

Featureform is a virtual feature store. It enables data scientists to define, manage, and serve their ML model's features. Featureform sits atop your existing infrastructure and orchestrates it to work like a traditional feature store. By using Featureform, a data science team can solve the organizational problems:
- Enhance Collaboration Featureform ensures that transformations, features, labels, and training sets are defined in a standardized form, so they can easily be shared, re-used, and understood across the team.
- Organize Experimentation The days of untitled_128.ipynb are over. Transformations, features, and training sets can be pushed from notebooks to a centralized feature repository with metadata like name, variant, lineage, and owner.
- Facilitate Deployment Once a feature is ready to be deployed, Featureform will orchestrate your data infrastructure to make it ready in production. Using the Featureform API, you won't have to worry about the idiosyncrasies of your heterogeneous infrastructure (beyond their transformation language).
- Increase Reliability Featureform enforces that all features, labels, and training sets are immutable. This allows them to safely be re-used among data scientists without worrying about logic changing. Furthermore, Featureform's orchestrator will handle retry logic and attempt to resolve other common distributed system problems automatically.
- Preserve Compliance With built-in role-based access control, audit logs, and dynamic serving rules, your compliance logic can be enforced directly by Featureform.
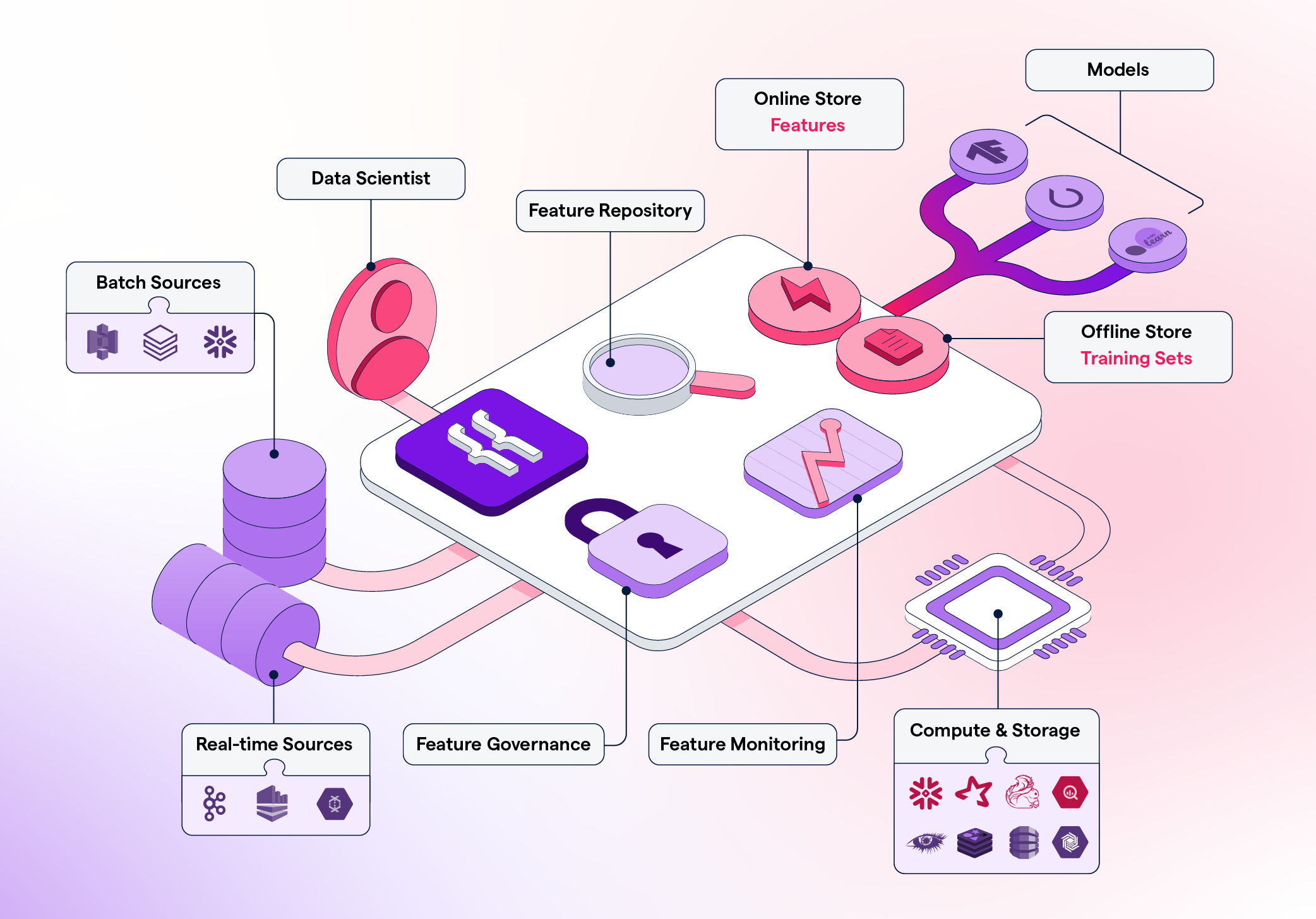
Use your existing data infrastructure. Featureform does not replace your existing infrastructure. Rather, Featureform transforms your existing infrastructure into a feature store. In being infrastructure-agnostic, teams can pick the right data infrastructure to solve their processing problems, while Featureform provides a feature store abstraction above it. Featureform orchestrates and manages transformations rather than actually computing them. The computations are offloaded to the organization's existing data infrastructure. In this way, Featureform is more akin to a framework and workflow, than an additional piece of data infrastructure.
Designed for both single data scientists and large enterprise teams Whether you're a single data scientist or a part of a large enterprise organization, Featureform allows you to document and push your transformations, features, and training sets definitions to a centralized repository. It works everywhere from a laptop to a large heterogeneous cloud deployment.
- A single data scientist working locally: The days of untitled_128.ipynb, df_final_final_7, and hundreds of undocumented versions of datasets. A data scientist working in a notebook can push transformation, feature, and training set definitions to a centralized, local repository.
- A single data scientist with a production deployment: Register your PySpark transformations and let Featureform orchestrate your data infrastructure from Spark to Redis, and monitor both the infrastructure and the data.
- A data science team: Share, re-use, and learn from each other's transformations, features, and training sets. Featureform standardizes how machine learning resources are defined and provides an interface for search and discovery. It also maintains a history of changes, allows for different variants of features, and enforces immutability to resolve the most common cases of failure when sharing resources.
- A data science organization: An enterprise will have a variety of different rules around access control of their data and features. The rules may be based on the data scientist’s role, the model’s category, or dynamically based on a user’s input data (i.e. they are in Europe and subject to GDPR). All of these rules can be specified, and Featureform will enforce them. Data scientists can be sure to comply with the organization’s governance rules without modifying their workflow.
Native embeddings support Featureform was built from the ground up with embeddings in mind. It supports vector databases as both inference and training stores. Transformer models can be used as transformations, so that embedding tables can be versioned and reliably regenerated. We even created and open-sourced a popular vector database, Emeddinghub.
Open-source Featureform is free to use under the Mozilla Public License 2.0.

In reality, the feature’s definition is split across different pieces of infrastructure: the data source, the transformations, the inference store, the training store, and all their underlying data infrastructure. However, a data scientist will think of a feature in its logical form, something like: “a user’s average purchase price”. Featureform allows data scientists to define features in their logical form through transformation, providers, label, and training set resources. Featureform will then orchestrate the actual underlying components to achieve the data scientists' desired state.
Featureform can be run locally on files or in Kubernetes with your existing infrastructure.
Featureform on Kubernetes can be used to connect to your existing cloud infrastructure and can also be run locally on Minikube.
To check out how to run it in the cloud, follow our Kubernetes quickstart.
To try Featureform with Minikube, follow our Minikube guide
Featureform can also be run locally on files. Follow the steps below to get started with the Featureform CLI.
pip install featureform
We'll use a fraudulent transaction dataset that can be found here: https://featureform-demo-files.s3.amazonaws.com/transactions.csv
The data contains 9 columns, almost all of would require some feature engineering before using in a typical model.
TransactionID,CustomerID,CustomerDOB,CustLocation,CustAccountBalance,TransactionAmount (INR),Timestamp,IsFraud
T1,C5841053,10/1/94,JAMSHEDPUR,17819.05,25,2022-04-09 11:33:09,False
T2,C2142763,4/4/57,JHAJJAR,2270.69,27999,2022-03-27 01:04:21,False
T3,C4417068,26/11/96,MUMBAI,17874.44,459,2022-04-07 00:48:14,False
T4,C5342380,14/9/73,MUMBAI,866503.21,2060,2022-04-14 07:56:59,True
T5,C9031234,24/3/88,NAVI MUMBAI,6714.43,1762.5,2022-04-13 07:39:19,False
T6,C1536588,8/10/72,ITANAGAR,53609.2,676,2022-03-26 17:02:51,True
T7,C7126560,26/1/92,MUMBAI,973.46,566,2022-03-29 08:00:09,True
T8,C1220223,27/1/82,MUMBAI,95075.54,148,2022-04-12 07:01:02,True
T9,C8536061,19/4/88,GURGAON,14906.96,833,2022-04-10 20:43:10,True
We can write a config file in Python that registers our test data file.
import featureform as ff
ff.register_user("featureformer").make_default_owner()
local = ff.register_local()
transactions = local.register_file(
name="transactions",
variant="quickstart",
description="A dataset of fraudulent transactions",
path="transactions.csv"
)Next, we'll define a Dataframe transformation on our dataset.
@local.df_transformation(variant="quickstart",
inputs=[("transactions", "quickstart")])
def average_user_transaction(transactions):
"""the average transaction amount for a user """
return transactions.groupby("CustomerID")["TransactionAmount"].mean()Next, we'll register a passenger entity to associate with a feature and label.
user = ff.register_entity("user")
# Register a column from our transformation as a feature
average_user_transaction.register_resources(
entity=user,
entity_column="CustomerID",
inference_store=local,
features=[
{"name": "avg_transactions", "variant": "quickstart", "column": "TransactionAmount", "type": "float32"},
],
)
# Register label from our base Transactions table
transactions.register_resources(
entity=user,
entity_column="CustomerID",
labels=[
{"name": "fraudulent", "variant": "quickstart", "column": "IsFraud", "type": "bool"},
],
)Finally, we'll join together the feature and label intro a training set.
ff.register_training_set(
"fraud_training", "quickstart",
label=("fraudulent", "quickstart"),
features=[("avg_transactions", "quickstart")],
)Now that our definitions are complete, we can apply it to our Featureform instance.
featureform apply definitions.py --local
Once we have our training set and features registered, we can train our model.
import featureform as ff
client = ff.ServingLocalClient()
dataset = client.training_set("fraud_training", "quickstart")
training_dataset = dataset.repeat(10).shuffle(1000).batch(8)
for feature_batch in training_dataset:
# Train modelWe can serve features in production once we deploy our trained model as well.
import featureform as ff
client = ff.ServingLocalClient()
fpf = client.features([("avg_transactions", "quickstart")], ("CustomerID", "C1410926"))
# Run features through modelWe can use the feature registry to search, monitor, and discover our machine learning resources.
- To contribute to Embeddinghub, please check out Contribution docs.
- Welcome to our community, join us on Slack.
Please help us by reporting any issues you may have while using Featureform.