This is my solution repository for the DAIN data engineering challenge. The Data engineering challenge had two parts to it - Architecture and Pipeline.
For the first part of the data engineering challenge, an Architecture for a recommender system was to be drafted that could cover all the requirements. You can find the architecture along with my detailed comments here or you can use the following command to initialize a server that hosts the target - RecommendationSystem.MD file.
> grip RecommendationSystem.MD
Make sure you have alredy gone through the setup process and have successfully installed the requirements before doing this.
For the second part of the data engineering challenge we needed to analyse the logs from an IOT system and get the daily median values for all available sensors. The target data pipeline is encapsulated within a command line application.
The solution is served using the functionality in the module - get_median for the IOT Logs analyzer application
To set up the application on your machine
-
Initialize a python 3 virtual environment in the working directory
> virtualenv env -p python3And enter into the environment using
source env/bin/activatecommand. -
Once in virtual environment, install the dependencies using
pip install -r requirements.txt -
Now you can start interacting with the CMD application. Use
python main.py -hto have a look at the help message and the description.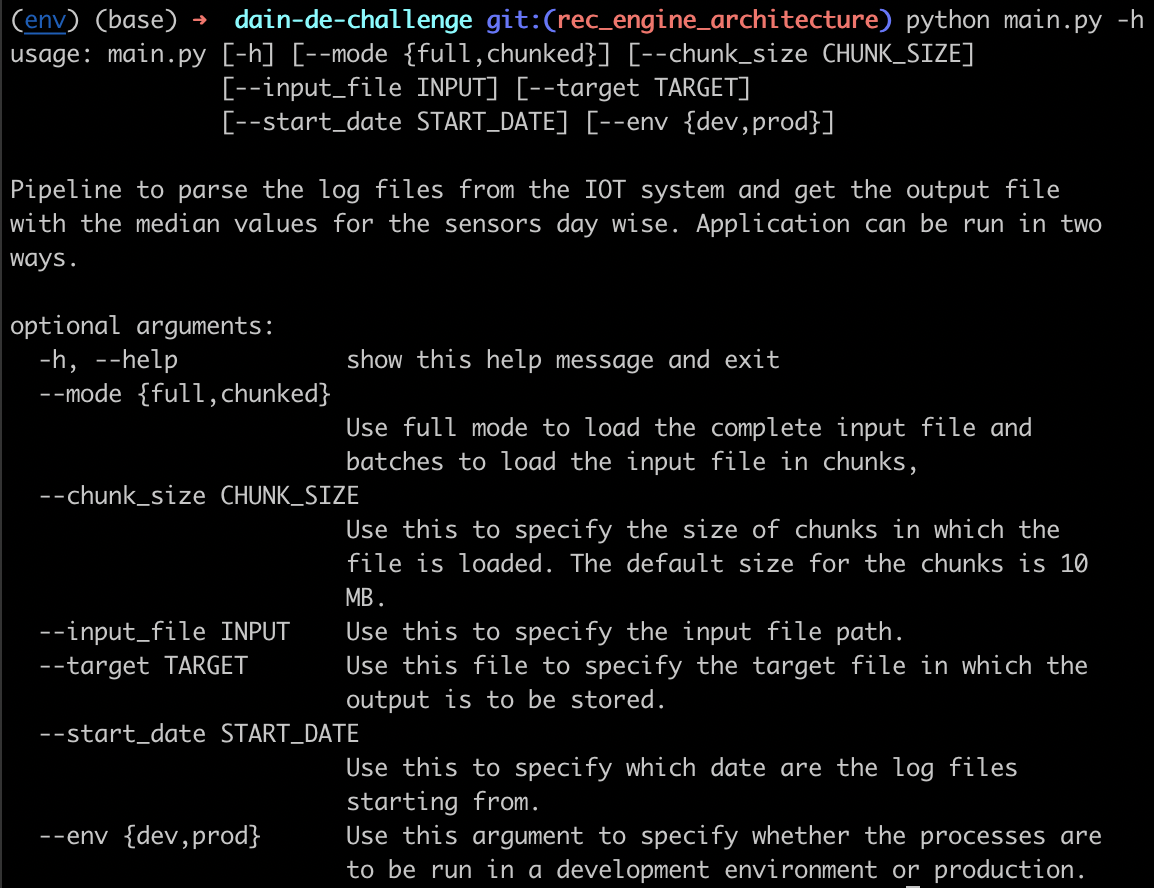
-
Once you have an input JSONL log file, note that you can run the application to analyze the logs in two modes.
--mode fulland--mode chunked. In the full mode, the entire file is read into the memory at once.> python main.py --mode full --input dain-challenge-data.jsonlUse this if you have a really small input file. In this case the memory used depends on the total size of the file.

-
For larger input files it is better to use the
chunkedmode, where we read the data from the file in chunks, parse the data into pandas and compute medians by day. Through this approach at any given time, the data for only one date is stored into memory.> python main.py --mode chunked --input dain-challenge-data.jsonl
In this case the memory used depends on the numebr of observations per day, and the memory used doesn't increase as the size of the file increases, assuming it has similar daily observations and has data for more dates.
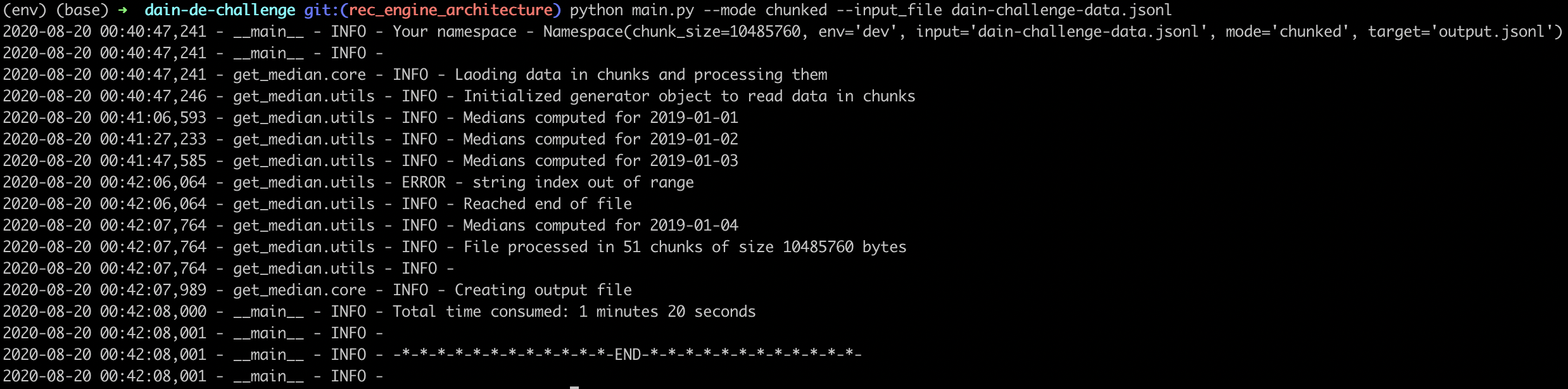
- By default, when the pipeline runs, a new output.jsonl file is created. You can specify the target file using the
--tagretargument
- Data export retrieval could be moved to S3 and could be automated even further using triggers on the system.
- The complete pipeline can be moved to airflow for better overview of the dependencies and cleaner orchestration.
- Right now in the chunked mode, we calculate the median keeping the all the data for the target date in memory. This could be further optimized for memory, discarding record values that can never be median. (Records before current recorded halve of the total records for the day). Although this could lead to an increase in the time consumed per batch.
- A dashboard could be added for analysis of stats recorded. Would be helpful in case we have data from multiple months and multiple sensors.
I hope the two markdown files are able to answer all your questions. If you have any questions unresolved, feel free to reach out to me directly at - rishabh.thukral1997@gmail.com or +4915145161594. Happy to clear any queries you might have. Looking forward to further discussions.