The goal of this project is to predict sentences through lip reading, utilizing the GRID dataset.
demo.mp4
-
Given that our dataset comprises stationary, front-facing camera videos with minimal movement, we opted for manual frame cropping.
-
We also verified our results with a pretrained dlib model can dynamically crop the mouth region and observed similar results.
-
Example of cropped frames:


-
The model architecture is inspired from LipNet, focusing on sentence prediction via lip reading.
-
To train the model, run the following command in your terminal:
python lipreading.py
-
After training, the model is saved in
/resultsascheckpoint.pth, and convergence plots are saved in the root folder asconvergence_plots.png.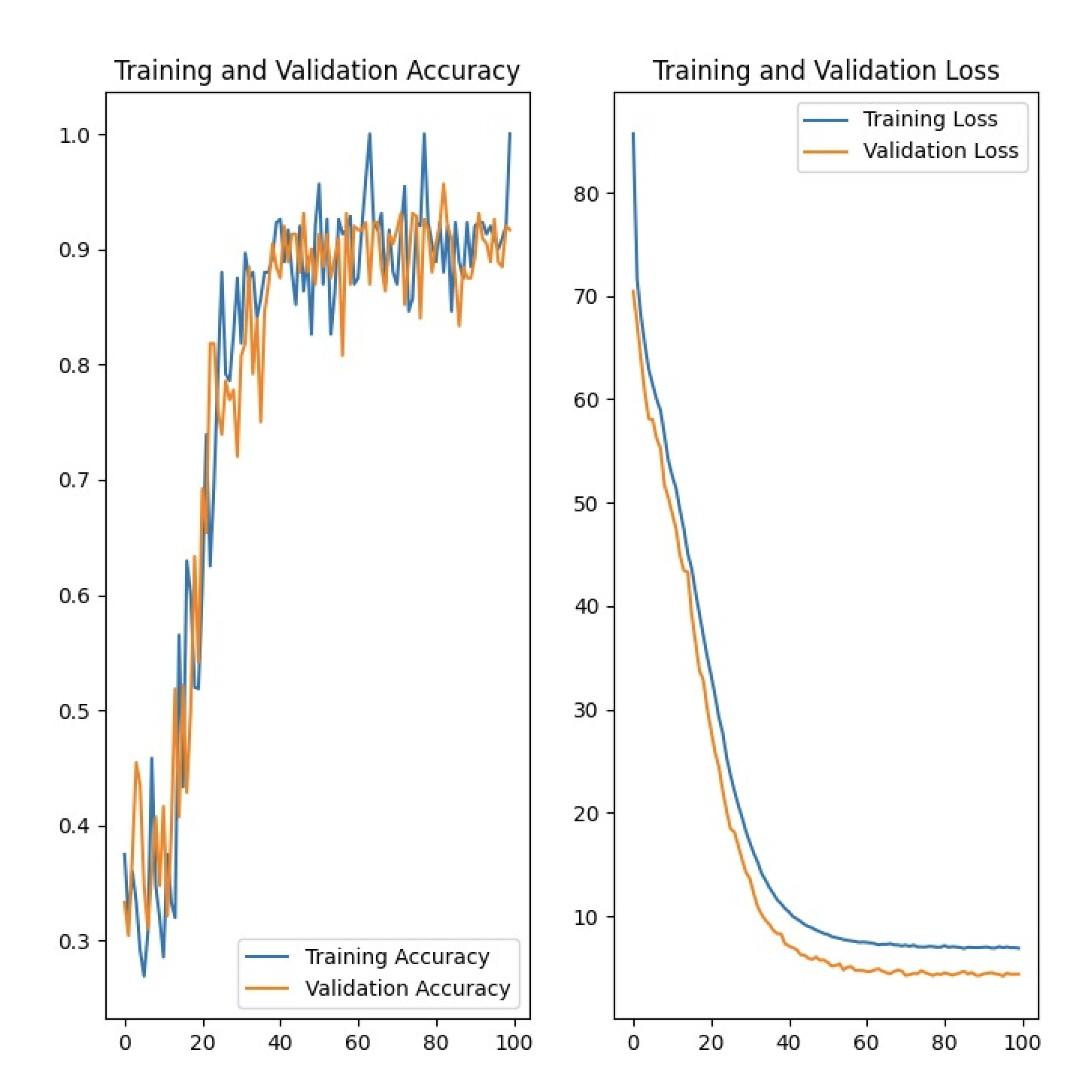

-
Predictions on five videos:

