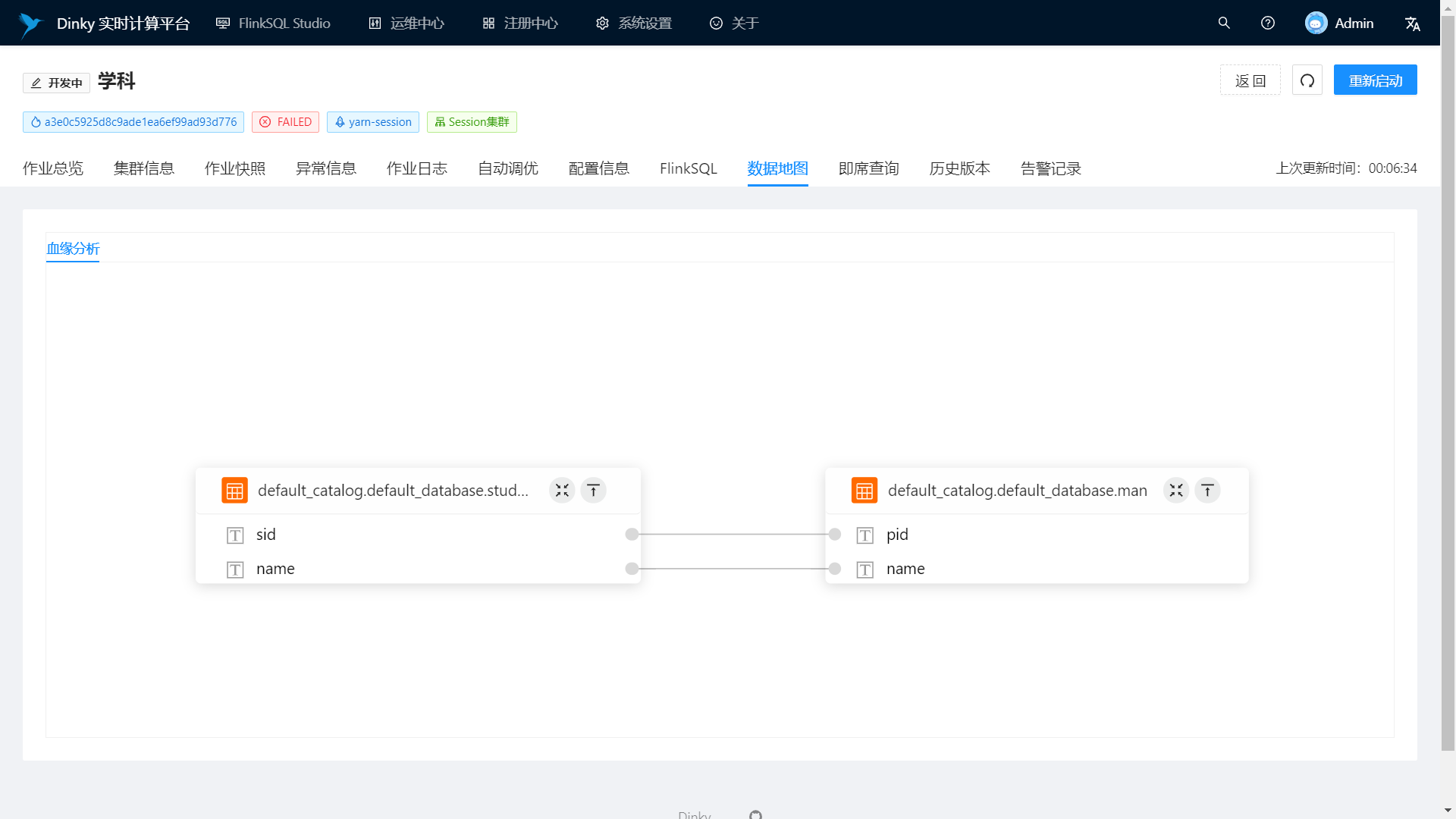
Support syntax logic check, job execution plan, field-level blood relationship analysis, etc.
-
Support Flink metadata, data source metadata query and management
-
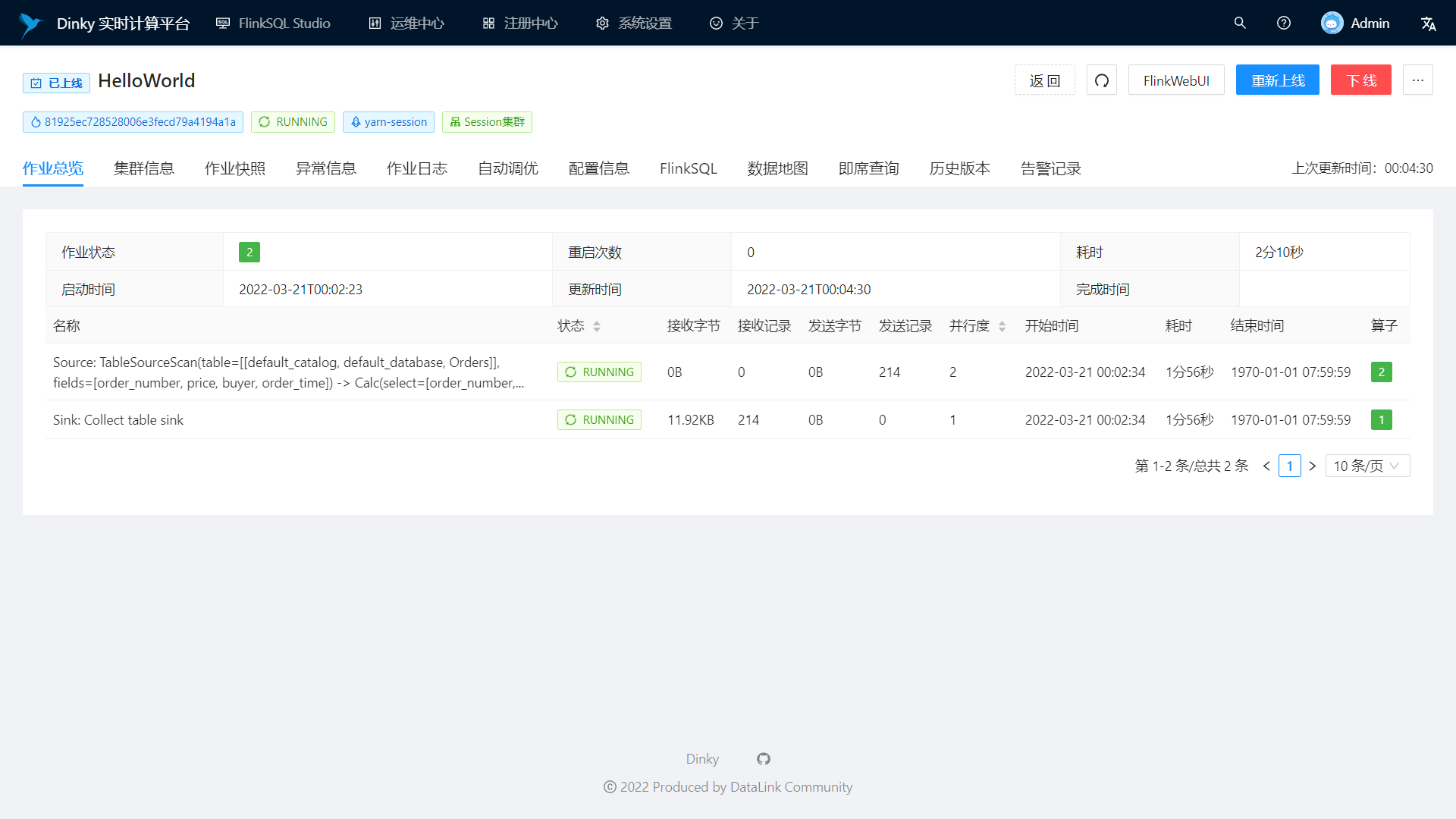
Support real-time task operation and maintenance: job online and offline, job information, cluster information, job snapshot, exception information, job log, data map, ad hoc query, historical version, alarm record, etc.
-
Support as multi-version FlinkSQL Server capability as well as OpenApi
-
Support easy-to-expand real-time job alarms and alarm groups: DingTalk, WeChat Enterprise Account, etc.
-
Support for fully managed SavePoint launch mechanisms: most recent, earliest, once specified, etc.
-
Support multiple resource management: cluster instance, cluster configuration, Jar, data source, alarm group, alarm instance, document, user, system configuration, etc.
-
More hidden functions are waiting for friends to explore
FlinkSQL Studio
Live debug preview
Grammar and logic checking
JobPlan
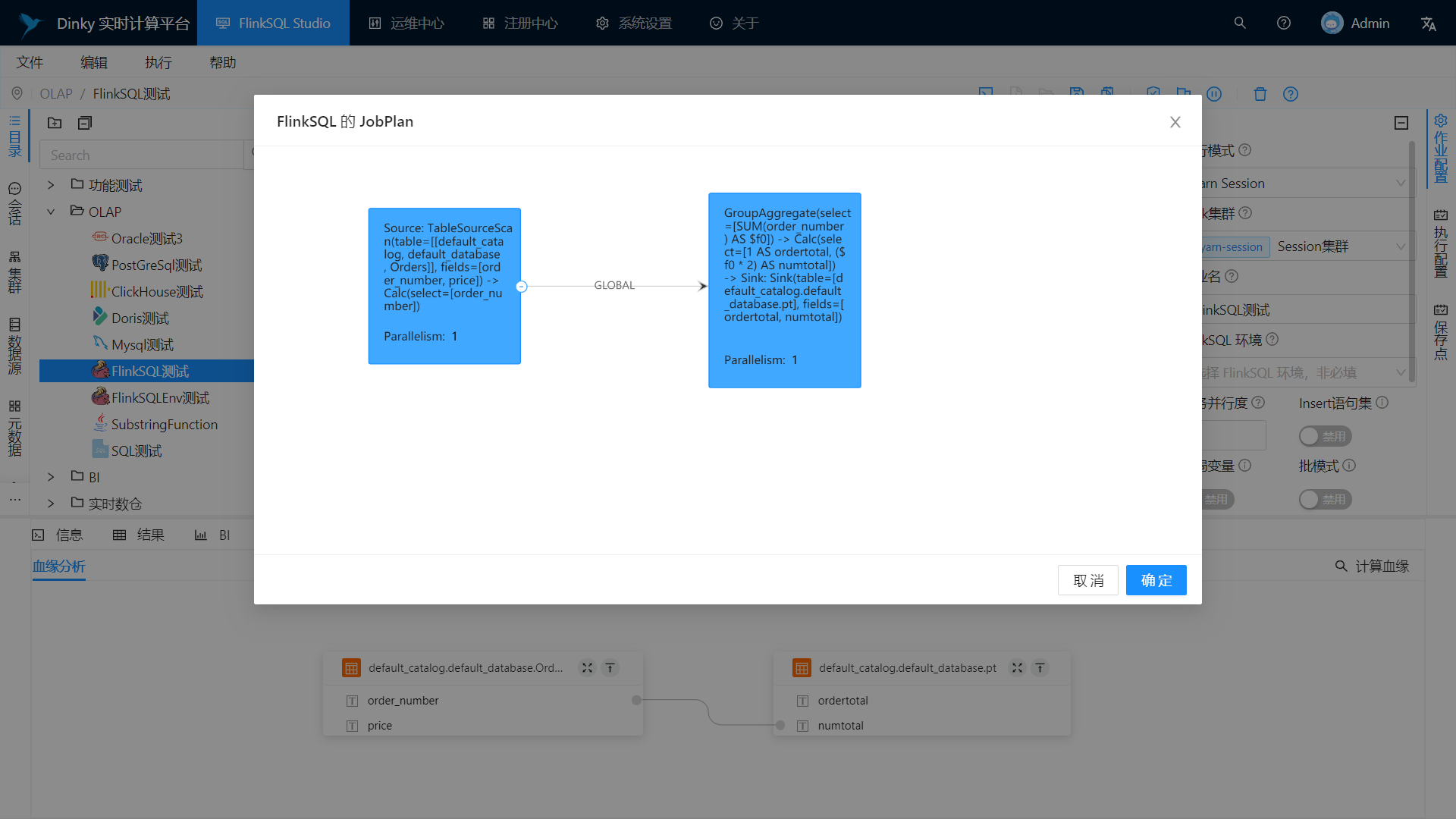
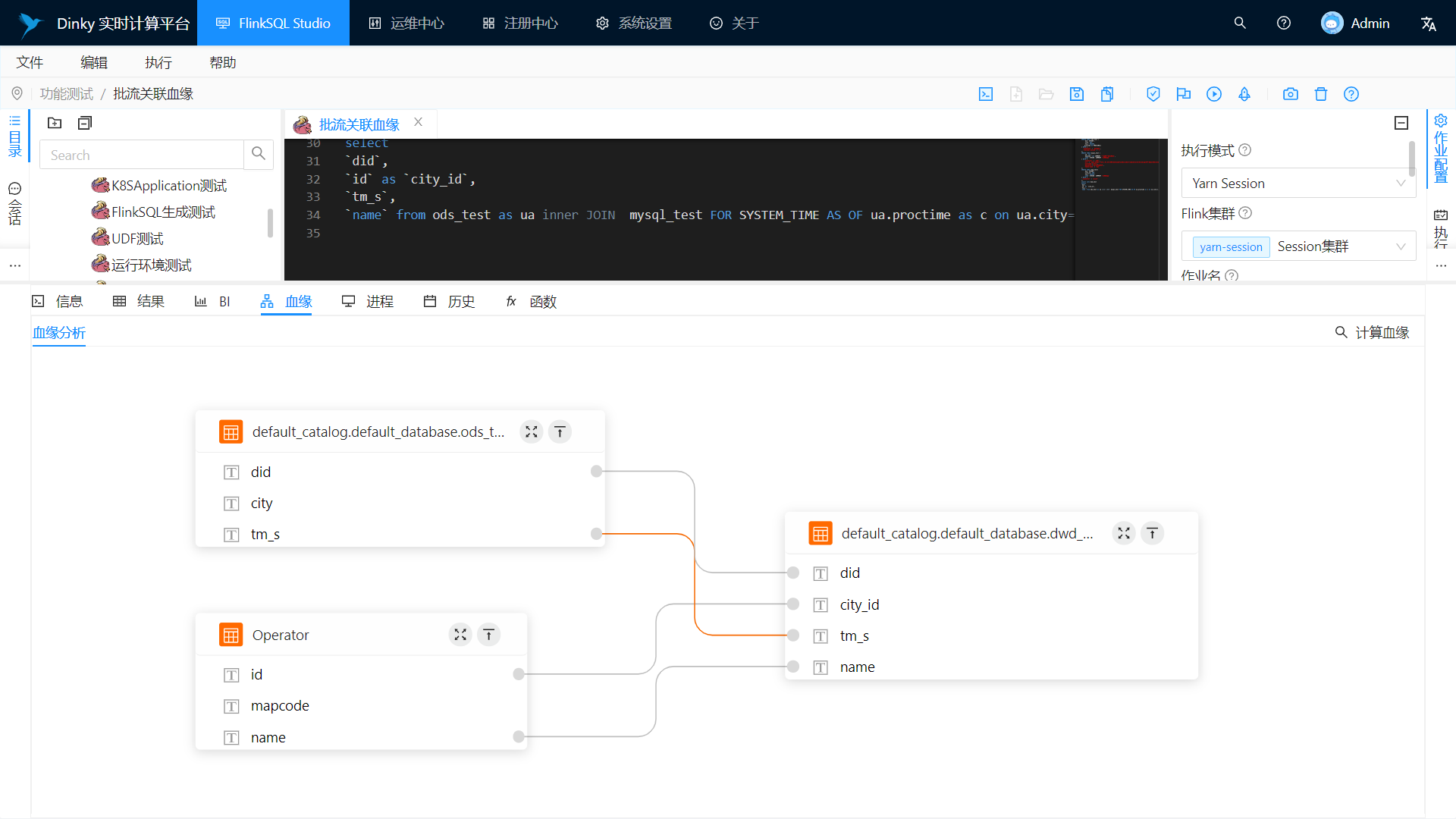
Field-level bloodline analysis
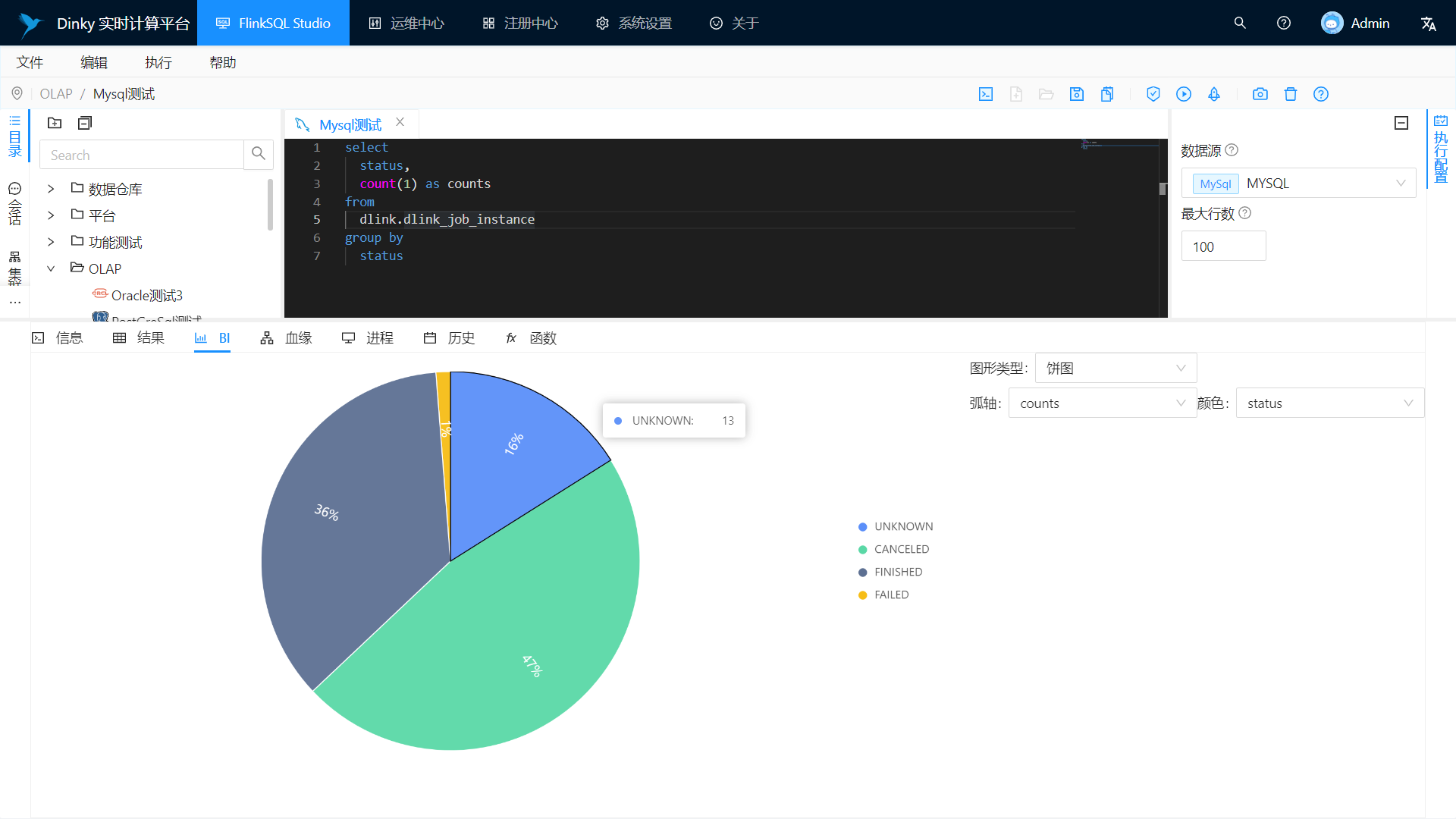
BI showcase
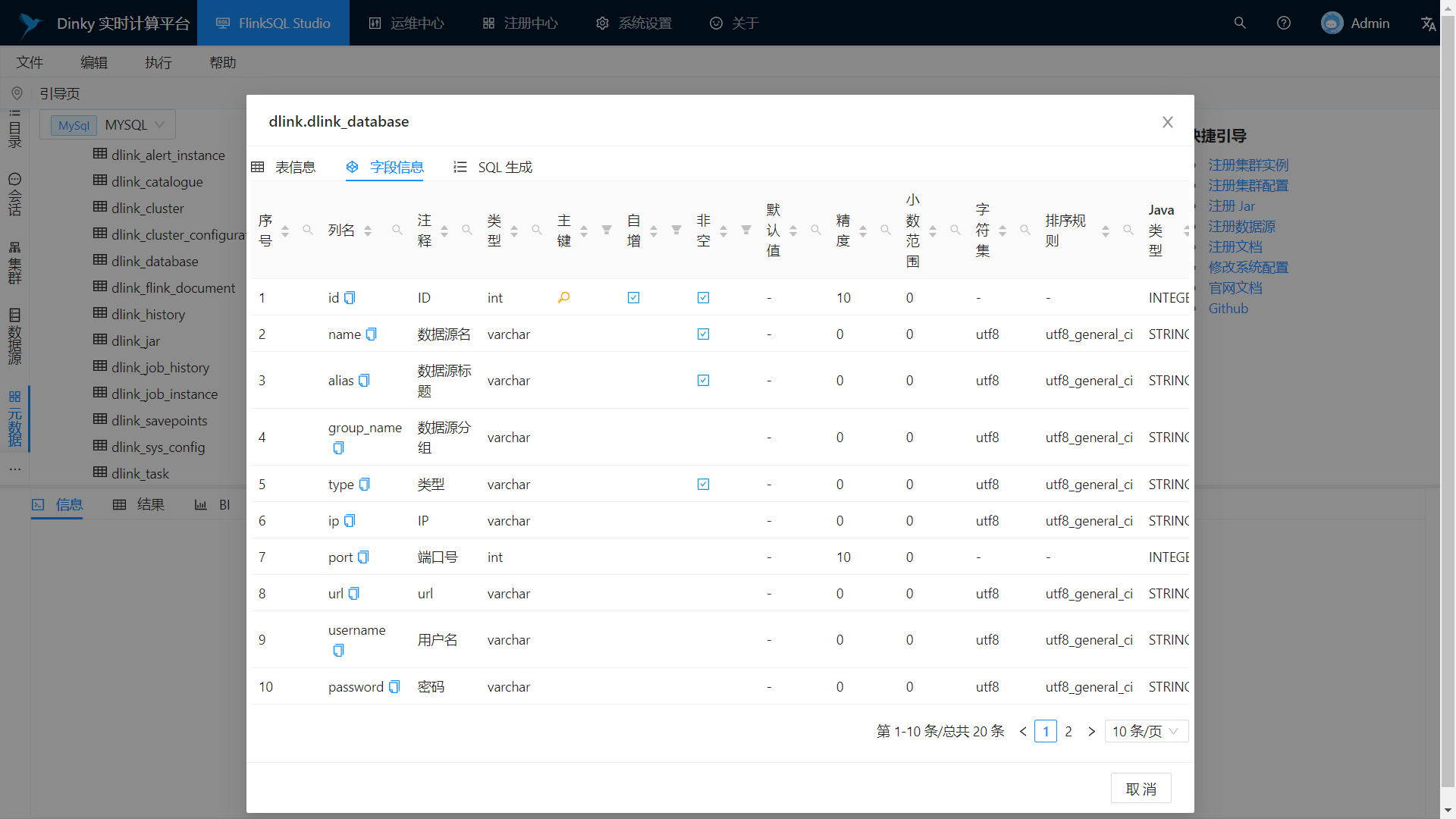
Metadata query
Real-time task monitoring
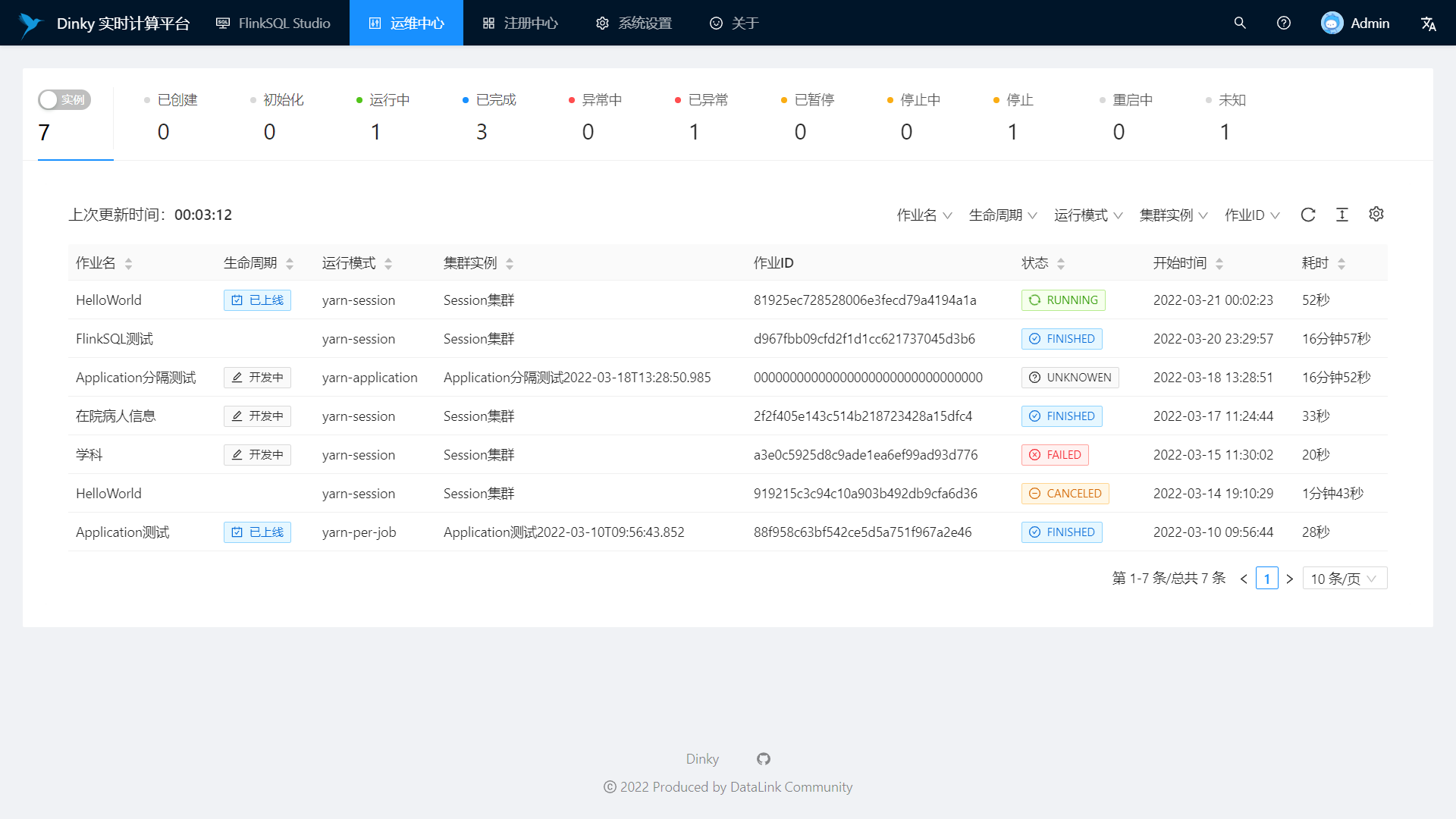
Real-time job information
Data Map
Data source registration

See Function
-
Multi-tenancy and namespaces
-
Global bloodline and influence analysis
-
Unified metadata management
-
Flink metadata persistence
-
Multi-version Flink-Client Server
-
Synchronization of thousands of watches in the whole library
You are welcome to contribute your strength to the community and build a win-win situation. Please refer to the contribution process: [How to Contribute]
Due to more functions, there are more bugs and optimization points. It is strongly recommended that you use or upgrade to the latest version.
Replace all dependent packages of the latest Dinky, and execute some upgrade statements in dlink_history.sql in the sql directory. It is based on the version number and date to determine where to start the execution. Please do not directly execute all sql.
Standing on the shoulders of giants, Dinky was born. For this we express our heartfelt thanks to all the open source software used and its communities! We also hope that we are not only beneficiaries of open source, but also contributors to open source. We also hope that partners who have the same enthusiasm and belief in open source will join in and contribute to open source together! Acknowledgments are listed below:
Thanks to JetBrains for sponsoring a free open source license.

-
Submit an issue
-
Enter the WeChat user community group (recommended, add WeChat
wenmo_aito invite into the group) and QQ user community group (543709668) to communicate, apply for the remark "Dinky + company name + position", do not write or approve -
Follow the WeChat public account to get relevant articles (recommended to follow the latest news): DataLink Data Center
-
Follow the bilibili UP master (at the end of the article) to get the latest video teaching
-
Visit GithubPages or Official Website to read the latest documentation manual
Please refer to the LICENSE document.