
This is a lab exercise for the Metaparse library. After completing it, you will see how you can use Metaparse to embed a DSL into C++.
This lab creates a DSL for regular expressions. Boost provides a library, Boost.Xpressive as a DSL for regular expressions, however, the users of the library have to choose either compile-time validation or using the widely used syntax for defining regular expressions. In this lab we will provide an interface for Boost.Xpressive that accepts the widely used syntax for regular expressions and does the compile-time validation of it.
You are expected to be familiar with the C++ language. Having template metaprogramming experience makes your life easier but you can complete this tutorial without it. It contains a short introduction to Boost.Xpressive and to template metaprogramming as well for those who are not familiar with them. The goal here is not to master these things, but to know enough about them to complete the rest of the tutorial.
- Slides
- Lab environment
- Tutorial
- Solutions to the exercises
- Acknowledgement
- License
A slidehsow presenting this tutorial is available in PDF format.
To complete this lab you need the following tools in your working environment:
- A Linux system
- A compiler supporting C++11
- The Boost libraries
- GNU Make
- Git
First you need to clone the tutorial's Git repository somewhere to set the lab environment up. You can do it by running the following command:
git clone https://github.com/sabel83/metaparse_tutorial.gitThis will create the directory metaparse_tutorial for you which you should go
into:
cd metaparse_tutorial/labYou can try building the lab now:
makeThis will build the empty lab exercises and run the tests. If your environment has been set up correctly, this should exit without an error. If this is the case, you can get started.
Each exercise consists of a header file (lab?.hpp) and a test code
(lab?.cpp). To complete an exercise, you need to edit the .hpp file. When
you compile the project using make, it will compile the tests validating your
code. To make it always compilable, the tests in the .cpp files are commented
out. Once you have implemented a lab or part of it, you can uncomment a test
and try building the project. You should not make any changes to the .cpp
files other than removing comments.
As this tutorial builds a new interface for Boost.Xpressive, you need to have some Boost.Xpressive knowledge. Here is a simple example using Boost.Xpressive:
#include <boost/xpressive/xpressive.hpp>
#include <iostream>
int main()
{
using boost::xpressive::sregex;
using boost::xpressive::smatch;
sregex re = sregex::compile("ab*c");
smatch what;
if (regex_match("abbbbbbbc", what, re))
{
std::cout << "It works" << std::endl;
}
else
{
std::cout << "Something is wrong here..." << std::endl;
}
}This example defines a regular expression object, re, initialises it with the
regular expression ab*c and tries to match it to the string abbbbbbbc. To
get the sregex and smatch types, the example included
boost/xpressive/xpressive.hpp.
It is time to complete the first lab. Take a look at lab1.cpp, which assumes
that a number of regular expression objects (regex_...) are defined and tests
these regular expressions. The all_tests function call takes the regular
expression as argument and tries to match it to a number of strings. In
lab1.hpp you need to define these regular expression objects. Once all of the
validations in lab1.cpp pass, you can proceed.
We have embedded the regular expressions in the code as string literals. The
library does not look into these string literals until runtime. When the
sregex::compile function is called, the content of these string literals is
parsed and the matching object is constructed. Boost.Xpressive calls these
regular expressions dynamic regexes. The nice thing about this approach is
that there are no restrictions for the grammar used inside the string literal.
It is parsed by a runtime C++ code, thus the regular expressions can follow the
widely used and known syntax. The problem with this approach is that the library
does not look into the string literals until runtime. No typos or other errors
are detected until runtime and there is no chance of optimisation either.
Another approach Boost.Xpressive offers is called static regexes. The idea here is that valid C++ expressions can be interpreted as regular expressions. For example:
#include <boost/xpressive/xpressive.hpp>
#include <iostream>
int main()
{
using boost::xpressive::sregex;
using boost::xpressive::smatch;
using boost::xpressive::as_xpr;
// ab*c
sregex re = as_xpr('a') >> *as_xpr('b') >> as_xpr('c');
smatch what;
if (regex_match("abbbbbbbc", what, re))
{
std::cout << "It works" << std::endl;
}
else
{
std::cout << "Something is wrong here..." << std::endl;
}
}This code does the same thing as the previous one, but it uses a static regex
instead of a dynamic one. The expression
as_xpr('a') >> *as_xpr('b') >> as_xpr('c') defines the regular expression the
following way:
- The
as_xprfunction can turn a character value into a regular expression matching that value. operator*represents the*operator of regular expressions. Since in C++ this is a prefix operator, it goes beforeas_xpr('b')in the C++ code.operator>>concatenates two regular expressions.
Note: you don't need to use
as_xpreverywhere, the above regular expression can be simplified the following way'a' >> *as_xpr('b') >> 'c'and it will still work. When an operator used by Xpressive has an argument of typecharit is automatically treated as a regular expression matching that character. What you have to make sure is that every operator has at least one argument that is really a regular expression (eg. the result ofas_xpror some other expression building a regular expression). Otherwise it would be treated as an operator call oncharvalues. For example'a' >> 'b'is a right-shift of the value'a'by'b'. This tutorial will always useas_xprto make things explicit and easy to follow.
There is an important regular expression you will need: the empty regular
expression. As a dynamic regular expression, you can create it by
sregex::compile(""). This has a static version as well, which is
boost::xpressive::nil.
Take a look at lab2.cpp and lab2.hpp - they are the same as lab1.cpp and
lab1.hpp were. You need to complete the same exercise again, but this time
using static regular expressions. Once all validations pass, you can continue.
You are now familiar with the construction of static regexes using Boost.Xpressive. They are validated at compile-time and can be optimised, however, the syntax of the regular expressions is constrained by the fact that a regular expression has to be a valid C++ expression. Take a look at the regular expressions you have created. If someone already familiar with regular expressions but not with Boost.Xpressive finds them in a code, he will not understand what they are or what they mean.
In the rest of this tutorial we will create a DSL that takes a string literal containing a regular expression in its common form and generating a static regex out of it. We will be using Metaparse for this. It is a header-only library and the headers (among the rest of the Mpllibs headers) are included in the code you have downloaded for the labs. You can find the documentation of Metaparse (including its reference which you will need during this lab) at http://abel.web.elte.hu/mpllibs/metaparse.
Metaparse can be used to embed DSLs into C++ using template metaprogramming.
Thus a template metaprogram takes the string literal containing the regular
expression as input and produces the static regex as its result. You may wonder
how a template metaprogram can parse a string - it is a long story. For now it
is enough that it is possible. You can look at the Metaparse manual or the
related papers for further information. You may also wonder how a template
metaprogram can build a regular expression. This thing is important for you to
understand. Template metaprograms return types - and only types. But a type
can be a class with a static method that builds some object - for example an
sregex object. Here is an example for this:
struct r_a
{
static <<< type of xpressive::as_xpr('a') goes here >>> run()
{
return xpressive::as_xpr('a');
}
};This class, r_a has a public static run() method. When this run() method
is called, it builds a matching object for the regular expression a. As r_a
is a class, it could be the result of a template metaprogram. The only thing
missing from the above piece of code is the return type of run(), which is the
type of the expression we are returning. This can be implemented the following
way:
struct r_a
{
static decltype(xpressive::as_xpr('a')) run()
{
return xpressive::as_xpr('a');
}
};decltype(...) means the return type of the ... expression. The above code
has to repeat the expression it returns twice: once for figuring out the type of
this expression and once for really returning it. Using a macro similar to the
one Dave Abrahams suggested here can save us from writing that expression twice:
#define RUN(...) \
static decltype(__VA_ARGS__) run() { return (__VA_ARGS__); }This macro takes the expression to return as argument and defines the run
function. Using it, r_a can be implemented the following way:
struct r_a
{
RUN(xpressive::as_xpr('a'))
};This code contains the expression to return only once and uses the preprocessor to duplicate it and generate code the compiler expects.
So the process of turning a string literal into a matching object is the following:
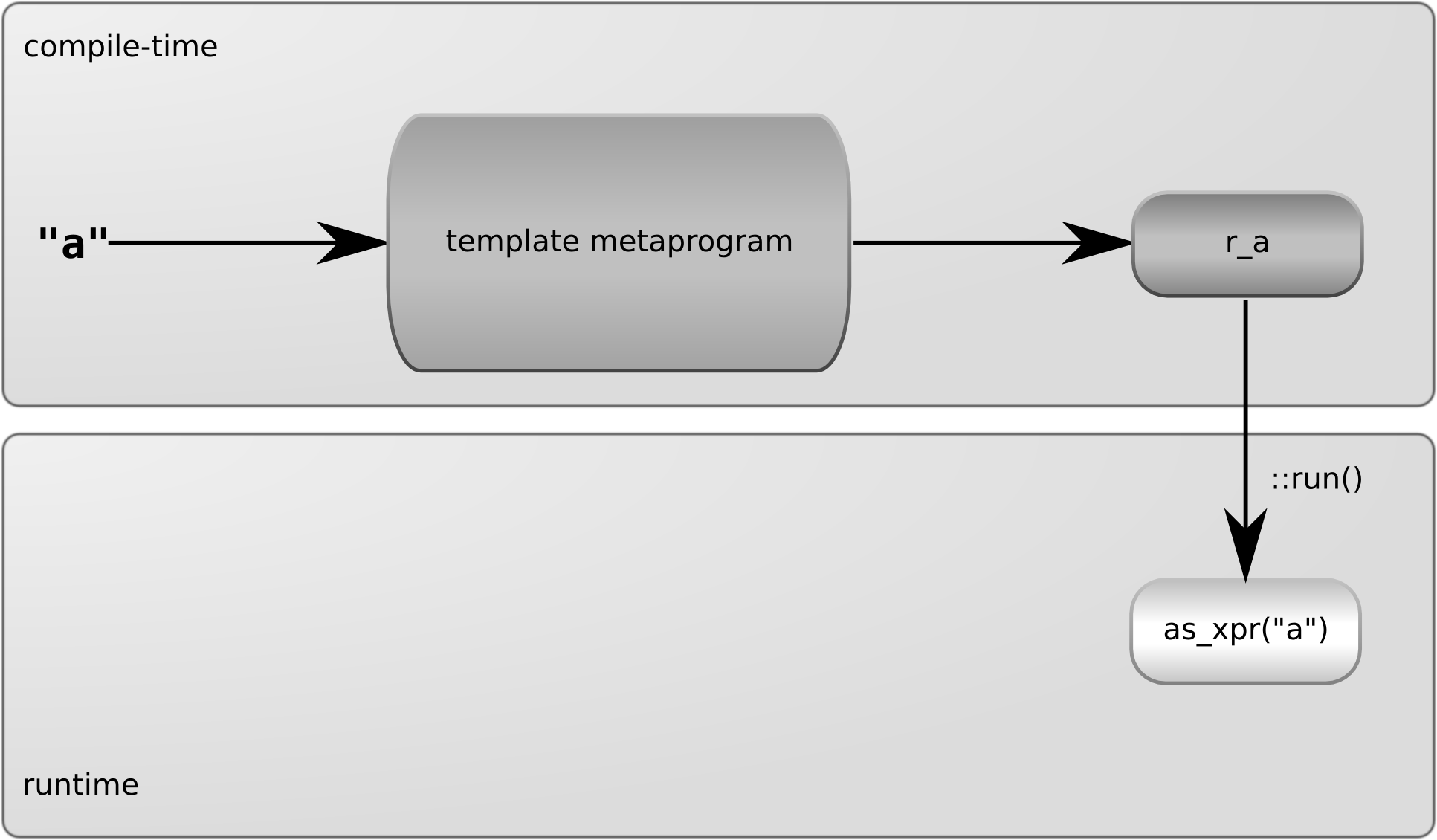
- Pass the string literal to a template metaprogram
- The template metaprogram returns a class with a public static
run()method - Calling the
run()method of the result constructs the matching object (at runtime)
Since the class r_a will be the result of a template metaprogram, it has to
be a template metaprogramming value. It is important for template metaprograms to be able to deal with it
properly. r_a being a template metaprogramming value means that r_a::type
has to be a typedef of r_a. This requirement is easy to fullfill
(unfortunately it is that easy to forget as well):
struct r_a
{
typedef r_a type;
RUN(xpressive::as_xpr('a'))
};This version of r_a has an extra typedef r_a type;. This defines the nested
type type pointing to itself. What you need to remember is that when you are
creating classes that are meant to be used by template metaprograms, they should
have this extra typedef pointing to themselves.
We have seen how to create a class representing the matching object of the
regular expression a but how this approach can be used in a real solution?
Before moving on, you need to get familiar with how regular expressions can be
represented as classes.
As a first step, r_a can be generalised. Instead of having a class
representing the regular expression a, we can have a template class, whose
instances represent regular expressions accepting one specific character. The
character they accept can be the template argument:
template <char C>
struct r_char
{
typedef r_char type;
RUN(boost::xpressive::as_xpr(C))
};This code defines the template class r_char. It has one template argument,
which is the character to accept. It works the same way as r_a worked, it is a
generalisation of it. r_a can be defined using it:
typedef r_char<'a'> r_a;This code defines r_a by instantiating r_char with the 'a' character.
Template metaprograms operate on types and not on constant values like 'a'. In
order to make template metaprograms be able to operate on the value 'a', it
has to be turned into a type. The C++11 standard library provides a template
class that can do this:
#include <type_traits>
typedef std::integral_constant<char, 'a'> type_a;This code defines the type type_a. This type represents the 'a' character.
This is a type, thus it can be passed around in template metaprograms. This type
has a public static constant called type_a::value. The type of it is char
and the value is 'a', thus it can be used to get the value back. Boost.MPL
provides a similar wrapper:
#include <boost/mpl/char.hpp>
typedef boost::mpl::char_<'a'> type_a;This example uses boost::mpl::char_ instead of std::integral_constant but
does the same. The Boost version can be used when the standard library being
used does not support std::integral_constant.
To ensure better integration into the template metaprograms later, r_char
should take these wrapper types instead of the plain char value as template
argument:
template <class C>
struct r_char
{
typedef r_char type;
RUN(boost::xpressive::as_xpr(C::type::value))
};This is an implementation of r_char that takes a boxed character value as
template argument. Since as_xpr is a runtime function taking runtime char
values as arguments, this boxed character value needs to be unboxed by accessing
its ::value. The above code uses C::type::value instead of just C::value.
This makes r_char work better with lazy template metaprograms. You should use
::type::value instead of just ::value to make your code work better with
lazy metaprograms. Since boxed character values are template metaprogramming
values, you can use ::type safely on them, since it is just a typedef of
themselves. If you want to understand where and why it makes a difference, you
can read about lazy metafunctions.
We can represent simple regular expressions by classes. Now let's try to do
something more complex, such as representing the regular expression ab as a
class. This regular expression can be constructed by concatenating the regular
expressions a and b:
using boost::xpressive::as_xpr;
struct r_ab
{
typedef r_ab type;
RUN(as_xpr('a') >> as_xpr('b'))
};This code creates the matching objects for the regular expressions a and b
using as_xpr and concatenates them using operator>>. This solution works but
again, this is not general enough, so let's generalise it a bit. First, the
matching object of the regular expressions a and b can be constructed using
the instances of the r_char template class, so let's use that:
using boost::mpl::char_;
struct r_ab
{
typedef r_ab type;
RUN(r_char<char_<'a'>>::run() >> r_char<char_<'b'>>::run())
};This code looks more difficult than the previous one. Instead of creating the
matching objects of the regular expressions a and b directly, it creates
them by using different instances of r_char. We did it because
r_char<char_<'a'>> and r_char<char_<'b'>> are just classes - they don't need
to be hard-coded into r_ab. r_ab can be turned into a template class and
these two classes can be template arguments:
template <class A, class B>
struct r_concat
{
typedef r_concat type;
RUN(A::run() >> B::run())
};This code is a general template class representing regular expression
concatenation. It has two template arguments, A and B which are the classes
representing the two regular expressions to be concatenated. The run() method
of this template class builds the matching objects of these regular expressions
by calling A::run() and B::run() and concatenates them using operator>>.
Again, to make it work better with lazy metaprograms, ::type::run() can be
used instead of ::run():
template <class A, class B>
struct r_concat
{
typedef r_concat type;
RUN(A::type::run() >> B::type::run())
};This code does the same as the previous one, but instead of calling ::run() of
its arguments, it calls ::type::run() to work better with lazy metaprograms.
r_concat can be used to represent r_ab:
typedef
r_concat<
r_char<boost::mpl::char_<'a'>>,
r_char<boost::mpl::char_<'b'>>
>
r_ab;This code implements r_ab by instantiating r_concat with the types
representing the regular expressions a and b. r_concat can concatenate any
regular expressions. For example it can be used to represent the regular
expression abc as a type:
typedef
r_concat<
r_concat<
r_char<boost::mpl::char_<'a'>>,
r_char<boost::mpl::char_<'b'>>
>,
r_char<boost::mpl::char_<'c'>>
>
r_abc;This code uses r_concat twice: it builds the type representing the regular
expression ab by concatenating the types representing the regular expressions
a and b and then it concatenates this type with the type representing the
regular expression c.
What we have built so far seems to be correct. If we try using it, our code will
compile but will crash at runtime. The reason behind that is that the expression
A::type::run() returns a temporary object. The >> operator creates a new
object that references this temporary (and the result of B::type::run() as
well) and that is the problem. The temporary objects are destroyed by the time
we return from r_concat::run - but we return a new object we have just created
using the >> operator. And this new object refers to the temporaries that are
already destroyed.
The following diagrams illustrate the problem. First r_concat::run() calls
A::type::run() and B::type::run() to build the two regular expressions to be
concatenated:
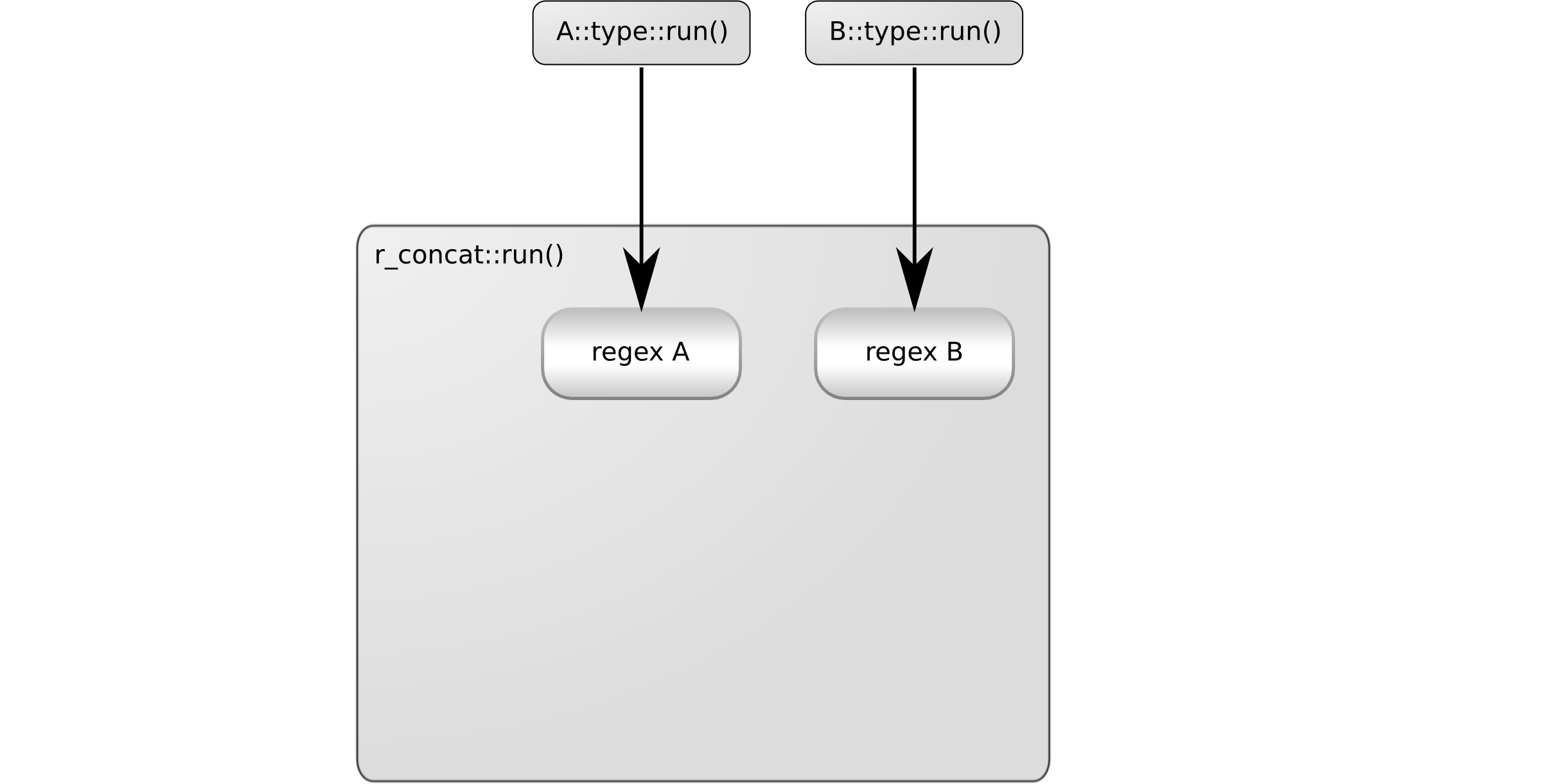
The two regular expression objects to be concatenated a represented as regex A
and regex B. As the next step, r_concat::run() concatenates them using
operator>>:
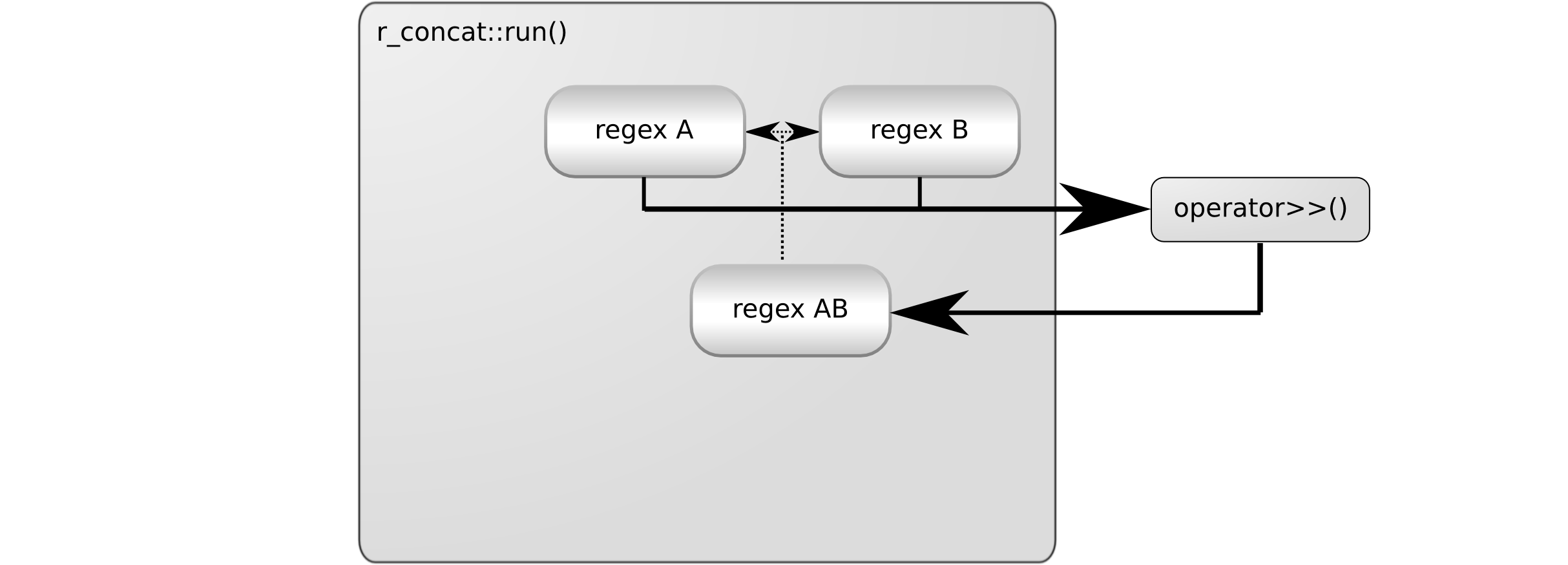
The resulting regular expression object (regex AB) contains references to the
original objects we have concatenated. r_concat::run() returns this object:
The problem here is that the temporary objects, regex A and regex B are
destroyed, but the object returned still references them.
This problem can be avoided by making a copy of the temporaries. Boost.Proto
(the library used by Xpressive) provides a tool for this:
boost::proto::deep_copy. It can take the object created by the >> operator
and make a copy of it. This makes a copy of the temporaries as well, thus it
will fix the above problem. It can be used the following way:
using boost::proto::deep_copy;
template <class A, class B>
struct r_concat
{
typedef r_concat type;
RUN(deep_copy(A::type::run() >> B::type::run()))
};This code makes a copy of the result of the >> operator. This is a deep copy,
thus everything being referred to is also copied. This way the resulting object
does not refer to any temporary and will not crash at runtime. The following
diagrams illustrate how deep_copy works:
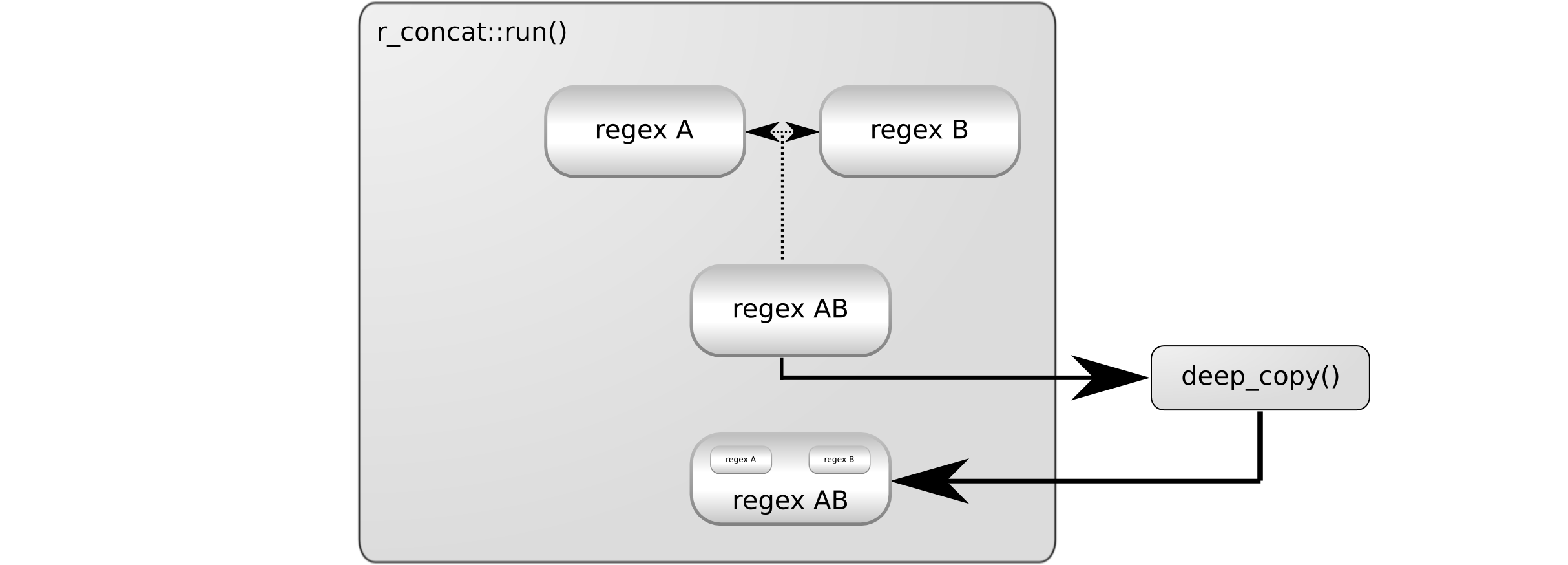
deep_copy made a copy of the object operator>> created and this copy
contains a copy of regex A and regex B, thus the original temporary objects
are not referenced by this. r_concat::run() can safely return it:
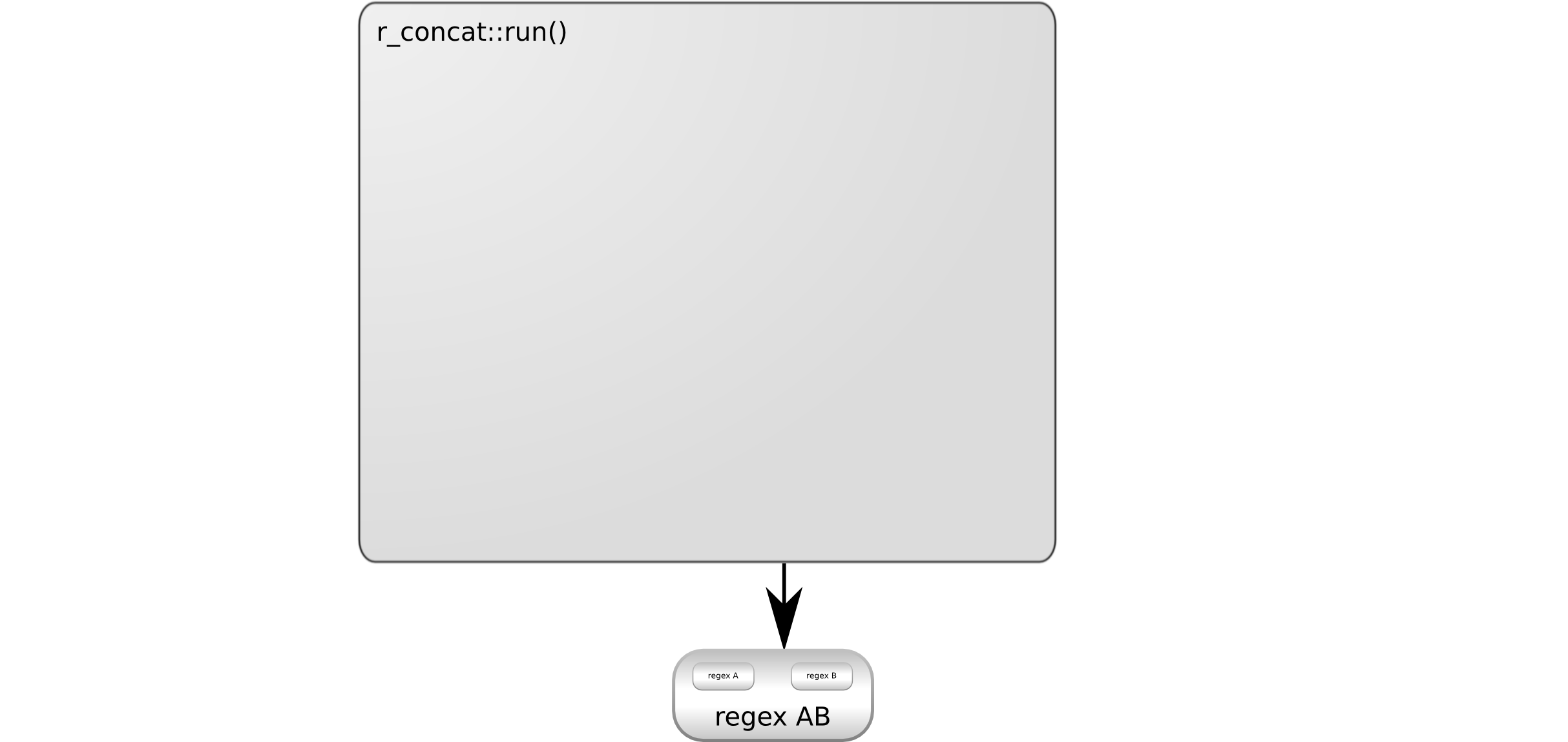
Returning the copy of regex AB containing all of its references does not cause
issues, since it does not refer to any already destroyed object.
Every time you write a run function building a new regular expression object
out of an existing one (and you will be doing that several times in the lab),
you will need to use deep_copy to avoid this problem.
As you can see, these classes can be used to build regular expressions. They provide a new way of representing regular expressions in C++ code. These regular expressions are hardly readable, but they can be constructed by instantiating template classes with classes as their arguments - things that template metaprograms can also do.
Thus, as a first step of implementing the DSL for regular expressions, you need
to build these classes representing regular expressions. This is what you do in
lab 3. Take a look at lab3.cpp. It tests regular expressions built using these
classes. In lab3.hpp you need to implement these classes yourself:
r_empty: it's run should return an empty regular expression.r_dot: it's run should return a regular expression matching any character. This class represents the regular expression.r_star: this represents the*element of regular expressions.r_concat: this represents the concatenation of two regular expressions.r_char: this represents a regular expression matching one specific character.
lab3.hpp already contains the declarations of these classes and template
classes. You need to implement them. Once all the validations succeed, you can
continue this tutorial.
Now we will learn some template metaprogramming. Don't worry, we will not go deeply into this topic. We will only cover things that you will need to complete this tutorial - and this is probably less than what you'd expect.
Template metafunctions are the basic building blocks of template metaprograms. They represent things that can be called at compile-time. They take types as arguments and return a type as the result. They are implemented using template classes. Thus, a template metafunction is a template class. The template arguments are the arguments of the function. Let's look at an example:
template <class T>
struct add_const;This is the declaration of the add_const template metafunction. It takes one
type, T as argument. Its name suggests that it should return the const
version of its argument. For example calling it with int should give
const int, calling it with double should give const double, etc. Template
metafunctions have a nested type called type. This represents the result of
the metafunction call. Thus, to call the above metafunction and turn the type
int into const int, we should do the following:
add_const<int>::typeThe above should refer to a type, which should be a typedef of const int.
Implementing add_const to work this way is simple:
template <class T>
struct add_const
{
typedef const T type;
};The above code has a typedef inside the add_const template class defining
::type. This definition is the body of the template metafunction.
Another template metafunction, add_volatile can be implemented in a similar
way:
template <class T>
struct add_volatile
{
typedef volatile T type;
};This metafunction builds the volatile version of a type. Let's build a third
template metafunction, add_cv, which builds the const volatile version of a
type. But since we already have add_const and add_volatile, we should use
them.
template <class T>
struct add_cv
{
typedef
typename add_volatile<
typename add_const<T>::type
>::type
type;
};This implementation calls add_const<T> to build the const version of the
type T and calls add_volatile with the result of it to build the
const volatile version. The result of this second call is the result of
add_cv. As you can see, we had to use the typename keyword at several
places. This is because there are many dependent names in the above
definition.
If you take a closer look at the above definition, you can see that add_cv
returns the result of another metafunction call. This means, that the ::type
of add_cv will be the ::type of add_volatile. Instead of using typedef
the way we did in the above example, we could use inheritance: add_cv could
publicly inherit from add_volatile and inherit the ::type of add_volatile:
template <class T>
struct add_cv : add_volatile<typename add_const<T>::type> {};Now add_cv inherits from add_volatile. When someone tries accessing
add_cv<...>::type, he will access add_volatile<...>::type, but that is fine.
That is exactly what the first version of add_cv did as well. This technique
is called metafunction forwarding and it makes the code more compact.
Now as you know what template metafunctions are, you should try writing one
yourself. Take a look at lab4.cpp and lab4.hpp. In this exercise you need to
write a metafunction called beginning_and_end. It takes a string as input and
returns a pair of characters: the first and the last character of the string.
Don't worry, the Boost.MPL library gives you everything you need to complete
this task:
- It provides a template class called
boost::mpl::pairwhich you can use to represent pairs of values. - It provides two useful template metafunctions:
boost::mpl::frontandboost::mpl::backthat can be used to get the first and the last character of a sequence. As strings are sequences of characters, they work for strings as well.
You can take a look at the reference of Boost.MPL to see how these things work and how they can be used. Once your metafunction passes all the validations for this task, you can proceed.
We have seen how to write functions that can be called at compile-time. Now we
will look at writing higher order metafunctions, which are metafunctions
taking metafunctions as arguments (or returning them as the result). As an
example for this, let's write a transform_pair function:
template <class Pair, class F>
struct transform_pair;This metafunction takes two arguments: a pair (e.g.
boost::mpl::pair<int, double>) and a function (e.g. add_const). We expect it
to call the function on both elements of the pair and give the pair of the
results back, thus for example:
transform_pair<
boost::mpl::pair<int, double>,
add_const
>::typeWe expect to receive boost::mpl::pair<const int, const double> as the result.
But there is a problem here: add_const is a template class, which is not a
type. Instances of this template class are types, but not the template itself.
Thus, we can not pass add_const as a class template argument and the above
code would not compile. A solution for this problem is wrapping the metafunction
with a class:
struct add_const
{
template <class T>
struct apply
{
typedef const T type;
};
};This code defines a class, add_const which has a template metafunction called
apply in it. It can be called the following way:
add_const::apply<int>::typeAs you can see, calling this is similar to calling a "normal" metafunction. The
metafunction is called add_const::apply instead of add_const. What did we
achieve with this? add_const is a type now, thus this is valid C++ code:
transform_pair<
boost::mpl::pair<int, double>,
add_const
>::typeThe implementation of transform_pair should be aware of that how it can call
the function. transform_pair can be implemented the following way:
template <class Pair, class F>
struct transform_pair :
boost::mpl::pair<
typename F::template apply<typename Pair::type::first>::type,
typename F::template apply<typename Pair::type::second>::type
>
{};The code has a lot of typename and template keywords in it which makes it
look complicated for the first time. Unfortunately these keywords have to be
there to make it a valid C++ code. If we remove them, the code won't compile
but we can understand better what is going on:
template <class Pair, class F>
struct transform_pair :
boost::mpl::pair<
F::apply<Pair::type::first>::type,
F::apply<Pair::type::second>::type
>
{};transform_pair takes the first and second elements of Pair. To make it
work better with lazy metaprograms, it takes the first and second elements
of Pair::type. It calls the F::apply metafunction for both of these values
and constructs a pair of the results.
Note that naming is key here: the metafunction inside add_const has to be
called apply, otherwise functions like transform_pair would not be able to
find it. Classes like add_const - with a nested metafunction called apply -
are called template metafunction classes.
As template metafunction classes are used as values in template metaprograms,
they should be template metaprogramming values. For add_const it means that
add_const::type should be a typedef of add_const itself. Template
metaprogramming values are types with a ::type pointing to themselves. Thus,
the complete implementation of add_const is the following:
struct add_const
{
typedef add_const type;
template <class T>
struct apply
{
typedef const T type;
};
};This implementation has a ::type pointing to itself to make it a template
metaprogramming value and a metafunction called ::apply to make it a
template metafunction class.
Take a look at lab5.cpp. It is similar to lab4.cpp, you will have to
implement the same beginning_and_end function, but this time you will have to
implement it as a template metafunction class. Once your code passes all the
validations, you can continue this tutorial.
We have everything to generate regular expressions from template metaprograms.
We need to start writing the metaprograms turning string literals into regular
expressions. For example the string literal "abc" should be turned into the
following class:
r_concat<
r_concat<
r_char<boost::mpl::char_<'a'>>,
r_char<boost::mpl::char_<'b'>>
>,
r_char<boost::mpl::char_<'c'>>
>This class represents the same regular expression as the string "abc". Calling
the ::run() method of this class builds the appropriate matching object.
Turning the string representation of the regular expression into the above
structure is a compilation process, thus to do this, we need to write a
compiler as a template metaprogram. Fortunately this thing is well supported by
the Metaparse library.
To write a compiler for regular expressions, the first step is writing a grammar. This tutorial will support only a subset of regular expressions. We will support only the following:
- letters and numbers (eg.
abc123) .*- brackets (eg.
(abc)*)
Here is a grammar that you can use in this tutorial (assuming that you could write it yourself as well):
reg_exp ::= unary_item*
unary_item ::= item '*'?
item ::= any | bracket_exp | char_
any ::= '.'
bracket_exp ::= '(' reg_exp ')'
char_ ::= number | letter
number ::= '0'..'9'
letter ::= 'a'..'z' | 'A'..'Z'
The start symbol of this grammar is reg_exp.
Metaparse can be used to build
parsers. A parser is a template metafunction class. The arguments of these
metafunctions have to be types and they return a type as the result. Thus, the
parser for the regular expressions should be a metafunction class taking the
string representation of the regular expression as argument and returning the
type representation of it as the result. For example when it is called with the
string "abc", it should return
r_concat<
r_concat<
r_char<boost::mpl::char_<'a'>>,
r_char<boost::mpl::char_<'b'>>
>,
r_char<boost::mpl::char_<'c'>>
>A parser takes the input string as an argument (and some other information that is used for error reporting) and does one of the following:
- It accepts the input, consumes a prefix of it. In this case it returns the unconsumed suffix of the input and some result. This result can be anything, it is up to the parser. This is the result of parsing.
- It rejects the input. In this case it returns some meaningful error message. This tutorial does not deal with error reporting from parsers. For further information on that, you can read about error handling in Metaparse.
Let's start implementing the above grammar. We will be building it bottom-up.
We can start with the number symbol, which accepts a digit character. This is
so common, that Metaparse provides a parser doing this. This parser is called
letter. When parsing is successful, the result is the accepted character. As
metafunctions return types, it will be a boxed character value (e.g. with
boost::mpl::char_ as we have seen earlier). The letter symbol can be
implemented in a similar way, using the letter parser provided by Metaparse.
As the next step, we can implement the char_ parser. This is either a number
or a letter. Its definition was the following:
char_ ::= number | letter
Metaparse provides the one_of template class which can be used to represent
the | symbol used in the grammar. Using it the implementation of the char_
symbol is straight forward:
typedef
mpllibs::metaparse::one_of<
mpllibs::metaparse::letter,
mpllibs::metaparse::digit
>
char_;This is the template metaprogramming equivalent of the above grammar rule:
a char_ is either a letter or a digit. The result of char_ is the result
of letter or digit - depending on which one succeeded, but either way it is
the character the letter or the digit parser accepted. But we want our
parsers to return the types representing regular expressions as their results
and not character values. For example when the input is "a" we don't want the
char_ parser to return the character 'a' returned by the letter parser.
We want the r_char<boost::mpl::char_<'a'>> type instead.
Metaparse provides the transform template class for this. As its name
suggests, it can be used to transform the result of a parser. It has two
arguments: a parser and a metafunction class. Instances of transform are
parsers: they parse the input and transform the result using the metafunction
class. We can use it to make char_ return a regular expression:
struct build_char_
{
typedef build_char_ type;
template <class C>
struct apply;
};
typedef
mpllibs::metaparse::transform<
mpllibs::metaparse::one_of<
mpllibs::metaparse::letter,
mpllibs::metaparse::digit
>,
build_char_
>
char_;This code transforms the result of one_of using build_char_. char_ is a
parser taking an input string. If either letter or digit accepts it, char_
accepts it as well. The result of parsing is what build_char_ turns the
accepted character into. We want it to be a class representing a regular
expression. We need to implement build_char for that. build_char_ is a
template metafunction class with one argument: the character that was accepted
and should return an instance of r_char.
struct build_char_
{
typedef build_char_ type;
template <class C>
using apply = r_char<C>;
};The above code implements build_char_. It makes it a template metaprogramming
value by adding type and makes it a template metafunction class by adding the
apply metafunction. All it does is that it wraps its argument with r_char.
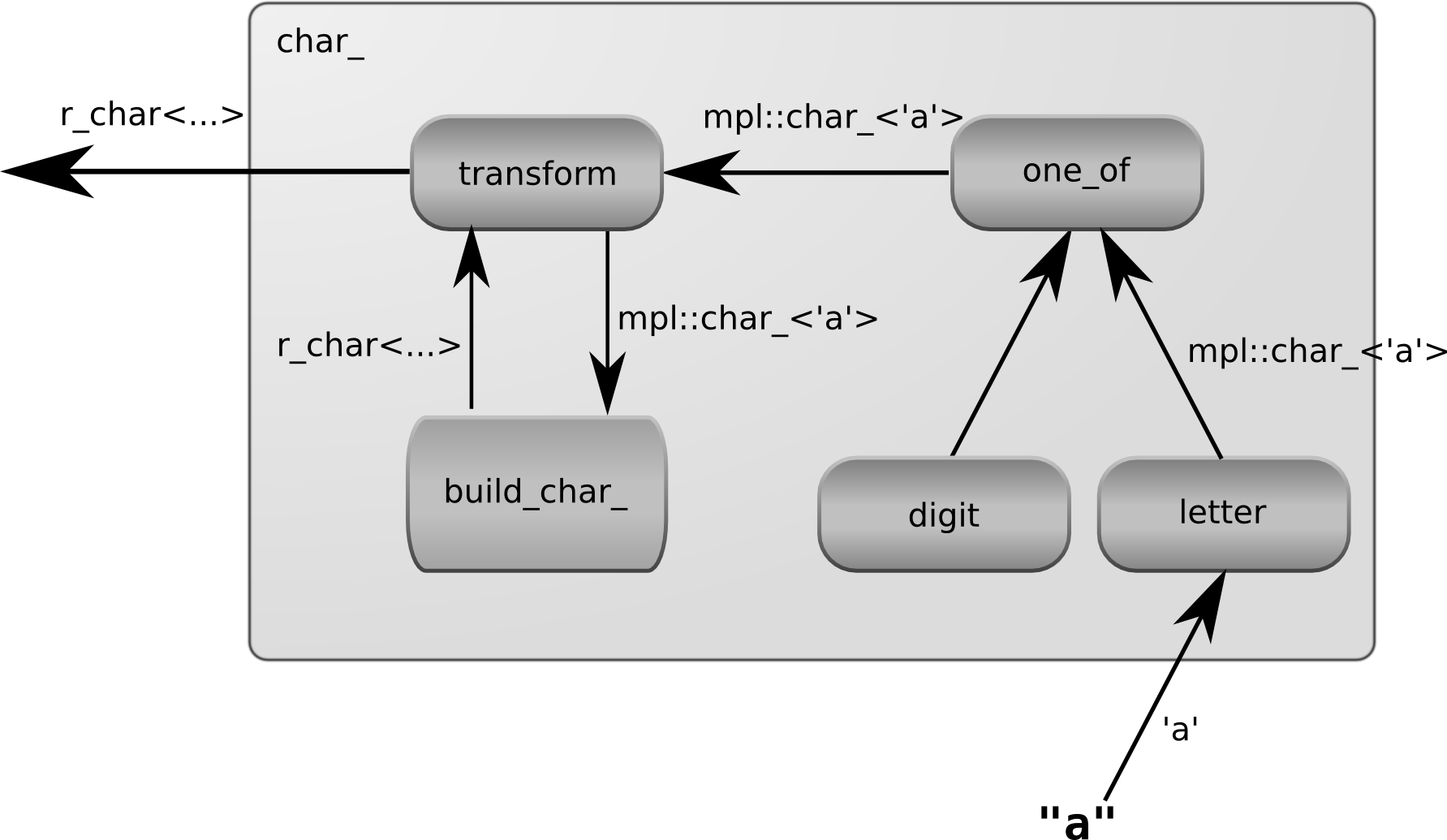
Now we have a char_ parser that accepts a letter or a digit and builds a type
from it that represents the appropriate regular expression. any can be
implemented in a similar way. We will cover bracket_exp later, we ignore it
for now, so we can implement item:
typedef mpllibs::metaparse::one_of<any, char_> item;We could use one_of again to build a parser that accepts either any or
char_. Once we have implemented bracket_exp, we can easily add this to the
list as well.
Now that we have item, we can implement unary_item. The tricky part there is
the optional '*' character. It can be implemented by a parser that:
- When there is a
'*'character, consumes it and the result of parsing is the'*'character. - When there is no
'*'character, consumes nothing. But there still has to be some result this parser returns. Metaparse provides thereturn_parser, that does this: it consumes nothing and returns some predefined value. So we can return some character that is not'*', for example'x'.
Based on this, we can implement this optional '*' the following way:
mpllibs::metaparse::one_of<
mpllibs::metaparse::lit_c<'*'>,
mpllibs::metaparse::return_<boost::mpl::char_<'x'>>
>This code uses one_of to apply either the parser consuming '*' or the parser
consuming nothing. The order is important, because one_of tries applying the
different parsers in order and chooses the first one that succeeds. If return_
was the first one, it would always succeed.
Now we can parse the optional '*' character, we can implement the unary_item
symbol. This is a sequence of an item and the optional '*'. Metaparse
provides the sequence template class for representing these sequences:
mpllibs::metaparse::sequence<
item,
mpllibs::metaparse::one_of<
mpllibs::metaparse::lit_c<'*'>,
mpllibs::metaparse::return_<boost::mpl::char_<'x'>>
>
>sequence is a parser. It applies all of its arguments in order and returns the
list of the results. We can process this list easily with all the tools
Boost.MPL provides for working on lists. But again, we want to build a regular
expression, so we need to transform this list into a regular expression. We
already know, that we can do it using transform:
typedef
mpllibs::metaparse::transform<
mpllibs::metaparse::sequence<
item,
mpllibs::metaparse::one_of<
mpllibs::metaparse::lit_c<'*'>,
mpllibs::metaparse::return_<boost::mpl::char_<'x'>>
>
>,
build_unary_item
>
unary_item;All we need to do is to write the build_unary_item metafunction class doing
the transformation. What will be the elements of this list? Since we have two
parsers in our sequence, it will be a two element list. The first element - the
result of the item parser - will be a regular expression. The second element -
the result of parsing the optional '*' character - will be a boxed character
value. build_unary_item should return the regular expression unchanged or
wrapped with a r_star depending on the value of the second argument.
We could use here a technique that is popular in functional languages: pattern
matching. We could write a template class taking two arguments: the regular
expression and the character value from the list (either '*' or 'x'):
template <class RegExp, char Repeat>
struct build_unary_item_impl;We have just declared it and instead of implementing it, we will be specialising
it. Once for '*' and once for 'x':
template <class RegExp>
struct build_unary_item_impl<RegExp, '*'> : r_star<RegExp> {};
template <class RegExp>
struct build_unary_item_impl<RegExp, 'x'> : RegExp {};This code specialises build_unary_item_impl for the two possible character
values and provides a different implementation for both. For '*', it wraps
RegExp with r_star, for 'x' it leaves it unchanged.
Having build_unary_item_impl, we can easily implement the build_unary_item
metafunction class:
struct build_unary_item
{
typedef build_unary_item type;
template <class S>
using apply =
build_unary_item_impl<
boost::mpl::front<S>,
boost::mpl::back<S>::type::value
>;
};This metafunction class gets the first and second element of the list built by
the sequence parser. As this is a two element list, these elements are the
first and last ones. It calls build_unary_item_impl with these elements to
get the result.
As we have implemented unary_item as well, we can now implement the start
symbol of the grammar, reg_exp. This is a number of unary_items. Let's look
at the syntax tree of the regular expression abc:
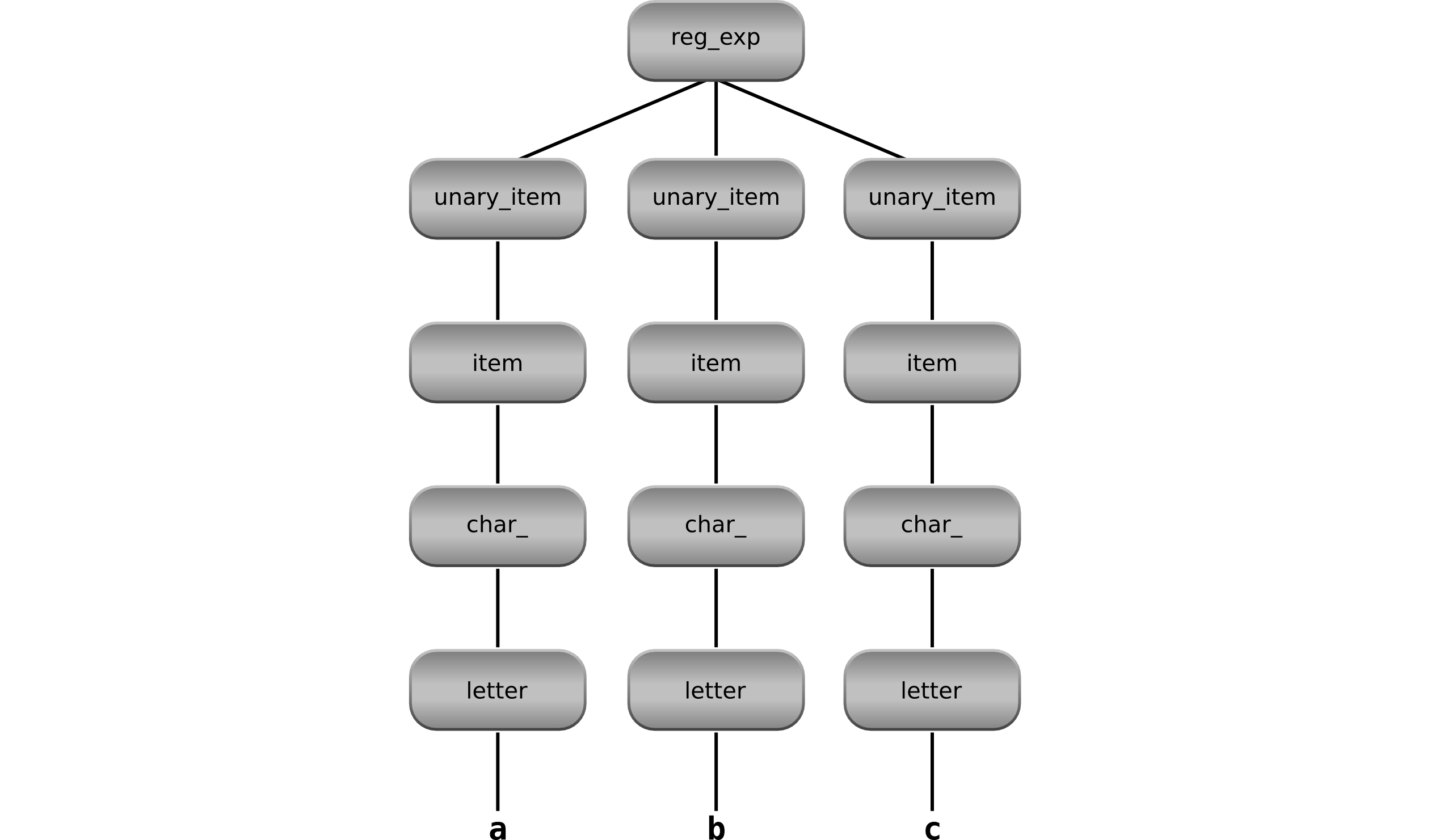
As you can see, reg_exp has three unary_item children. Each of them parsed
one character of the regular expression. The reg_exp parser should produce the
following type as the result of this:
r_concat<
r_concat<
r_concat<
r_empty,
r_char<boost::mpl::char_<'a'>>
>
r_char<boost::mpl::char_<'b'>>
>,
r_char<boost::mpl::char_<'c'>>
>There is an empty regular expression, represented by r_empty and the result of
every unary_item is appended to it using r_concat. This type can be
generated iteratively: we can start with r_empty and parse the characters one
by one. We parse the a character first using unary_item. The result of this
parsing will be r_char<boost::mpl::char_<'a'>>, thus we build the following
type:
r_concat<
r_empty,
r_char<boost::mpl::char_<'a'>>
>We then parse the next character, b using unary_item. The result of parsing
it will be r_char<boost::mpl::char_<'b'>>, thus we build the following type:
r_concat<
r_concat<
r_empty,
r_char<boost::mpl::char_<'a'>>
>
r_char<boost::mpl::char_<'b'>>
>We have appended the new regular expression to what we had before. We can keep
doing this until we reach the end of the input. Metaparse provides a template
class, foldl for doing this. It has three arguments:
- the parser that should be applied repeatedly (
unary_itemin our case) - the value we should start with (
r_emptyin our case) - a metafunction class adding a new result to what we already have
We can use it the following way:
struct build_reg_exp;
typedef mpllibs::metaparse::foldl<unary_item, r_empty, build_reg_exp> reg_exp;This code defines reg_exp using foldl. It uses the metafunction class
build_reg_exp for adding a new result to what we have. This metafunction class
needs to have two arguments: the new result coming from the last use of
unary_item and the value we have built so far. As the value we have built so
far is a prefix of the regular expression and the last result is the next
element of it, all this metafunction class has to do is concatenating these two
things:
struct build_unary_item
{
typedef build_unary_item type;
template <class NewExp, class OldExp>
using apply = r_concat<OldExp, NewExp>;
};build_unary_item has a type to be a template metaprogramming value and an
apply to be a metafunction class. It concatenates the old and the new regular
expressions using r_concat.
The only symbol we have not implemented yet is bracket_exp. It seems to be
easy to implement: it is a reg_exp in brackets, thus it is a sequence of
an opening bracket, a reg_exp and a closing bracket:
typedef
mpllibs::metaparse::sequence<
mpllibs::metaparse::lit_c<'('>,
reg_exp,
mpllibs::metaparse::lit_c<')'>
>
bracket_exp;The result of parsing should be a regular expression - the result of reg_exp.
The above parser returns a three element list containing the open bracket
character, the result of reg_exp and the close bracket character and we need
to return the middle element of this list. Metaparse provides a template class
that does this for us:
typedef
mpllibs::metaparse::middle_of<
mpllibs::metaparse::lit_c<'('>,
reg_exp,
mpllibs::metaparse::lit_c<')'>
>
bracket_exp;middle_of works as sequence, but it takes exactly three arguments and
returns only the result of the middle parser. The other two results are thrown
away.
The problem with this parser is that it refers to reg_exp, but reg_exp also
refers to bracket_exp. There is a recursion in the grammar. It doesn't matter
which one we try to define first, the compiler will complain, that the other one
it refers to is not defined yet. For example if we choose to implement
bracket_exp first:
typedef
mpllibs::metaparse::middle_of<
mpllibs::metaparse::lit_c<'('>,
reg_exp,
mpllibs::metaparse::lit_c<')'>
>
bracket_exp;
// ...
typedef mpllibs::metaparse::foldl<unary_item, r_empty, build_reg_exp> reg_exp;The compiler will complain, that bracket_exp refers to reg_exp, but no
reg_exp was defined at that point. If we do it in the reverse order, we get
the same error, as reg_exp refers to unary_item, which refers to item,
which refers to bracket_exp. So let's stick to the above order.
To make the compiler accept the definition of bracket_exp, we don't need to
define reg_exp before bracket_exp. It is enough to declare it.
Unfortunately a typedef can not be declared, thus instead of typedef we need
to use a struct and inheritance:
// The declaration of of reg_exp
struct reg_exp;
// Fine, reg_exp is declared
typedef
mpllibs::metaparse::middle_of<
mpllibs::metaparse::lit_c<'('>,
reg_exp,
mpllibs::metaparse::lit_c<')'>
>
bracket_exp;
// ...
struct reg_exp :
mpllibs::metaparse::foldl<unary_item, r_empty, build_reg_exp>
{};This code defines reg_exp as a struct that inherits from foldl. As it
inherits everything, it behaves as foldl and can be used the same way, thus it
still works as the parser of regular expressions. But given that a struct can
be declared, when the definition of bracket_exp refers to it, it works as
expected.
We have defined the entire grammar and have a parser that turns a string literal
into a regular expression. One last problem is that the result of a parser is
not just the result of parsing. It returns other information (eg. the
unprocessed suffix of the input). To turn a parser into a string -> regexp
function, we need to wrap it with something that throws everything but the
resulting regular expression away. Metaparse provides build_parser for this:
typedef mpllibs::metaparse::build_parser<reg_exp> regex_parser;regex_parser is a template metafunction class taking the string as input and
returning the type representing the regular expression as its result. It can be
used to turn the string literal "abc" into a matching object:
regex_parser::apply<MPLLIBS_STRING("abc")>::type::run()This code calls regex_parser with the string as its argument to get the type
representing the regular expression and calls the type's ::run() to build the
matching object.
What we have built so far works, but using it everywhere would add a lot of syntactic noise to the code. To avoid this, we can wrap this thing with a macro:
#define REGEX(s) (regex_parser::apply<MPLLIBS_STRING(s)>::type::run())This macro does all the plumbing that needs to be done to turn a string literal
into a matching object. Now turning the string literal "abc" into a matching
object became simple and easy to understand:
REGEX("abc")This macro call expands to the right code parsing the string literal and
building the matching object. It can be used to initialise sregex objects. For
example the original Boost.Xpressive example looks like the following using it:
int main()
{
using boost::xpressive::sregex;
using boost::xpressive::smatch;
sregex re = REGEX("ab*c");
smatch what;
if (regex_match("abbbbbbbc", what, re))
{
std::cout << "It works" << std::endl;
}
else
{
std::cout << "Something is wrong here..." << std::endl;
}
}This code contains the regular expression in its common form, thus anyone can easily read and update it, but this regular expression is verified and processed at compile-time.
Look at lab6.cpp and lab6.hpp. You will need to build all these things
yourself. One your code passes all the validation, congratulations, you have
completed this tutorial.
This tutorial intended to show how you can use Metaparse to embded DSLs into C++. The embedding is based only on standard C++ features which makes your DSL extremely portable. As an example during the tutorial, we have implemented a DSL for regular expressions that is readable, safe and produces efficient code at the same time.
You can find the solutions of the exercises in the solution directory of the
source code you have downloaded.
I would like to thank Eric Niebler for reviewing this tutorial and giving valuable feedback.
The tutorial is published under the Boost Software License.