How do we measure the degradation of a machine learning process? Why does the performance of our predictive models decrease? Maybe it is that a data source has changed (one or more variables) or maybe what changes is the relationship of these variables with the target we want to predict. pydrift tries to facilitate this task to the data scientist, performing this kind of checks and somehow measuring that degradation.
With pip:
pip install pydrift
With conda:
conda install -c conda-forge pydrift
With poetry
poetry add pydrift
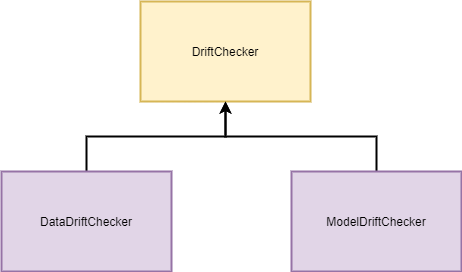
This is intended to be user-friendly. pydrift is divided into DataDriftChecker and ModelDriftChecker:
- DataDriftChecker: searches for drift in the variables, check if their distributions have changed
- ModelDriftChecker: searches for drift in the relationship of the variables with the target, checks that the model behaves the same way for both data sets
Both can use a discriminative model (defined by parent class DriftChecker), where the target would be binary in belonging to one of the two sets, 1 if it is the left one and 0 on the contrary. If the model is not able to differentiate given the two sets, there is no difference!
It also exists InterpretableDrift and DriftCheckerEstimator:
- InterpretableDrift: manages all of the stuff related to interpretability of drifting. It can show us the features distribution or the most important features when we are training a discriminative model or our predictive one
- DriftCheckerEstimator: allows
pydriftto be used as a sklearn estimator, it works lonely or in a pipeline, like any sklearn estimator
You can take a look to the notebooks folder where you can find one example for generic DriftChecker, one for DataDriftChecker and other one for ModelDriftChecker.
Because pydrift uses plotly and GitHub performs a static render of the notebooks figures do not show correctly. For a rich view of the notebook, you can visit nbviewer and paste the link to the notebook you want to show, for example if you want to render 1-Titanic-Drift-Demo.ipynb you have to paste https://github.com/sergiocalde94/pydrift/blob/master/notebooks/1-Titanic-Drift-Demo.ipynb into nbviewer.
For more info check the docs available here
More demos and code improvements will coming, if you want to contribute you can contact me (sergiocalde94@gmail.com), in the future I will upload a file to explain how this would work.