Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller, and performs within 1% WER on out-of-distribution evaluation sets.
| Model | Link |
|---|---|
distil-whisper-large |
To be published on November 2nd |
distil-whisper-medium |
To be published on November 2nd |
The Distil-Whisper checkpoints will be released on November 2nd with a direct 🤗 Transformers integration. Instructions for running inference will be provided here:
from transformers import WhisperForConditionalGeneration
...Distil-Whisper is designed to be a drop-in replacement for Whisper on English ASR. Here are 4 reasons for making the switch to Distil-Whisper:
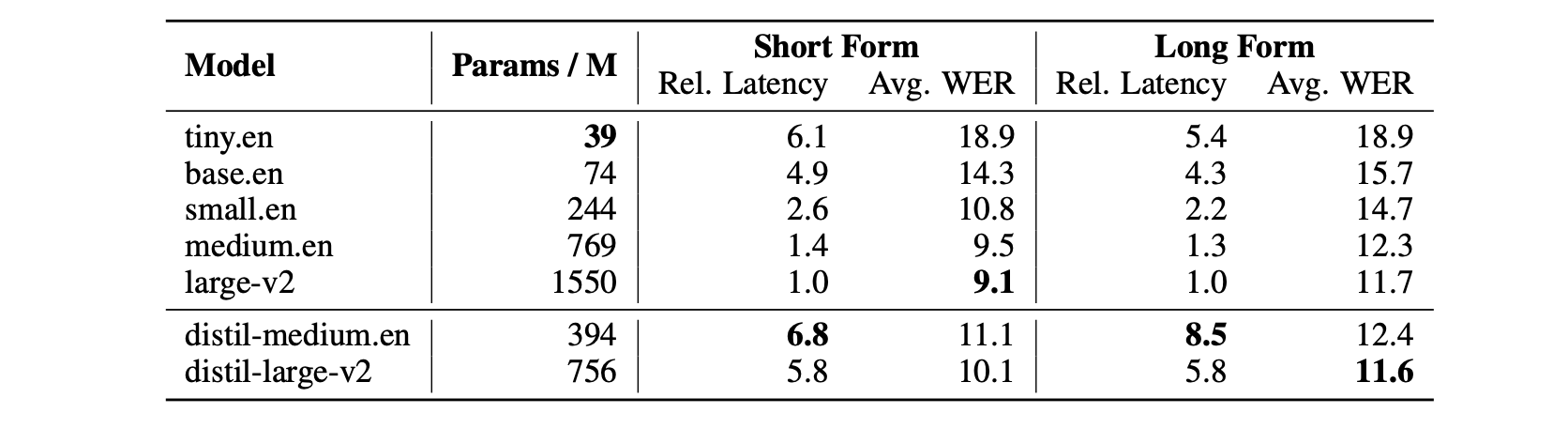
- Faster inference: 6 times faster inference speed, while performing to within 1% WER of Whisper on out-of-distribution audio:
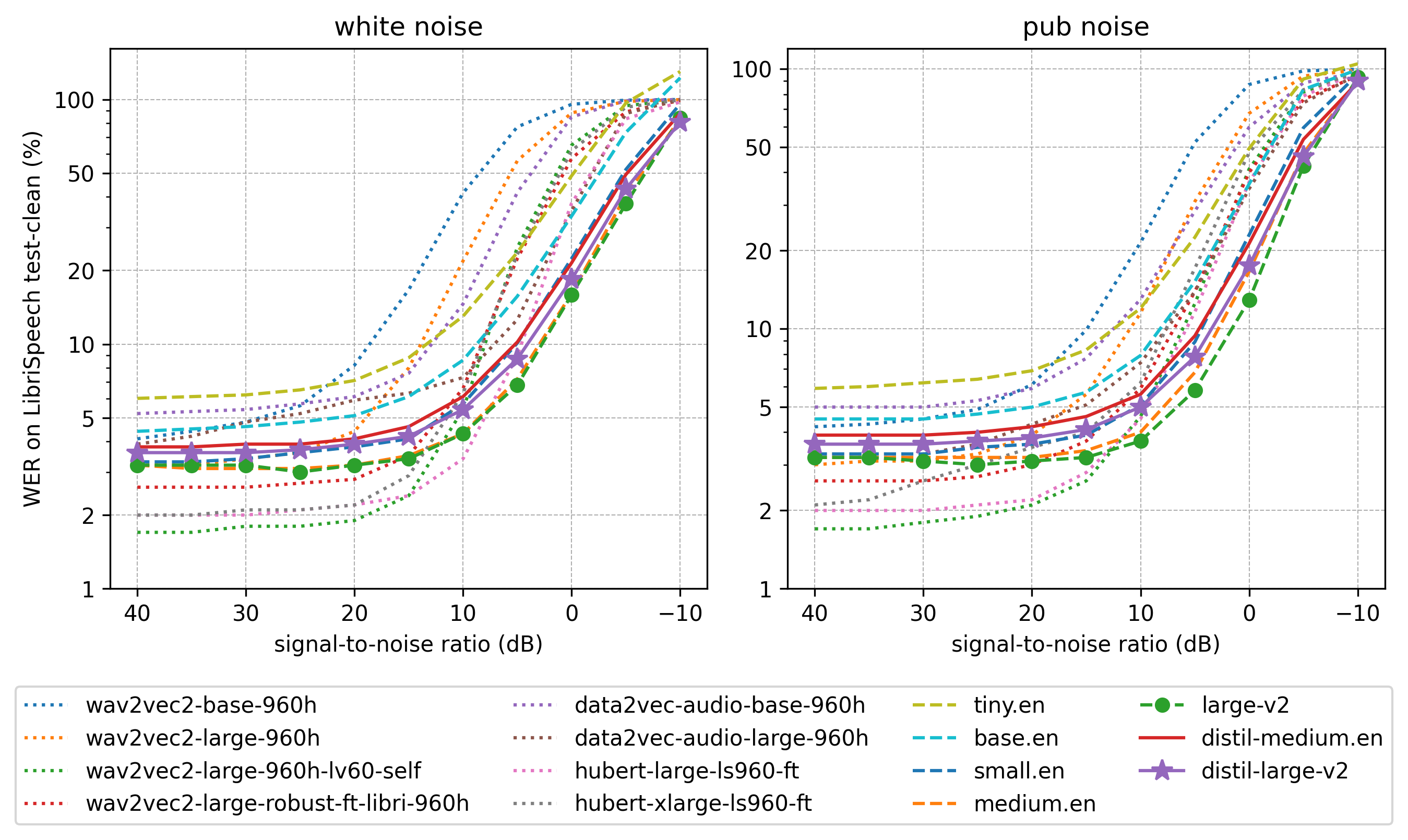
- Robustness to noise: demonstrated by strong WER performance at low signal-to-noise ratios:
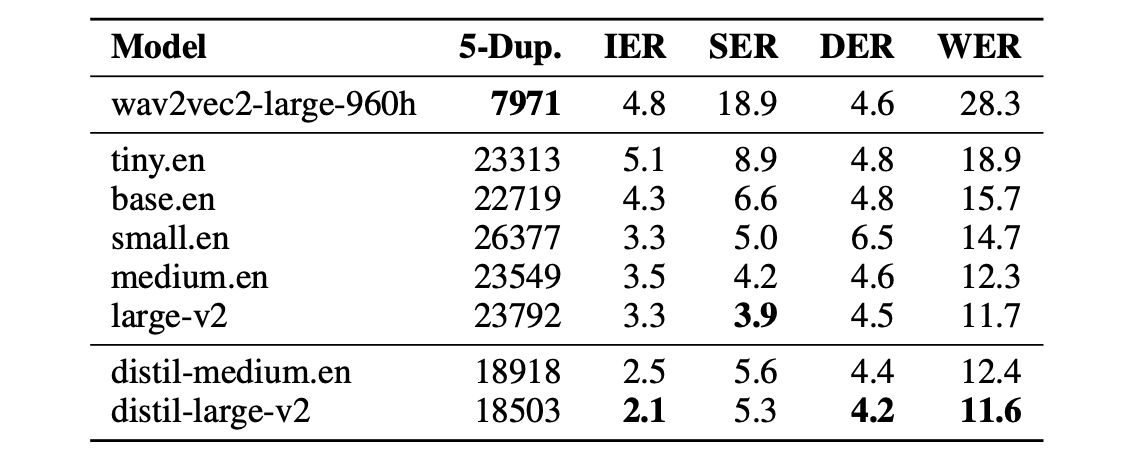
- Robustness to hallucinations: quantified by 1.3 times fewer repeated 5-gram word duplicates (5-Dup.) and 2.1% lower insertion error rate (IER) than Whisper:
- Designed for speculative decoding: Distil-Whisper can be used as an assistant model to Whisper, giving 2 times faster inference speed while mathematically ensuring the same outputs as the Whisper model.
To distill Whisper, we copy the entire encoder module and freeze it during training. We copy only two decoder layers, which are initialised from the first and last decoder layers from Whisper. All other decoder layers from Whisper are discarded.
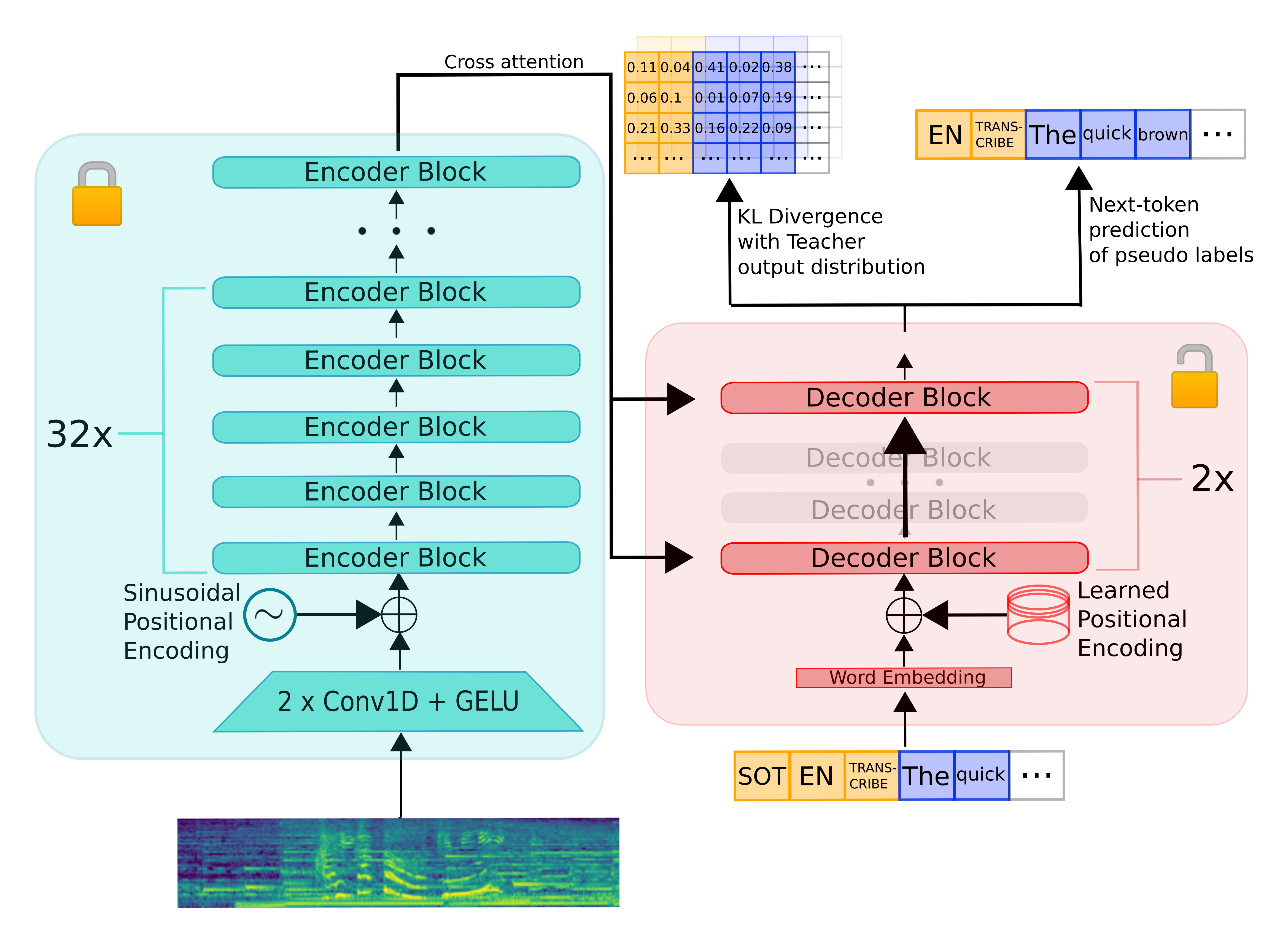
Distil-Whisper is trained on a knowledge distillation objective. Specifically, it is trained to minimise the KL divergence between the distilled model and the Whisper model, as well as the cross-entropy loss on pseudo-labelled audio data.
We train Distil-Whisper on a total of 22k hours of pseudo-labelled audio data, spanning 10 domains with over 18k speakers:
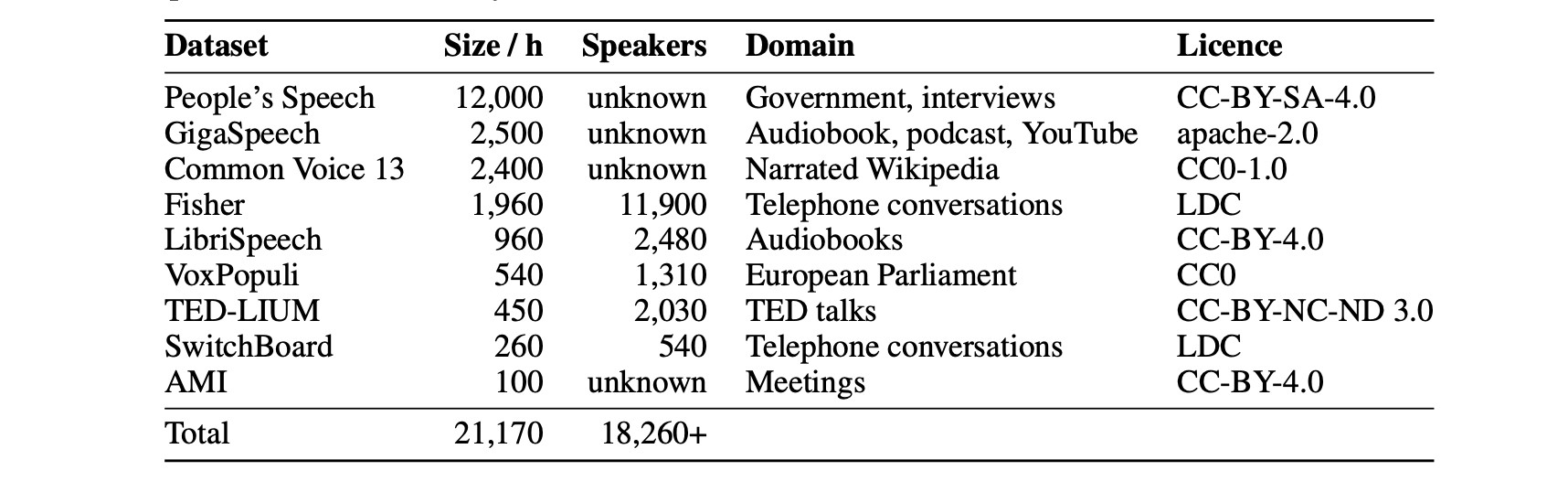
This diverse audio dataset is paramount to ensuring robustness of Distil-Whisper to different datasets and domains.
In addition, we use a WER filter to discard pseudo-labels where Whisper mis-transcribes or hallucinates. This greatly improves WER performance of the downstream distilled model.
For full details on the distillation set-up and evaluation results, refer to the Distil-Whisper paper.