
This project goal is to write a software pipeline to detect vehicles in a video. Also this document will describe in details the algorithms and technics used in the pipeline.
The goals / steps of this project are the following:
- Perform a Histogram of Oriented Gradients (HOG) feature extraction on a labeled training set of images and train a classifier Linear SVM classifier
- Optionally, you can also apply a color transform and append binned color features, as well as histograms of color, to your HOG feature vector.
- Note: for those first two steps don't forget to normalize your features and randomize a selection for training and testing.
- Implement a sliding-window technique and use your trained classifier to search for vehicles in images.
- Run your pipeline on a video stream (start with the test_video.mp4 and later implement on full project_video.mp4) and create a heat map of recurring detections frame by frame to reject outliers and follow detected vehicles.
- Estimate a bounding box for vehicles detected.
The pipeline consists of two independent parts: lanes detection part and vehicles detection part. This document describes only vehicles detection part. Another part was described in previous project.
The software uses SVM classifier which requires images for training. The archives with images are located at train_data directory and should be unpacked there. Interesting thing is that the classifier requires not only vehicle images to train but also non-vehicle. There are almost 9000 images of both vehicle and non-vehicle type:
Cars: 8792 , non-cars: 8968
The classifier can't process images directly. It requires features vector at input what is derived from the image. There are different schemes for retrieving features vector from the image:
- Spatial Binning of Color


Actually it is simple scale down to desired size. The smaller is size the wider is the range of matching samples.
- Histograms of Color
Histogram of selected channels in selected color space.
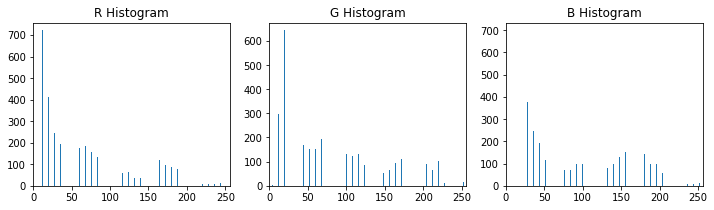

The length of this features vector is determined by bins count.
- Histogram of Oriented Gradient (HOG) features
Good method that can describe the shape of an object.


The key parameters are: orientations, pixels per cell, cells per block
- Color space
Here is are some color spaces
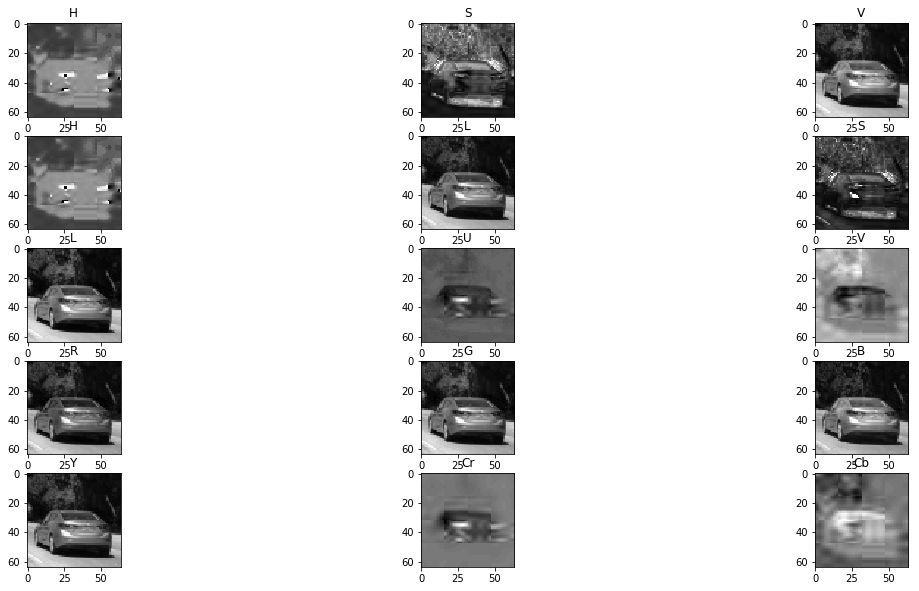

I selected the following key parameters for features extraction:
color_space = 'YCrCb' # Can be RGB, HSV, LUV, HLS, YUV, YCrCb
orient = 9 # HOG orientations
pix_per_cell = 8 # HOG pixels per cell
cell_per_block = 2 # HOG cells per block
hog_channel = 2 # Can be 0, 1, 2, or "ALL"
spatial_size = (24, 24) # Spatial binning dimensions
hist_bins = 16 # Number of histogram bins
spatial_feat = True # Spatial features on or off
hist_feat = True # Histogram features on or off
hog_feat = True # HOG features on or off
All parameters were found manually by probing different values and checking the results.
I used Linear SVM classifier with default parameters. The trainig code can be found in Jupyter notebook (block In [4])
Using: 9 orientations 8 pixels per cell and 2 cells per block
Feature vector length: 7068
20.23 Seconds to train SVC...
Test Accuracy of SVC = 0.9885
To perform actual pattern search on the test image, it should be divided onto small chunks and passed into classifier to detect whether corresponding chunk is a vehicle or not. Vehicle size is different for different distances, so we need to perform scaling of a sliding window:



Combining all found patterns will give the following image:

Different scaling windows uses different parameters (like overlapping). All parameters were found manually by experiments.
As you can see in previous picture there are some false positives.
To workaround this issue a Hot Map algorighm is used:

We simply create a matrix with the same dimension as input image and increment each matrix cell by one when the cell belongs to the vehicle rectangle. Then we performs thresholding which zeroes all cells with value lower than specified. Effectively this means that the resulting matrix will persist only these regions that contains at least specified as threshold number of rectangles. So single (or even double in my case) rectangles will be dropped out. Yet another operation is make a heat-map like a binary so it will contains only 0 and 1. This is important for the next step.
Next step is multi-frame filtering. We simply preserves last 10 heatmap matrices, calculate mean matrix and perform yet another threshold operation with value 0.8 This will effectively drop out rectangles that is visible less than 80% of last 10 frames of video:

This filtering eliminates most of false positives.
Finally we can conbine lanes finding image with vehicles detection image:

There are still some visible false positived on the video. It is possible to adjust different constants to eliminate it however such adjusting is very specific and will not work for another videos.
Another great issue is very high processing time. Processing of one frame takes 17 seconds which is inadmissible high value (processing whole video took almost 6 hours on i7 3770!!!). The main reasons of so big value are: using YCrCb color space, too many sliding windows (especially 64x64) with high overlapping value, single thread execution, not so effective algorithm in general.
Obviously this solution can't be used for real-time processing.