This repository implements our ECCV2022 paper InvPT:
Hanrong Ye and Dan Xu, Inverted Pyramid Multi-task Transformer for Dense Scene Understanding. The Hong Kong University of Science and Technology (HKUST)
- InvPT proposes a novel end-to-end Inverted Pyramid multi-task Transformer to perform simultaneous modeling of spatial positions and multiple tasks in a unified framework.
- InvPT presents an efficient UP-Transformer block to learn multi-task feature interaction at gradually increased resolutions, which also incorporates effective self-attention message passing and multi-scale feature aggregation to produce task-specific prediction at a high resolution.
- InvPT achieves superior performance on NYUD-v2 and PASCAL-Context datasets respectively, and significantly outperforms previous state-of-the-arts.

InvPT enables jointly learning and inference of global spatial interaction and simultaneous all-task interaction, which is critically important for multi-task dense prediction.

Framework overview of the proposed Inverted Pyramid Multi-task Transformer (InvPT) for dense scene understanding.
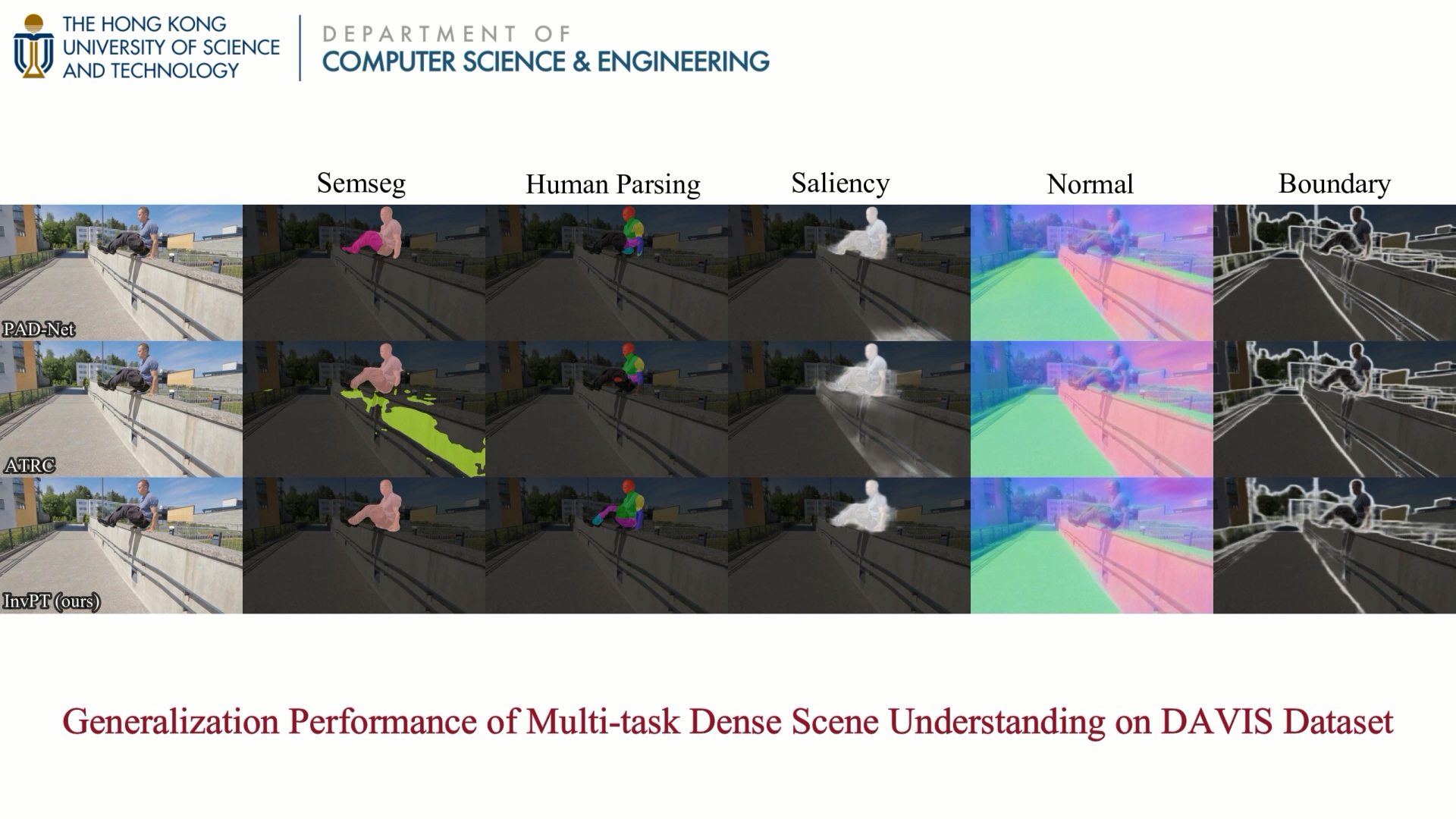 To qualitatively demonstrate the powerful performance and generalization ability of our multi-task model InvPT, we further examine its multi-task prediction performance for dense scene understanding in the new scenes. Specifically, we train InvPT on PASCAL-Context dataset (with 4,998 training images) and generate prediction results of the video frames in DAVIS dataset without any fine-tuning. InvPT yields good performance on the new dataset with distinct data distribution.
Watch the demo here!
To qualitatively demonstrate the powerful performance and generalization ability of our multi-task model InvPT, we further examine its multi-task prediction performance for dense scene understanding in the new scenes. Specifically, we train InvPT on PASCAL-Context dataset (with 4,998 training images) and generate prediction results of the video frames in DAVIS dataset without any fine-tuning. InvPT yields good performance on the new dataset with distinct data distribution.
Watch the demo here!
🚩 Updates
- ✅ July 18, 2022: Update with InvPT models trained on PASCAL-Context and NYUD-v2 dataset!
For easier usage, we re-implement InvPT with a clean training framework, and here is a successful path to deploy the recommended environment:
conda create -n invpt python=3.7
conda activate invpt
pip install tqdm Pillow easydict pyyaml imageio scikit-image tensorboard
pip install opencv-python==4.5.4.60 setuptools==59.5.0
# An example of installing pytorch-1.10.0 with CUDA 11.1
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install timm==0.5.4 einops==0.4.1We use the same data (PASCAL-Context and NYUD-v2) as ATRC. You can download the data by:
wget https://data.vision.ee.ethz.ch/brdavid/atrc/NYUDv2.tar.gz
wget https://data.vision.ee.ethz.ch/brdavid/atrc/PASCALContext.tar.gzAnd then extract the datasets by:
tar xfvz NYUDv2.tar.gz
tar xfvz PASCALContext.tar.gzYou need to specify the dataset directory as db_root variable in configs/mypath.py.
The config files are defined in ./configs, the output directory is also defined in your config file.
As an example, we provide the training script of the best performing model of InvPT with Vit-L backbone. To start training, you simply need to run:
bash run.sh # for training on PASCAL-Context dataset. or
bash run_nyud.sh # for training on NYUD-v2 dataset.after specifcifing your devices and config in run.sh.
This framework supports DDP for multi-gpu training.
All models are defined in models/ so it should be easy to deploy your own model in this framework.
The training script itself includes evaluation.
For inferring with pre-trained models, you need to change run_mode in run.sh to infer.
We follow previous works and use Matlab-based SEISM project to compute the optimal dataset F-measure scores. The evaluation code will save the boundary detection predictions on the disk.
Specifically, identical to ATRC and ASTMT, we use maxDist=0.0075 for PASCAL-Context and maxDist=0.011 for NYUD-v2. Thresholds for HED (under seism/parameters/HED.txt) are used. read_one_cont_png is used as IO function in SEISM.
To faciliate the community to reproduce our SoTA results, we re-train our best performing models with the training code in this repository and provide the weights for the reserachers.
| Version | Dataset | Download | Segmentation | Human parsing | Saliency | Normals | Boundary |
|---|---|---|---|---|---|---|---|
| InvPT* | PASCAL-Context | google drive, onedrive | 79.91 | 68.54 | 84.38 | 13.90 | 72.90 |
| InvPT (our paper) | PASCAL-Context | - | 79.03 | 67.61 | 84.81 | 14.15 | 73.00 |
| ATRC (ICCV 2021) | PASCAL-Context | - | 67.67 | 62.93 | 82.29 | 14.24 | 72.42 |
| Version | Dataset | Download | Segmentation | Depth | Normals | Boundary |
|---|---|---|---|---|---|---|
| InvPT* | NYUD-v2 | google drive, onedrive | 53.65 | 0.5083 | 18.68 | 77.80 |
| InvPT (our paper) | NYUD-v2 | - | 53.56 | 0.5183 | 19.04 | 78.10 |
| ATRC (ICCV 2021) | NYUD-v2 | - | 46.33 | 0.5363 | 20.18 | 77.94 |
*: reproduced results
Simply set the pre-trained model path in run.sh by adding --trained_model pretrained_model_path.
You also need to change run_mode in run.sh to infer.
BibTex:
@InProceedings{invpt2022,
title={Inverted Pyramid Multi-task Transformer for Dense Scene Understanding},
author={Ye, Hanrong and Xu, Dan},
booktitle={ECCV},
year={2022}
}
Please also consider 🌟 star our project to share with your community if you find this repository helpful!
Please contact Hanrong Ye if any questions.
This repository borrows partial codes from MTI-Net and ATRC.
Creative commons license which allows for personal and research use only.
For commercial useage, please contact the authors.