Data and code for CVPR 2020 paper: "VIOLIN: A Large-Scale Dataset for Video-and-Language Inference"

We introduce a new task, Video-and-Language Inference, for joint multimodal understanding of video and text. Given a video clip with aligned subtitles as premise, paired with a natural language hypothesis based on the video content, a model needs to infer whether the hypothesis is entailed or contradicted by the given video clip.
Also, we present a new large-scale dataset, named Violin (VIdeO-and-Language INference) for this task, which consists of 95,322 video-hypothesis pairs from 15,887 video clips, spanning over 582 hours of video (YouTube and TV shows). In order to address our new multimodal inference task, a model is required to possess sophisticated reasoning skills, from surface-level grounding (e.g., identifying objects and characters in the video) to in-depth commonsense reasoning (e.g., inferring causal relations of events in the video).
- 2020.03.25 Paper released (arXiv).
- 2020.04.04 Human annotation and data features released.
- Data Statistics
| source | #episodes | #clips | avg clip len | avg pos. statement len | avg neg. statement len | avg subtitle len |
|---|---|---|---|---|---|---|
| Friends | 234 | 2,676 | 32.89s | 17.94 | 17.85 | 72.80 |
| Desperate Housewives | 180 | 3,466 | 32.56s | 17.79 | 17.81 | 69.19 |
| How I Met Your Mother | 207 | 1,944 | 31.64s | 18.08 | 18.06 | 76.78 |
| Modern Family | 210 | 1,917 | 32.04s | 18.52 | 18.20 | 98.50 |
| MovieClips | 5,885 | 5,885 | 40.00s | 17.79 | 17.81 | 69.20 |
| All | 6,716 | 15,887 | 35.20s | 18.10 | 18.04 | 76.40 |
-
Data Download
Subtitles and statements (README)
Detection features (TODO)
To obtain raw video data, you can download the source vidoes yourself (YouTube and TV shows), and then use the span information provided in Human Annotation to extract the clips. Also, we might release sampled frames (as images) in the near future.
- Model Overview
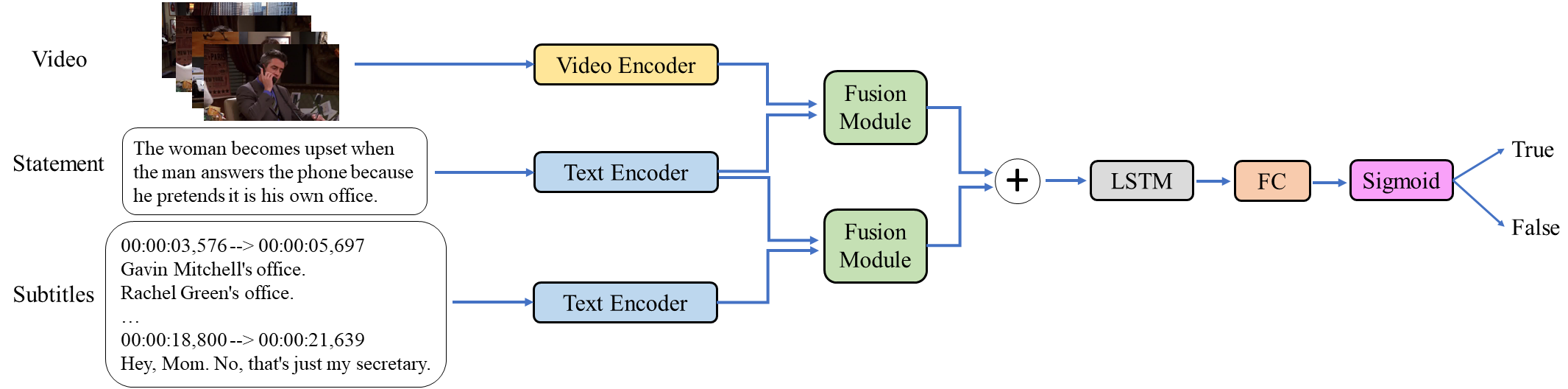

- Code and scripts will be released soon.