This tutorial aims to teach you how to use existing resources like tesseract, cv2, etc. to create a simple yet powerful OCR (optical character recognition system). We have added a new feature to the traditional OCR, i.e it can identify URLs in an image and also opens them in the web browser.
Tutorial written by Saksham Kapoor. Get in touch here.

- Make sure you have python installed on your computer.
- Knowledge of basic python syntax.
Step 1 - Install pytesseract OCR for windows from here.
- During the installation, use the default destination path.
- Copy the destination path as we'll need it soon.
- After the installation is complete, search for environment variables in the windows search bar.
- Click on Edit the environment variables search result.
- Click on Environment Variables, then under the heading System Variables click Path and then click Edit.
- Click New, then paste the path that we just copied.
-
Open windows powershell, type
tesseract
-
If you see something like this, it was successfully installed
Usage: C:\Program Files\Tesseract-OCR\tesseract.exe --help | --help-extra | --version C:\Program Files\Tesseract-OCR\tesseract.exe --list-langs C:\Program Files\Tesseract-OCR\tesseract.exe imagename outputbase [options...] [configfile...] OCR options: -l LANG[+LANG] Specify language(s) used for OCR. NOTE: These options must occur before any configfile. Single options: --help Show this help message. --help-extra Show extra help for advanced users. --version Show version information. --list-langs List available languages for tesseract engine. -
However, if not, please read the instructions carefully and try again.
- Download sample.jpg from this repo (You can use any image).
- Put it in a new folder.
- Open terminal and cd to the new folder
> cd Desktop/NewFolderName/ - In the terminal type write the following command -
> tesseract sample.jpg output pdf - Now check the folder, you will have a new pdf named output.pdf generated from the sample.jpg
- pillow (helps us to deal with images in python)
- pytesseract (creates a link between python and the tesseract OCR engine that we just installed)
- opencv-python (OpenCV - Open Source Computer Vision Library, is an open source computer vision and machine learning software library. We'll use it to read images.)
pip install pillow
pip install pytesseract
pip install opencv-pythonI have named it main.py
from PIL import Image
import pytesseract
import cv2
import re
import os
import webbrowserUsage :
- re : Used to define a regular expression (regex) which will help us to search a url in the image text.
- webbrowser : Used to open pages on the browser.
- os : We will use this is generate a unique id and also manage files in the directory.
- cv2 : We will use this to read and convert the image to gray scale.
# Set your tesseract.exe path here
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# Specify Path/Name of image you want to read
img_name = "sample.jpg" # Reading the image
img = cv2.imread(img_name)
# Converting the image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Create temporary image which will be fed to the tesseract engine
# file name has to be unique, therefore we have used OS
temp_img = "{}.jpg".format(os.getpid())
# Writing the image to the temporary image file
cv2.imwrite(temp_img, gray)
# Getting text from image
text = pytesseract.image_to_string(Image.open(temp_img))
# Finding the url using
urls = re.findall('(?:(?:https?|ftp):\/\/)?[\w/\-?=%.]+\.[\w/\-?=%.]+', text)
# Deleting the temporary file
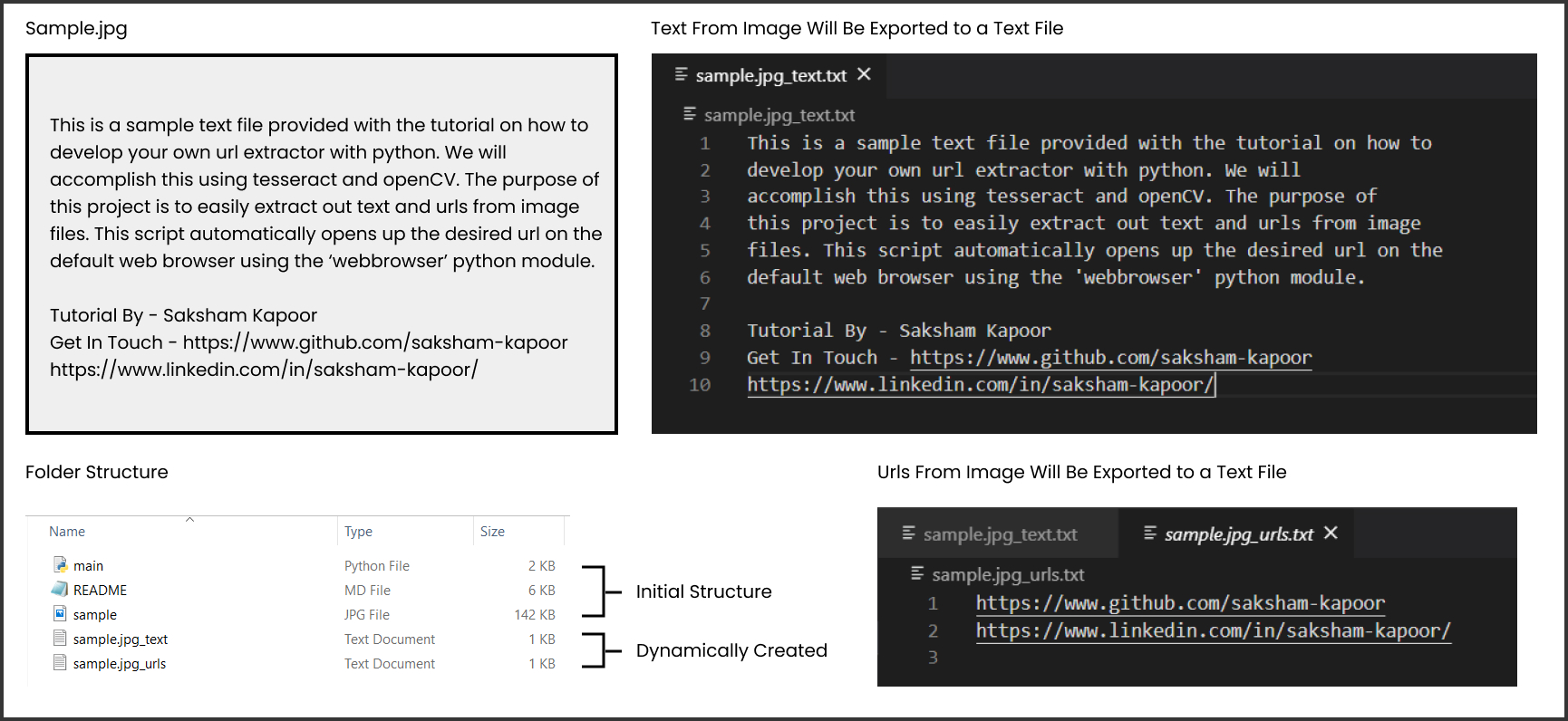
os.remove(temp_img) # Export text from image to a text file (Optional)
text_file = open(f"{img_name}_text.txt", "w")
text_file.write(text)
text_file.close()
# Export urls from image to a text file (Optional)
urls_file = open(f"{img_name}_urls.txt", "w")
for url in urls:
urls_file.write(url + "\n") # Open Urls in the default browser
# If Multiple urls, it will open them in seperate tabs
flag = 0
for url in urls:
if flag == 0:
webbrowser.open(url)
else:
webbrowser.open_new_tab(url)
flag = flag + 1A sample photo has been provided in this repo. Download/Clone the repo and run python script. It should just as expected.
- Open Script in any text editor, change img_name to the image of your choice.
- Open Windows Powershell.
- Change directory to the folder containing image and the script.
cd ./Desktop/FolderName- Run script
python main.pyYou can reach out to me at sakshamkapoor1729@gmail.com