- 详细介绍可以查看我的博客
- 注意:在使用之前要先把存放文法的文件
grammer.txt以及所有源文件xxx.txt放入一个文件夹中,同时一定要更改文件夹路径;即修改main函数中的path_prefix,例如我现在的源文件code.txt放在E:\\Workspace\\diy_compiler\\compiler\\Debug\\目录下,那修改path_prefix为该路径即可
- 我制作了一个简单的 UI 界面,可以在命令行窗口里输入
lianli xxx.txt来编译相应的源文件,命令末尾加上-v命令可以输出归约时使用的产生式,输出顺序为最右推导的逆序,效果如下图所示:
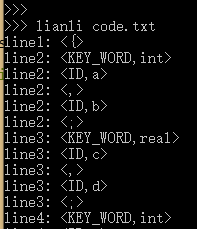
- 我在程序中留有的接口可以方便的对源语言文法进行扩充:
- 首先在
grammer.txt中添加相应的产生式 (最好添加在最后,这样不会改变其他产生式的序号) - 再根据新添加的产生式对应的序号,在
LR1Processor::production_action函数的相应case分支下添加语义动作即可 - 其余的工作均由程序自动完成
- 首先在
- 所有样例文件都和程序打包在一起了
- 样例一为正确的源程序
// code.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true);
{
int a;
a = 1;
}
if (1)
then a = 3;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
}
}output:
- 首先输出的是词法分析结果,输出每一个词法单元以及它们的行数
- 如果在输入命令时后面加上
-v,还会输出语法分析时所使用的产生式,即输出最右推导的逆序列,但是因为输出信息太多,所以这里没加 - 然后输出 Warning 信息,因为是正确的源程序,所以没有 Warning
- 最后输出四元式
>>> lianli code.txt
line1: <{>
line2: <KEY_WORD,int>
line2: <ID,a>
line2: <,>
line2: <ID,b>
line2: <;>
line3: <KEY_WORD,real>
line3: <ID,c>
line3: <,>
line3: <ID,d>
line3: <;>
line4: <KEY_WORD,int>
line4: <ID,e>
line4: <,>
line4: <ID,g>
line4: <,>
line4: <ID,h>
line4: <;>
line5: <ID,a>
line5: <=>
line5: <NUM,1300>
line5: <;>
line7: <KEY_WORD,if>
line7: <!>
line7: <(>
line7: <ID,a>
line7: <*>
line7: <->
line7: <ID,b>
line7: <RELOPT,>=>
line7: <ID,c>
line7: <+>
line7: <ID,d>
line7: <)>
line8: <KEY_WORD,then>
line9: <{>
line10: <ID,e>
line10: <=>
line10: <ID,g>
line10: <+>
line10: <ID,h>
line10: <;>
line11: <}>
line12: <KEY_WORD,else>
line13: <ID,e>
line13: <=>
line13: <ID,g>
line13: <*>
line13: <ID,h>
line13: <;>
line15: <KEY_WORD,do>
line15: <{>
line16: <ID,a>
line16: <=>
line16: <NUM,1>
line16: <;>
line17: <}>
line17: <KEY_WORD,while>
line17: <(>
line17: <KEY_WORD,true>
line17: <)>
line17: <;>
line18: <{>
line19: <KEY_WORD,int>
line19: <ID,a>
line19: <;>
line20: <ID,a>
line20: <=>
line20: <NUM,1>
line20: <;>
line21: <}>
line22: <KEY_WORD,if>
line22: <(>
line22: <NUM,1>
line22: <)>
line23: <KEY_WORD,then>
line23: <ID,a>
line23: <=>
line23: <NUM,3>
line23: <;>
line25: <KEY_WORD,while>
line25: <ID,a>
line25: <RELOPT,>=>
line25: <NUM,10>
line26: <KEY_WORD,do>
line27: <{>
line28: <KEY_WORD,if>
line28: <(>
line28: <ID,a>
line28: <RELOPT,==>
line28: <ID,a>
line28: <*>
line28: <ID,b>
line28: <)>
line29: <KEY_WORD,then>
line30: <ID,a>
line30: <=>
line30: <ID,a>
line30: <->
line30: <NUM,1>
line30: <;>
line31: <}>
line32: <}>
***********************************
No Warning!
************************************
四元式:
1: ( rtoi, 1300.000000, _, t0 )
2: ( =, t0, _, ENTRY(a) )
3: ( @, ENTRY(b), _, t1 )
4: ( *, ENTRY(a), t1, t2 )
5: ( +, ENTRY(c), ENTRY(d), t3 )
6: ( >=, t2, t3, t4 )
7: ( jtrue, t4, _, 9 )
8: ( j, _, _, 9 )
9: ( !, t4, _, t5 )
10: ( jtrue, t5, _, 12 )
11: ( j, _, _, 15 )
12: ( +, ENTRY(g), ENTRY(h), t6 )
13: ( =, t6, _, ENTRY(e) )
14: ( j, _, _, 17 )
15: ( *, ENTRY(g), ENTRY(h), t7 )
16: ( =, t7, _, ENTRY(e) )
17: ( rtoi, 1.000000, _, t8 )
18: ( =, t8, _, ENTRY(a) )
19: ( jtrue, true, _, 21 )
20: ( j, _, _, 21 )
21: ( jtrue, true, _, 17 )
22: ( j, _, _, 23 )
23: ( rtoi, 1.000000, _, t9 )
24: ( =, t9, _, ENTRY(a) )
25: ( jtrue, 1.000000, _, 27 )
26: ( j, _, _, 27 )
27: ( jtrue, 1.000000, _, 29 )
28: ( j, _, _, 31 )
29: ( rtoi, 3.000000, _, t10 )
30: ( =, t10, _, ENTRY(a) )
31: ( >=, ENTRY(a), 10.000000, t11 )
32: ( jtrue, t11, _, 34 )
33: ( j, _, _, 45 )
34: ( *, ENTRY(a), ENTRY(b), t12 )
35: ( ==, ENTRY(a), t12, t13 )
36: ( jtrue, t13, _, 38 )
37: ( j, _, _, 38 )
38: ( jtrue, t13, _, 40 )
39: ( j, _, _, 31 )
40: ( itor, ENTRY(a), _, t14 )
41: ( -, t14, 1.000000, t15 )
42: ( rtoi, t15, _, t16 )
43: ( =, t16, _, ENTRY(a) )
44: ( j, _, _, 31 )
45: ( End, _, _, _ )- 样例二中科学计数法的表示存在错误,
e后面必须跟一个数字
// code1.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e; // 词法分析阶段报错
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}
output:
>>> lianli code1.txt
line1: <{>
line2: <KEY_WORD,int>
line2: <ID,a>
line2: <,>
line2: <ID,b>
line2: <;>
line3: <KEY_WORD,real>
line3: <ID,c>
line3: <,>
line3: <ID,d>
line3: <;>
line4: <KEY_WORD,int>
line4: <ID,e>
line4: <,>
line4: <ID,g>
line4: <,>
line4: <ID,h>
line4: <;>
line5: <ID,a>
line5: <=>
************************************
ERROR!
Line5: No number after 'e' !
************************************
>>>- 样例三中存在多重定义的错误,该错误将在语义分析阶段报错
// code2.txt
{
int a, b;
real c, d;
real a; // 多重定义
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}output:
>>> lianli code2.txt
line1: <{>
// 省略了部分词法分析输出
line34: <}>
************************************
ERROR!
Line4: multiple definition!
************************************
>>>- 样例四中使用了变量
a,但却没有定义,因此存在无定义错误
// code3.txt
{
int b; // 无定义
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}output:
>>> lianli code3.txt
line1: <{>
// 省略了部分词法分析输出
line33: <}>
************************************
ERROR!
Line5: Undefined variant a !
************************************- 样例五在程序中除以了0,会产生除以0的报错,该报错在语义分析阶段完成
// code4.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3 / 0; // 除以0
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}output:
>>> lianli code4.txt
line1: <{>
// 省略了部分词法分析输出
line33: <}>
************************************
ERROR!
Line5: Err: Divided by zero!
************************************- 样例六中的错误为部分语句缺少
)/;/}这样的分界符,在这种情况下会在语法分析阶段报错。但我使用了错误恢复,因此会自动在程序输入流程中插入缺少的分界符,最后依然能够生成正确的四元式,但会产生相应的 Warning,提示哪一行没有加分界符
// code5.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d // 缺少右圆括号
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true) // 缺少分号
{
int a;
a = 1; // 缺少右大括号
if (1)
then a = 3;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1; // 缺少右大括号
}output:
- 可以看到,最后输出的四元式与样例一中生成的四元式相同
>>> lianli code5.txt
line1: <{>
// 省略了部分词法分析输出
line32: <}>
***********************************
Line7:
Warning 0: Lack of )
Line17:
Warning 1: Lack of ;
Line32:
Warning 2: Lack of }
Line32:
Warning 3: Lack of }
4 Warning(s)!
************************************
四元式:
1: ( rtoi, 1300.000000, _, t0 )
2: ( =, t0, _, ENTRY(a) )
3: ( @, ENTRY(b), _, t1 )
4: ( *, ENTRY(a), t1, t2 )
5: ( +, ENTRY(c), ENTRY(d), t3 )
6: ( >=, t2, t3, t4 )
7: ( jtrue, t4, _, 9 )
8: ( j, _, _, 9 )
9: ( !, t4, _, t5 )
10: ( jtrue, t5, _, 12 )
11: ( j, _, _, 15 )
12: ( +, ENTRY(g), ENTRY(h), t6 )
13: ( =, t6, _, ENTRY(e) )
14: ( j, _, _, 17 )
15: ( *, ENTRY(g), ENTRY(h), t7 )
16: ( =, t7, _, ENTRY(e) )
17: ( rtoi, 1.000000, _, t8 )
18: ( =, t8, _, ENTRY(a) )
19: ( jtrue, true, _, 21 )
20: ( j, _, _, 21 )
21: ( jtrue, true, _, 17 )
22: ( j, _, _, 23 )
23: ( rtoi, 1.000000, _, t9 )
24: ( =, t9, _, ENTRY(a) )
25: ( jtrue, 1.000000, _, 27 )
26: ( j, _, _, 27 )
27: ( jtrue, 1.000000, _, 29 )
28: ( j, _, _, 31 )
29: ( rtoi, 3.000000, _, t10 )
30: ( =, t10, _, ENTRY(a) )
31: ( >=, ENTRY(a), 10.000000, t11 )
32: ( jtrue, t11, _, 34 )
33: ( j, _, _, 45 )
34: ( *, ENTRY(a), ENTRY(b), t12 )
35: ( ==, ENTRY(a), t12, t13 )
36: ( jtrue, t13, _, 38 )
37: ( j, _, _, 38 )
38: ( jtrue, t13, _, 40 )
39: ( j, _, _, 31 )
40: ( itor, ENTRY(a), _, t14 )
41: ( -, t14, 1.000000, t15 )
42: ( rtoi, t15, _, t16 )
43: ( =, t16, _, ENTRY(a) )
44: ( j, _, _, 31 )
45: ( End, _, _, _ )- 样例七展示了一般错误的处理情况:输出错误的行数、表明在读入哪一个符号时出错、以及可能的正确输入符号
- 源程序中的错误为缺少一个运算符
// code6.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true);
{
int a;
a = 1;
}
if (1)
then a = 3;
while a >= 10
do
{
if a == a b // 缺少运算符
then
a = a - 1;
}
}output:
- 可以看到,提供的可能正确输入符号中包含了各种算逻运算符以及结束
if语句的then
>>> lianli code6.txt
line1: <{>
// 省略了部分词法分析输出
line32: <}>
************************************
ERROR!
Line28:
state 32 can't accept id !
possible symbols are:
<= / then >= + - * or and == != < >
************************************