AWS Cheat Sheet
Table of Content
Storage
Compute
Networking & Content Delivery
Database
Application Integration
Security, Identity & Compliance
AWS Identity & Access Management (AWS IAM)
AWS Resource Access Manager (AWS RAM)
Cryptography & PKI
AWS Ket Management Service (AWS KMS)
Management & Governance
Analytics
Developer Tools
Others
S3
- Object based storage (files)
- Files can be from 0 Bytes & 5 TB
- Bucket web address:
https://s3-<Region name>.amazonaws.com/<bucketname>e.g.https://s3-eu-west-1.amazonaws.com/myuniquename - Bucket name has to be unique across all regions
- Read after write consistency for PUTs of new objects
- Eventual consistency for overwrite PUTs and DELETEs
- Designed for -
- 99.99% availability for S3 Standard, Glacier, Glacier Deep Archive
- 99.9% for S3 - IA, Intelligent Tiering
- 99.5% for S3 One Zone - IA
- Amazon guarantees availability (SLA) -
- 99.9% for S3 Standard, Glacier, Glacier Deep Archive
- 99% for S3 - IA, S3 One Zone - IA, Intelligent Tiering
- Amazon guarantees durability of 99.999999999% (11 * 9's) for all storage classes
- Replicated to >= 3 AZ (except S3 One Zone IA)
- S3 Standard - Frequently accessed
- S3 Infrequently Accessed (IA) - Provides rapid access when needed
- S3 Infrequently Accessed (IA) - Less storage cost but has data retrieval cost
- S3 One Zone IA - Data is stored in a single AZ + Retrieval charge
- S3 Intelligent Tiering - ML based - moves objects to different storage classes based on its learning about usage of the objects
- S3 Glacier - Archive + Retrieval time configurable from minutes to hours + Retrieval charge (Separate service integrated with S3)
- S3 Glacier Deep Archive - Retrieval time of 12 hrs + Retrieval charge
- S3 Reduced Redundacy - Deprecated. Sustains loss of data in a single facility
- Minimum storage period
- Standard - NA
- Intelligent Tiering - 30 days
- Standard IA - 30 days
- One Zone IA - 30 days
- Glacier - 90 days
- Glacier Deep Archive - 180 days
- Charged based on
- Storage
- No. of Requests
- Storage Management (Tiers)
- Data Transfer
- Transfer Acceleration
- Cross Region Replication
- Cross Region Replication for High Availability or Disaster Recovery
- Cross Region Replication requires versioning to be enabled in both source and destination
- Cross Region Replication is not going to replicate
- File versions created before enabling cross region replication
- Delete marker
- Version deletions
- Cross Region Replication is asynchronous
- Cross Region Replication can replicate to buckets in different account
- Transfer Acceleration for reduced upload time
- Transfer Acceleration takes advantage of CloudFront's globally distributed edge locations and then routes data to the S3 bucket through Amazon's internal backbone network
- The bucket access logs can be stored in another bucket which must be owned by the same AWS account in the same region. For user information CloudTrail Data Events need to be configured
- Enabling logging on a bucket from the management console also updates the ACL on the target bucket to grant write permission to the Log Delivery group
- Encryption at Rest -
- SSE-S3 (Amazon manages key)
- SSE-KMS (Amazon + User manages keys)
- SSE-C (User manages keys)
- Client Side Encryption (User manages keys and encrypt objects)
- SSE-S3
- Server side encryption
- Key managed by S3
- AES 256 in GCM mode
- Must set header -
"x-amz-server-side-encryption":"AES256"
- SSE-KMS
- Server side encryption
- Key managed by KMS
- More control on rotation of key
- Audit trail on how the key is used
- Must set header -
"x-amz-server-side-encryption":"aws:kms" - Prefer SSE-KMS over SSE-S3 to comply with PCI-DSS, HIPAA/HITECH, and FedRAMP industry requirements
- SSE-C
- Server side encryption
- Key managed by customer outside AWS
- HTTPS is a must
- Key to be supplied in HTTP header of every request
- Client Side Encryption
- Key managed by customer outside AWS
- Clients encrypt / decrypt data
- When encryption is enabled on an existing file, a new version will be created (provided versioning is enabled)
- Prefer default encryption settings over S3 bucket policies to encrypt objects at rest
- S3 Bucket Policy can be used to enforce upload of only encrypted objects. The policy will deny any PUT request that does not have the appropriate header
x-amz-server-side-encryption - S3 Bucket Policy can be used to provide public read access to all files in the bucket instead of providing public access to each individual file
- S3 evaluates and applies bucket policies before applying bucket encryption settings. Even if bucket encryption settings is enabled, PUT requests without encryption information will be rejected if there are bucket policies to reject such PUT requests
- With SSE-KMS enabled, the KMS limits might need to be increased to avoid throttling of a lot of small uploads
- Versioning, once enabled, cannot be disabled. It can only be suspended
- Versioning is enabled at the bucket level
- If versioning is enabled, S3 can be configured to require multifactor authentication for
- permanently deleting an object version
- suspend versioning on bucket
- Only root account can enable MFA Delete using CLI
- In a bucket with versioning enabled, even if the file is deleted, the bucket cannot be deleted using AWS CLI until all the versions are deleted
- When each individual file is given public access separately, uploading a new version of an existing file doesn't automatically give public access to the latest version (unless an S3 bucket policy exists to give public access)
- Lifecycle management rules (movement to different storage type and expiration) can be set for current version and previous versions separately
- Lifecycle management rules can be used to delete incomplete multipart uploads after a configurable no. of days
- Files are stored as key-value pair. Key is the file name with the entire path and value is the file content as a sequence of bytes
- More than 5 GB files must be uploaded using multipart upload
- Files larger than 100 MB should be uploaded using multipart upload
- Multipart upload advantages -
- Retry is faster
- Run in parallel to improve performance and utilize network bandwidth
- S3 static website URL:
<bucket-name>.s3-website-<aws-region>.amazonaws.comor<bucket-name>.s3-website.<aws-region>.amazonaws.com - Pre-signed URL allows users to get temporary access to buckets and objects
- S3 Inventory allows producing reports about S3 objects daily or weekly in a different S3 bucket
- S3 Inventory reports format can be specified and the data can be queried using Athena
- Storage class needs to be specified during object upload
- S3 Analytics, when enabled, generates reports in a different S3 bucket to give insights about the object usage and this can be used to recommend when the object should be moved from one storage class to another
- To host a static website, the S3 bucket must have the same name as the domain (
example.com) or subdomain (www.example.com).www.example.combucket can redirect toexample.combucket - S3 notification feature enables the user to receive notifications when certain events happen in a bucket. S3 supports following destinations
- Amazon SNS
- Amazon SQS
- AWS Lambda
- Supports at least 3,500 requests per second to add data and 5,500 requests per second to retrieve
- Amazon S3 Object Lock blocks deletion of an object for the duration of a specified retention period (WORM)
- Object Lock mode - Governance mode (allows deletion by user with appropriate IAM permissions), Compliance mode (even root account cannot delet)
- Object Lock - Legal Hold creates Object Lock for an indefinite period until explicitly removed
- Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption
- Objects uploaded or transitioned to S3 Intelligent-Tiering are automatically stored in the frequent access tier. S3 Intelligent-Tiering works by monitoring access patterns and then moving the objects that have not been accessed in 30 consecutive days to the infrequent access tier. If the objects are accessed later, S3 Intelligent-Tiering moves the object back to the frequent access tier
- Amazon S3 supports the following lifecycle transitions between storage classes using a lifecycle configuration:
- You can transition from the STANDARD storage class to any other storage class.
- You can transition from any storage class to the GLACIER or DEEP_ARCHIVE storage classes.
- You can transition from the STANDARD_IA storage class to the INTELLIGENT_TIERING or ONEZONE_IA storage classes.
- You can transition from the INTELLIGENT_TIERING storage class to the ONEZONE_IA storage class.
- You can transition from the GLACIER storage class to the DEEP_ARCHIVE storage class.
- The following lifecycle transitions are not supported:
- You can't transition from any storage class to the STANDARD storage class.
- You can't transition from any storage class to the REDUCED_REDUNDANCY storage class.
- You can't transition from the INTELLIGENT_TIERING storage class to the STANDARD_IA storage class.
- You can't transition from the ONEZONE_IA storage class to the STANDARD_IA or INTELLIGENT_TIERING storage classes.
- You can transition from the GLACIER storage class to the DEEP_ARCHIVE storage class only.
- You can't transition from the DEEP_ARCHIVE storage class to any other storage class.
- Other restrictions -
- From the STANDARD storage classes to STANDARD_IA or ONEZONE_IA - Objects must be stored at least 30 days in the current storage class
- From the STANDARD_IA storage class to ONEZONE_IA - Objects must be stored at least 30 days in the STANDARD_IA storage class
- Glacier Deep Archive retrieval options:
- Standard - default tier and lets you access any of your archived objects within 12 hours
- Bulk - lets you retrieve large amounts, even petabytes of data inexpensively and typically completes within 48 hours
- S3 Query in-place options -
- S3 Select - Simple query
- Amazon Athena - complex joins, window functions
- Amazon Redshift Spectrum - exabytes of unstructured data
- S3 Same Region Replication (SRR)
- S3 Batch Operations - Operations across multiple objects
- Access logs are not automatically encrypted
Glacier
- Archive size from 1B to 40TB
- Retrieval Options (Different from retrieval policies)
- Expedited (1 - 5 mins retrieval)
- Standard (3 - 5 hours)
- Bulk (5 - 12 hours)
- Object (in S3) == archive (in Glacier)
- Bucket (in S3) == vault (in Glacier)
- Archive files can be upto 40 TB (note more than S3)
- An archive can represent a single file or you may choose to combine several files to be uploaded as a single archive
- Each vault has ONE vault policy & ONE lock policy
- Vault Policy - similar to S3 bucket policy - restricts user access
- Lock Policy - immutable - once set cannot be changed
- WORM Policy - write once read many
- Forbid deleting an archive if it is less than 1 year (configurable) = regulatory compliance
- Multifactor authentication on file access
- Files retrieved from Glacier will be stored in Reduced Redundancy Storage or S3 Standard IA class for a specified number of days
- For faster retrieval from Glacier based on Retrieval Options, Capacity Units may need to be purchased
- Amazon S3 Glacier automatically encrypts data at rest using Advanced Encryption Standard (AES) 256-bit symmetric keys
- Glacier range retrieval (byte range) is charged as per the volume of data retrieved
- In a single Glacier upload, an archive of maximum 4GB (note 1GB less than S3) size can be uploaded
- Any Glacier upload above 100 MB should use multipart upload (note same as S3)
- A Glacier vault can be deleted only when all its content archives are deleted
- Glacier allows the user or application to be notified through SNS when the requested data becomes available
- Bucket access policy (for S3) or Vault access policy (for Glacier) are resource based policies (directly attached to a particular resource - vault/bucket in this case), whereas IAM policies are user based policies
- One Vault access policy can be attached to each Vault
- One Glacier retrieval policy per region
- S3 Glacier Select -
- Allows to select a subset of rows and colums using SQL without retrieving the entire file
- Joins and subqueries not allowed
- Files can be compressed with GZIP or BZIP2
- Works with file format CSV, JSON, Parquet
- Works with all 3 retrieval options - Expedited, Standard & Bulk
- Glacier inventory (of available objects) is updated every 24 hours - no real time data
- The archives cannot be uploaded from the S3 Glacier management console directly
CloudFront
- Content Delivery Network (CDN) - reduced latency and reduced load on server
- Reasons for good performance -
- Cache content at edge location POP (Point of Presence)
- Regional edge caches with larger caches than POP and holding less popular contents between POP and origin server
- Data transfer over Amazon's backbone network between the origin server and the edge location
- Persistent connections with the origin server
- Default caching behavior -
- period - 24 hours
- Don't cache based on caching headers
- You can use the Cache-Control and Expires headers to control how long objects stay in the cache. Settings for Minimum TTL, Default TTL, and Maximum TTL also affect cache duration
- After a file expires in cache, subsequent edge location requests are forwarded to the origin server. The response from the origin -
- 304 status code (Not Modified), if the cache has the latest version
- 200 status code (OK) and the latest version of the file, if the cache doesn't have the latest version
- By default, CloudFront doesn't automatically compress contents
- To access the contents from own domain, say www.example.com
- Add a CNAME in CloudFront for www.example.com
- Add a CNAME in DNS to route traffic to the CloudFront for a query against www.example.com
- Choose a certificate to use that covers the alternate domain name. The list of certificates can include any of the following:
- Certificates provided by AWS Certificate Manager (ACM)
- Certificates that you purchased from a third-party certificate authority and uploaded to ACM
- Certificates that you purchased from a third-party certificate authority and uploaded to the IAM certificate store
- Origin server could be S3, EC2, ELB or any external server
- A distribution can hanve a maximum 10 origin servers (soft limit)
- Video content -
- HTTP / HTTPS
- Apple HTTP Live Streaming (HLS)
- Microsoft Smooth Streaming
- RTMP
- Adobe Flash multimedia content
- HTTP / HTTPS
- Origin Access Identity (OAI) is an user used by CloudFront to access the S3 files
- S3 bucket policy gives access to OAI and thus preventing users from directly accessing the S3 files bypassing the Cloudfront
- CloudFront accesslogs can be stored in an S3 bucket - contains detailed information about every user request that CloudFront receives
- Supports SNI (Server Name Indication - a TLS extension). This allows CloudFront (also ELB) distributions to support multiple TLS certificates
- SNI enables to serve multiple websites with different domain and certificates from the same IP and port. The webserver (e.g. Apache web server) can be configured to have separate document root for each domain (certificate)
- Invalidation requests to remove something from the cache is chargeable - removes both from regional edge cache and POP
- Avoid invalidation request charges and unpredictable caching behavior using version numbers in file names or directory names for changes to take effect immediately (Only invalidation of index.html migh be required)
- An invalidation request path that includes the * wildcard counts as one path even if it causes CloudFront to invalidate thousands of files
- CloudFront supports Field Level Encryption, so that the sensitive data can only be decrypted and viewed by a few specific components or services that have access to the private key
- To use Field Level Ecryption, the specific fields and encryption public key need to be configured in CloudFront
- CloudFront uses algorithm RSA/ECB/OAEPWithSHA-256AndMGF1Padding for Field Level Encryption
- Use signed URLs for the following cases:
- RTMP distribution. Signed cookies aren't supported for RTMP distributions
- Restrict access to individual files, for example, an installation download for your application
- Users are using a client (for example, a custom HTTP client) that doesn't support cookies
- Use signed cookies for the following cases:
- Provide access to multiple restricted files, for example, all of the files for a video in HLS format or all of the files in the subscribers' area of a website
- You don't want to change your current URLs
- Charges are applicable for -
- Serving contents from edge locations
- Transfering data to your origin, which includes DELETE, OPTIONS, PATCH, POST, and PUT requests
- HTTPS requests
- Field level encryption
- Price class - collection fo edge locations for the purpose of controlling cost
- Contents are served only from the edge locations of the selected price class
- Default price class includes all edge locations including the expensive ones
- If S3 is used as an origin server, the bucket name should be in all lowercase and cannot contain space
- For a given distribution, multiple origins can be configured including both S3 and HTTP servers (EC2 / external servers)
- The default cache behavior will cause CloudFront to get objects from one of the origins only. Hence a separate cache behavior needs to be configured for each origin specifying which URL path will be routed to which origin
- Cache behavior - CloudFront does not consider query strings or cookies when evaluating the path pattern
- Cache behavior -- CloudFront caches responses to GET and HEAD requests and, optionally, OPTIONS requests. CloudFront does not cache responses to requests that use the other methods
- GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE: You can use CloudFront to get, add, update, and delete objects, and to get object headers. In addition, you can perform other POST operations such as submitting data from a web form
- Cache behavior - Cache Based on Selected Request Headers
- None (improves caching) – CloudFront doesn't cache your objects based on header values
- Whitelist – CloudFront caches your objects based only on the values of the specified headers. Use Whitelist Headers to choose the headers that you want CloudFront to base caching on
- All – CloudFront doesn't cache the objects that are associated with this cache behavior
- Cache behavior - CloudFront can cache different versions of your content based on the values of query string parameters. Options are:
- None (Improves Caching) - origin returns the same version of an object regardless of the values of query string parameters
- Forward all, cache based on whitelist - if your origin server returns different versions of your objects based on one or more query string parameters. Then specify the parameters that you want CloudFront to use as a basis for caching
- Forward all, cache based on all - if your origin server returns different versions of your objects for all query string parameters
- Supports specifying custom error page based on HTTP response code
- Supports websocket
- You cannot invalidate objects that are served by an RTMP distribution
- Using CloudFront can be more cost effective if your users access your objects frequently because, at higher usage, the price for CloudFront data transfer is lower than the price for Amazon S3 data transfer
- If distribution is configured to compress files, CloudFront determines whether the file is compressible:
- The file type must be one that CloudFront compresses
- The file size must be between 1,000 and 10,000,000 bytes
- The response must include a Content-Length header so CloudFront can determine whether the size of the file is in the range that CloudFront compresses
- The response must not include a Content-Encoding header
- If you configure CloudFront to compress content, CloudFront removes the ETag response header from the files that it compresses
- ETag header helps to determine whether the edge cache has the latest file. However, after compression the two versions are no longer identical. As a result, when a compressed file expires and CloudFront forwards another request to your origin, the origin always returns the file to CloudFront instead of an HTTP status code 304 (Not Modified)
- When configured for compression, CloudFront compresses files in each edge location. it doesn't compress files when
- the file is already in edge locations
- the file is expired but origin returns HTTP status code 304
- You might not find the imported certificate or ACM certificate if - (Note - IAM certificate store supports ECDSA):
- The imported certificate is using an algorithm other than 1024-bit RSA or 2048-bit RSA.
- The ACM certificate wasn't requested in the same AWS Region as the load balancer or CloudFront distribution
- To ensure that users can access content only through CloudFront, change the following settings in the CloudFront distributions:
- Origin Custom Headers - Configure CloudFront to forward custom headers to your origin (headers should be rotated periodically). Origin server to deny requests not containing correct header
- Viewer Protocol Policy - Configure your distribution to require viewers to use HTTPS to access CloudFront
- Origin Protocol Policy - Configure your distribution to require CloudFront to use the same protocol as viewers to forward requests to the origin (This ensures the headers will remain encrypted)
- If you want CloudFront to cache different versions of your objects based on the user device, configure CloudFront to forward the applicable headers to your custom origin:
- CloudFront-Is-Desktop-Viewer
- CloudFront-Is-Mobile-Viewer
- CloudFront-Is-SmartTV-Viewer
- CloudFront-Is-Tablet-Viewer
- To cache different versions of your objects based on the language specified in the request, program your application to include the language in the Accept-Language header, and configure CloudFront to forward the Accept-Language header to your origin
- To cache different versions of your objects based on the country that the request came from, configure CloudFront to forward the CloudFront-Viewer-Country header to your origin
- To cache different versions of your objects based on the protocol of the request, HTTP or HTTPS, configure CloudFront to forward the CloudFront-Forwarded-Proto header to your origin
- Caching based on query parameters and cookies are also possible with the similar options. It is recommended to forward only those cookies or query parameters to the origin server for which the server returns different objects
- To create signed cookies or signed URLs
- identify an AWS account as a trusted signer
- create a CloudFront key pair for the trusted signer
- assign the trusted signer to the distribution or a specific cache behvior
- Web didtributions can add a trusted signer to a specific cache behavior and thus using signed cookie or signed URL for a specific set of files only. However, for RTMP distributions, it has to be for the entire distribution
- For signed URLs CloudFront checks if the URL has expired only at the begining of the download or play. If after the download or streaming starts the URL expires, the download or streaming will continue
- Geo restriction applies to an entire web distribution. If you need to apply one restriction to part of your content and a different restriction (or no restriction) to another part of your content, you must either create separate CloudFront web distributions or use a third-party geolocation service
- You can set up CloudFront with origin failover for scenarios that require high availability. To get started, create an origin group in which you designate a primary origin for CloudFront plus a second origin that CloudFront automatically switches to when the primary origin returns specific HTTP status code failure responses
- Access logs are not automatically encrypted
Snowball
- When to use - if it takes more than a week to transfer data over the network, prefer Snowball
- Snowball Edges have computational capabilities
- Can be Storage Optimized (24 vCPU) or Compute Optimized (52 vCPU) & optional GPU
- Allows processing on the go
- Use cases - Useful for IoT capture, machine learning, data migration, image collation etc.
- An 80 TB Snowball appliance has 72 TB usable capacity
- 100 TB Snowball Edge appliance has 83 TB of usable capacity
Snowmobile
- 100 PB in capacity
- When to use - Better than snowball if data to be transferred is more than 10 PB
Storage Gateway
- Storage Gateway supports hybrid cloud by allowing the on-primise resources access the cloud storage like EBS, S3 etc. through standard protocols
- By default, Storage Gateway uses Amazon S3-Managed Encryption Keys (SSE-S3) to server-side encrypt all data it stores in Amazon S3
- Storage Gateway types -
- File Gateway
- Volume Gateway
- Tape Gateway
- File Gateway -
- Configured S3 buckets accessible through NFS & SMB protocol
- Bucket access using IAM roles for each File Gateway
- Most recently used data is cached in File Gateway
- Can be mounted on many servers
- Volume Gateway -
- Block storage using iSCSI protocol backed by S3
- EBS snapshots stored S3 buckets
- Cached Volume - Recently used data cached
- Stored Volume - Entire dataset in premise with scheduled backups in S3
- Tape Gateway -
- Backup from on premise tape to S3 Glacier using iSCSI protocol
- VTL - Virtual Tape Library - S3
- VTS - Virtual Tape Shelf - Glacier or Glacier Deep Archive

Athena
- Serverless service (built on Presto)
- Allows to do analytics directly on S3
- Supports data formats CSV, JSON, ORC, Avro, Parquet
- Uses SQL to query the files
- Good for analyzing VPC Flow Logs, ELB Logs etc. at scale by creating a table and linking it with the S3 bucket holding the logs
IAM
- Global service
- Users for individuals
- User Groups for grouping users with similar permission requirements
- Roles are for machines or internal AWS resources. One IAM Role for ONE application
- You can create an identity broker that sits between your corporate users and your AWS resources to manage the authentication and authorization process without needing to recreate all your users as IAM users in AWS. The identity broker application has permissions to access the AWS Security Token Service (STS) to request temporary security credentials
- Login to EC2 operating system can be done using:
- Assymmetric key pair
- Local operating system users
- Active Directory
- Session Manager of AWS Systems Manager
- Two types of policies
- Resource policies - Attached to the individual resources
- Capability policies - Attached to IAM users, groups or roles
- Resource policies and capability policies and are cumulative in nature: An individual user’s effective permissions is the union of a resources policies and the capability permissions granted directly or through group membership. However, the resource policy permissions can be denied explicitly in the capability policy
- IAM policies can be used to restrict access to a specific source IPaddress range, or during specific days and times of the day, as well as based on other conditions
EC2
- Security Groups are for network security
- Security Groups are locked down to a region / VPC combination
- Security Groups can refer to other Security Groups. For e.g. to ensure that a web server in an EC2 instance serves requests only from an ALB, assign a security group to EC2 to open port 80 for traffic from the security group of the ALB
- One security group can be attached to multiple EC2 instances
- Multiple security groups can be assigned to a single EC2 instance
- If connection to application times out, it could be a security group issue. If connection is refused, it's an application issue
- Security Group - All inbound traffic is blocked by default
- Security Group - All outbound traffic is authorized by default
- Security Groups are stateful - if the inbound traffic on a port is allowed, the related outbound traffic is automatically allowed
- Change in security group takes effect immediately
- Security groups cannot blacklist an IP or port. Everything is blocked by default, we need to specifically open ports
- Elastic IP gives a fixed public IP to an EC2 instance across restarts
- One AWS account can have 5 elastic IP (soft limit)
- Prefer load balancer over Elastic IP for high availability
- EC2 User Data script runs once (with root privileges) at the instance first start
- EC2 Launch types -
- On-demand instances - short workload, predictable pricing
- Reserved instances - long workload (>= 1 year) - upto 75% discount
- Convertible reserved instances - long workload with flexible instance types - upto 54% discount
- Scheduled reserved instances - reserved for specific time window
- Spot instances - short workload, cheap, can lose instances, good for batch jobs, big data analytics etc. - upto 90% discount
- Dedicated instances - no other customer will share the hardware, but instances from same AWS account can share hardware, no control on instance placement
- Dedicated hosts - the entire server is reserved, provides more control on instance placement, more visibility into sockets and cores, good for "bring your own licenses (BYOL)", complicated regulatory needs - 3 years period reservation
- Billing by second with a minimum of 60 seconds
- Spot Price - If your Spot instance is terminated or stopped by Amazon EC2 in the first instance hour, you will not be charged for that usage. However, if you terminate the instance yourself, you will be charged to the nearest second. If the Spot instance is terminated or stopped by Amazon EC2 in any subsequent hour, you will be charged for your usage to the nearest second. If you are running on Windows or Red Hat Enterprise Linux (RHEL) and you terminate the instance yourself, you will be charged for an entire hour
- Spot Price - You will pay the price per instance-hour set at the beginning of each instance-hour for the entire hour, billed to the nearest second
- T2/T3 are burstable instances. Spikes are handled using burst credits that are accumulated over time. If burst credits are all consumed, performance will suffer
- M instance types are balanced
- Instance Type
- R - More RAM (use cases - in-memory caches)
- C - More CPU (use cases - compute / databases)
- M - Medium (use cases - general / webapp)
- I - More I/O - instance storage (use cases - databases)
- G - More GPU - (use cases - video rendering / machine learning)
- T2/T3 - burstable instances (up to a capacity / unlimited)
http://169.254.169.254/latest/user-data/gives user data scriptshttp://169.254.169.254/latest/meta-data/gives meta datahttp://169.254.169.254/latest/meta-data/public-ipv4/gives public IPhttp://169.254.169.254/latest/meta-data/local-ipv4/gives local IP- Three types of placement groups
- Clustered Placement Group -
- Grouping of instances within a single AZ, single rack
- Use cases - recommended for applications that need low network latency and high network throughput
- Only certain specific instance types can be launched in this placement group
- cannot span multiple AZ
- Partitioned Placement Group –
- spreads instances across logical partitions
- use cases - large distributed and replicated workloads, such as Hadoop, Cassandra, and Kafka
- each partition within a placement group has its own set of racks. Each rack has its own network and power source
- allows max 7 instances per AZ
- partitions can be distributed across AZ
- provides visibility as to which instance belongs to which partition through metadata
- not supported for Dedicated Hosts
- dedicated Instances can have a maximum of two partitions
- Spread Placement Group -
- instances are placed in distinct hardware
- each intance is placed on distinct racks, with each rack having its own network and power source
- use cases - recommended for applications that have a small number of critical instances that should be kept separate from each other
- can span multiple AZ
- allows max 7 instances per AZ
- not supported for Dedicated Instances or Dedicated Hosts
- Clustered Placement Group -
- The instances within a placement group should be homogeneous
- Placement groups can't be merged
- You can move an existing instance to a placement group, move an instance from one placement group to another, or remove an instance from a placement group. Before you begin, the instance must be in the stopped state
- Instance store backed EC2 instances can only be rebooted and terminated. They cannot be stopped unlike EBS-backed instances
- With instance store, the entire image is downloaded from S3 before booting and hence the boot time is usually around 5 mins
- With EBS-backed instances, only the part needed for booting is first downloaded from the EBS Snapshot and hence the boot time is shorter around 1 min
- EBS-backed instances once stopped, all data in any attached instance store will be deleted
- When an Amazon EBS-backed instance is stopped, you're not charged for instance usage; however, you're still charged for volume storage
- EC2-Classic is the original version of EC2 where the elastic IP would get disassociated when the instance stopped
- With EC2-VPC, the Elastic IP does not get disassociated when stopped
- When EC2 instance is stopped, it may get moved to a different underlying host
- EC2 instance states that are billed
- running
- stopping (only when the instannce is preparing to hibernate - NOT when the instance is being stopped)
- terminated (only for reserved instances only that are still in their contracted term)
- Select Auto-assign Public IP option so that the launched EC2 instance has a public IP from Amazon's public IP pool
- A custom AMI can be created with pre-installed software packages, security patches etc. instead of writing user data scripts, so that the boot time is less during autoscaling
- AMIs are built for a specific region, but can be copied across regions
- AWS AMI Virtualization types -
- Paravirtual (PV)
- Hardware Virtual Machine (HVM) - Amazon recommends
- All AMIs are categorized as either
- backed by Amazon EBS or
- backed by instance store
- AMIs with encrypted volumes cannot be made public. It can be shared with specific accounts along with the KMS CMK
- During the AMI-creation process, Amazon EC2 creates snapshots of your instance's root volume and any other EBS volumes attached to your instance. You're charged for the snapshots until you deregister the AMI and delete the snapshots
- If any volumes attached to the instance are encrypted, the new AMI only launches successfully on instances that support Amazon EBS encryption
- Encrypting during the CopyImage action applies only to Amazon EBS-backed AMIs. Because an instance store-backed AMI does not rely on snapshots, you cannot use copying to change its encryption status
- AWS does not copy launch permissions, user-defined tags, or Amazon S3 bucket permissions from the source AMI to the new AMI
- You can't copy an AMI that was obtained from the AWS Marketplace, regardless of whether you obtained it directly or it was shared with you. Instead, launch an EC2 instance using the AWS Marketplace AMI and then create an AMI from the instance
- If you copy an AMI that has been shared with your account, you are the owner of the target AMI in your account. The owner of the source AMI remains unchanged
- To copy an AMI that was shared with you from another account, the owner of the source AMI must grant you read permissions for the storage that backs the AMI, either the associated EBS snapshot (for an Amazon EBS-backed AMI) or an associated S3 bucket (for an instance store-backed AMI). If the shared AMI has encrypted snapshots, the owner must share the key or keys with you as well
- If you specify encryption parameters while copying an AMI, you can encrypt or re-encrypt its backing snapshots
- To coordinate Availability Zones across accounts, you must use the AZ ID, which is a unique and consistent identifier for an Availability Zone because us-east-1a AZ of one AWS account may not be same as us-east-1b of another AWS account
- When an instance is terminated, Amazon Elastic Compute Cloud (Amazon EC2) uses the value of the DeleteOnTermination attribute for each attached EBS volume to determine whether to preserve or delete the volume when the instance is terminated
- By default, the DeleteOnTermination attribute for the root volume of an instance is set to true, but it is set to false for all other volume types
- Using the console, you can change the DeleteOnTermination attribute when you launch an instance. To change this attribute for a running instance, you must use the command line
- Underlying Hypervisors for EC2 - Xen, Nitro
- You must stop your Amazon EBS–backed instance before you can change its instance type
- While changing instance type, instance store backed instances must be migrated to the new instance
- When you stop and start an instance, be aware of the following:
- We move the instance to new hardware; however, the instance ID does not change.
- If your instance has a public IPv4 address, we release the address and give it a new public IPv4 address
- The instance retains its private IPv4 addresses, any Elastic IP addresses, and any IPv6 addresses
- If your instance is in an Auto Scaling group, the Amazon EC2 Auto Scaling service marks the stopped instance as unhealthy, and may terminate it and launch a replacement instance. To prevent this, you can suspend the scaling processes for the group while you're resizing your instance
- If your instance is in a cluster placement group and, after changing the instance type, the instance start fails, try the following: stop all the instances in the cluster placement group, change the instance type for the affected instance, and then restart all the instances in the cluster placement group
- The public IPv4 address of an instance does not change on reboot
- The VM is not returned to AWS on reboot
- For Amazon EC2 Linux instances using the cloud-init service, when a new instance from a standard AWS AMI is launched, the public key of the Amazon EC2 key pair is appended to the initial operating system user’s ~/.ssh/authorized_keys file
- For Amazon EC2 Windows instances using the ec2config service, when a new instance from a standard AWS AMI is launched, the ec2config service sets a new random Administrator password for the instance and encrypts it using the corresponding Amazon EC2 key pair’s public key
- You can set up the operating system authentication mechanism you want, which might include X.509 certificate authentication, Microsoft Active Directory, or local operating system accounts
- For spot instance,
- The Termination Notice will be available 2 minutes before termination
- The Termination Notice is accessible to code running on the instance via the instance’s metadata at
http://169.254.169.254/latest/meta-data/spot/termination-time - The spot/termination-time metadata field will become available when the instance has been marked for termination
- The spot/termination-time metadata field will contain the time when a shutdown signal will be sent to the instance’s operating system
- The Spot Instance Request’s bid status will be set to marked-for-termination
- The bid status is accessible via the DescribeSpotInstanceRequests API for use by programs that manage Spot bids and instances
- Amazon recommends that interested applications poll for the termination notice at five-second intervals
- If you get an InstanceLimitExceeded error when you try to launch a new instance or restart a stopped instance, you have reached the limit on the number of instances that you can launch in a region. Possible solutions
- request an instance limit increase on a per-region basis
- Launch the instance in a different region
- If you get an InsufficientInstanceCapacity error when you try to launch an instance or restart a stopped instance, it indicates AWS does not currently have enough available On-Demand capacity to service your request. Possible solutions
- Wait a few minutes and then submit your request again; capacity can shift frequently
- Submit a new request with a reduced number of instances
- If you're launching an instance, submit a new request without specifying an Availability Zone
- If you're launching an instance, submit a new request using a different instance type
- If you are launching instances into a cluster placement group, you can get an insufficient capacity error
- The following are a few reasons why an instance might immediately terminate:
- You've reached your EBS volume limit
- An EBS snapshot is corrupt
- The root EBS volume is encrypted and you do not have permissions to access the KMS key for decryption.
- The instance store-backed AMI that you used to launch the instance is missing a required part (an image.part.xx file)
- If the reason is Client.VolumeLimitExceeded: Volume limit exceeded, you have reached your EBS volume limit
- If the reason is Client.InternalError: Client error on launch, that typically indicates that the root volume is encrypted and that you do not have permissions to access the KMS key for decryption
- Make sure the private key (pem file) on your linux machine has 400 permissions, else you will get Unprotected Private Key File error
- Make sure the username for the OS is given correctly when logging via SSH, else you will get Host key not found error
- Possible reasons for ‘connection timeout’ to EC2 instance via SSH :
- Security Group is not configured correctly
- CPU load of the instance is high
- EC2 shutdown behavior (Behavior when shutdown signal is sent from inside the OS by running the shutdown command) -
- Stopped (Default) - The instance will be stopped on receiving the shutdown signal
- Terminated - The instance will be terminated on receiving the shutdown signal
- With shutdown protection turned on, the instnce cannot be terminated from the console until the shutdown protection is turned off
- Even with shutdown protection on, if the instance has its shutdown behavior as terminated, the shutdown initiated from the OS will terminate the instance
- AWS Support offers four support plans: Basic, Developer, Business, and Enterprise
- Reserved instances (both standard & Convertible) can be Zonal (restricted to a single availability zone for capacity reservation) or Regional (having instance size and availability zone flexibility)
- If your applications benefit from high packet-per-second performance and/or low latency networking, Enhanced Networking will provide significantly improved performance, consistence of performance and scalability. There is no additional fee for Enhanced Networking. To take advantage of Enhanced Networking you need to launch the appropriate AMI on a supported instance type in a VPC
EFS
- Supports Network File System version 4 (NFSv4)
- Read after write consistency
- Data is stored across multiple AZ's within a region
- No pre-provisioning required
- To use EFS
- install amazon-efs-utils
- mount the EFS at the appropriate location
- A security group needs to be attached with EFS allowing NFS(2049) inbound traffic from the security groups of the connecting EC2 instances
- To access EFS file systems from on-premises, you must have an AWS Direct Connect or AWS VPN connection between your on-premises datacenter and your Amazon VPC
- Amazon EFS offers a Standard and an Infrequent Access storage class
- Moving files to EFS IA starts by enabling EFS Lifecycle Management and choosing an age-off policy
- EFS Standard is designed to provide single-digit latencies on average, and EFS IA is designed to provide double-digit latencies on average
- Performance mode -
- General Purpose - default. Appropriate for most file systems
- Max I/O - optimized for applications where tens, hundreds, or thousands of EC2 instances are accessing the file system
- All file systems deliver a consistent baseline performance of 50 MB/s per TB of Standard class storage, all file systems (regardless of size) can burst to 100 MB/s, and file systems with more than 1TB of Standard class storage can burst to 100 MB/s per TB
- Due to the distributed storage, it experiences higher latency than EBS
- AWS DataSync is an online data transfer service that makes it faster and simpler to move data between on-premises storage and Amazon EFS
ELB
- ELB types -
- Classic Load Balancer (V1 - old generation) - Lower cost than ALB, but less flexibility
- Application Load Balancer (V2 - new generation) - Layer 7 - application aware
- Network Load Balancer (V2 - new generation) - Layer 4 - extreme performance
- ELB provides health check for instances
- ALB can handle multiple applications where each application has a traget group and load for that application is balanced across instances within the particular target group
- ALB supports HTTP/HTTPS & Websocket protocols
- ALB - True IP, port and protocol details of the client are inserted in HTTP headers - X-Forwarded-For, X-Forwarded-Port and X-Forwarded-Proto respectively
- ALB can route based on hostname in URL and route in URL
- ALB supports SNI (Server Name Indication). This allows ALB to support multiple TLS certificates
- Network Load Balancers are mostly used for extreme performance and should not be the default load balancer
- Network Load Balancers have less latency ~100 ms (vs 400 ms for ALB)
- Load Balancers have static host name. DO NOT resolve & use underlying IP
- LBs can scale but not instantaneously – contact AWS for a “warm-up”
- ELBs do not have a predefined IPv4 address. We resolve to them using a DNS name
- 504 error means the gateway has timed out and it is an application issue and NOT a load balancer issue
- Sticky session - required if the ec2 instance is writing a file to the local disk. Traffic will not go to other ec2 instances for the session (uses cookie and the validity duration of the cookie is configured at the time of enabling sticky session)
- If one AZ does not receive any traffic, check
- if Cross zone load balancing is enabled
- if the AZ is added in the load balancer config
- Path Patterns - Allows to route traffic based on the URL patterns
- The VPC and subnets need to be specified during configuration
- Elastic Load Balancing provides access logs that capture detailed information about requests sent to your load balancer
- Elastic Load Balancing captures the access logs and stores them in the Amazon S3 bucket (that you specify) as compressed and encrypted files
- Each access log file is automatically encrypted before it is stored in your S3 bucket and decrypted when you access it
- ALBs are priced per http request, Classic ELBs are priced by bandwidth consumption. Also ALBs are charged per routing rule. For a very high volume of small requests, ALBs can be much more expensive than an ELB
- Access logs are automatically encrypted
- Connection draining enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy.
Auto Scaling
- Auto scaling group is configured to register new instances to a traget group of ELB
- IAM role attached to the ASG will get assigned to the instances
- If instance gets terminated, ASG will restart it
- If instance is marked as unhealthy by load balancer, ASG will restart it
- ASG can scale based on CloudWatch alarms
- ASG can scale based on custom metric sent by applications to CloudWatch
- If all subnets in different availability zones are selected, the ASG will distribute the instances across multiple AZ
- During the configured warm up period the EC2 instance will not contribute to the auto scaling metrics
- Scaling out is increasing the number of instances and scaling up is increasing the resources
- The cooldown period helps to ensure that the Auto Scaling group doesn't launch or terminate additional instances before the previous scaling activity takes effect
- The default cooldown period is 300 seconds
- Cooldown period is applicable only for simple scaling policy
- Launch Configuration specifies the properties of the launched EC2 instances such as AMI etc.
- Launch configuration cannot be changed once created
- Scaling Policy -
- Target tracking scaling — Increase or decrease the current capacity of the group based on a target value for a specific metric. E.g. CPU Utilization or any other metric that will increase or decrease proportionally with the no. of instances
- Step scaling — Increase or decrease the current capacity of the group based on a set of scaling adjustments, known as step adjustments, that vary based on the size of the alarm breach. The configuration defines the desired number of instances for a range of value for the given metric. There could be multiple such steps defined
- Simple scaling — Increase or decrease the current capacity of the group based on a single scaling adjustment
- When there are multiple policies in force at the same time, there's a chance that each policy could instruct the Auto Scaling group to scale out (or in) at the same time. When these situations occur, Amazon EC2 Auto Scaling chooses the policy that provides the largest capacity for both scale out and scale in
- Default termination policy -
- Determine which Availability Zone(s) have the most instances, and at least one instance that is not protected from scale in
- Determine which instance to terminate so as to align the remaining instances to the allocation strategy for the On-Demand or Spot Instance that is terminating and your current selection of instance types
- Determine whether any of the instances use the oldest launch template
- Determine whether any of the instances use the oldest launch configuration
- Instances are closest to the next billing hour
- You can launch and automatically scale a fleet of On-Demand Instances and Spot Instances within a single Auto Scaling group. In addition to receiving discounts for using Spot Instances, if you specify instance types for which you have matching Reserved Instances, your discounted rate of the regular On-Demand Instance pricing also applies. The only difference between On-Demand Instances and Reserved Instances is that you must purchase the Reserved Instances in advance. All of these factors combined help you to optimize your cost savings for Amazon EC2 instances, while making sure that you obtain the desired scale and performance for your application
- You enhance availability by deploying your application across multiple instance types running in multiple Availability Zones. You must specify a minimum of two instance types, but it is a best practice to choose a few instance types to avoid trying to launch instances from instance pools with insufficient capacity. If the Auto Scaling group's request for Spot Instances cannot be fulfilled in one Spot Instance pool, it keeps trying in other Spot Instance pools rather than launching On-Demand Instances, so that you can leverage the cost savings of Spot Instances
- Amazon EC2 Auto Scaling provides two types of allocation strategies that can be used for Spot Instances:
- capacity-optimized - The capacity-optimized strategy automatically launches Spot Instances into the most available pools by looking at real-time capacity data and predicting which are the most available. By offering the possibility of fewer interruptions, the capacity-optimized strategy can lower the overall cost of your workload
- lowest-price - Amazon EC2 Auto Scaling allocates your instances from the number (N) of Spot Instance pools that you specify and from the pools with the lowest price per unit at the time of fulfillment
- An Auto Scaling group is associated with one launch configuration at a time, and you can't modify a launch configuration after you've created it. To change the launch configuration for an Auto Scaling group, use an existing launch configuration as the basis for a new launch configuration. Then, update the Auto Scaling group to use the new launch configuration. After you change the launch configuration for an Auto Scaling group, any new instances are launched using the new configuration options, but existing instances are not affected
EBS
- An EBS volume is a network drive
- An EC2 machine by default loses its root volume when terminated
- It's locked to an AZ. To move a volume to a different AZ, a snapshot needs to be created
- EBS Volume types:
- General Purposse SSD (GP2) - General purpose SSD volume
- Provisioned IOPS SSD (IO1) - Highest-performance SSD volume for mission-critical low-latency or high throughput workloads. Good for Databases.
- Throughput Optimized HDD (ST1) - Low cost HDD volume designed for frequently accessed, throughput intensive workloads. Good for big data and datawarehouses
- Cold HDD (SC1) - Lowest cost HDD volume designed for less frequently accessed workloads. Good for file servers
- EBS Magnetic HDD (Standard) - Previous generation HDD. For workloads where data is infrequently accessed
- io1 can be provisioned from 100 IOPS up to 64,000 IOPS per volume on Nitro system instance families and up to 32,000 on other instance families. The maximum ratio of provisioned IOPS to requested volume size (in GiB) is 50:1. Therefore, with a 10 Gib volume, the maximum provisioned IOPS should be 500
- The use of io1 is justified only when there is a requirement for sustained IOPS
- st1 bursts up to 250 MB/s per TB, with a baseline throughput of 40 MB/s per TB and a maximum throughput of 500 MB/s per volume
- st1 is good for MapReduce, Kafka, log processing, data warehouse, and ETL workloads
- sc1 bursts up to 80 MB/s per TB, with a baseline throughput of 12 MB/s per TB and a maximum throughput of 250 MB/s per volume
- When your workload consists of large, sequential I/Os, we recommend that you configure the read-ahead setting to 1 MiB
- Some instance types can drive more I/O throughput than what you can provision for a single EBS volume. You can join multiple gp2, io1, st1, or sc1 volumes together in a RAID 0 configuration to use the available bandwidth for these instances
- A factor that can impact your performance is if your application isn’t sending enough I/O requests. This can be monitored by looking at your volume’s queue depth. The queue depth is the number of pending I/O requests from your application to your volume. For maximum consistency, a Provisioned IOPS volume must maintain an average queue depth (rounded to the nearest whole number) of one for every 1000 provisioned IOPS in a minute. For example, for a volume provisioned with 3000 IOPS, the queue depth average must be 3. For more information about ensuring consistent performance of your volumes
- RAID 0
- Striping in multiple disk volumes
- When I/O performance is more important than fault tolerance
- Loss of a single volume results in complete data loss
- RAID 1
- When fault tolerance is more important than I/O performance
- Even in the absence of RAID 1, EBS is already replicated within AZ
- Max IOPS/Volume
- io1 - 64,000 (based on 16K I/O size)
- gp2 - 16,000 (based on 16K I/O size)
- st1 - 500 (based on 1 MB I/O size)
- sc1 - 250 (based on 1 MB I/O size)
- IOPS/GiB
- io1
- You can provision up to 50 IOPS per GiB
- Min 100 IOPS
- gp2
- Baseline performance is 3 IOPS per GiB
- Minimum of 100 IOPS
- General Purpose (SSD) volumes under 1000 GiB can burst up to 3000 IOPS
- io1
- SSD is good for short random access. HDD is good for heavy sequential access
- SSD provides high IOPS (np. of read-write per second). HDD provides high throughput (no. of bits read/written per second)
- The size and IOPS (only for IO1) can be increased
- Increasing the size or the volume does not automatically increase the size of the partition
- EBS volumes can be backed up using snapshots
- Snapshots are also used to resizing a volume down, changing the volume type and encrypting a volume
- Snapshots occupy only the size of data
- Snapshots exist on S3
- Snapshots are incremental
- It is sufficient to keep only the latest snapshot
- You can share your unencrypted snapshots with specific AWS accounts, or you can share them with the entire AWS community by making them public
- You can share an encrypted snapshot only with specific AWS accounts. For others to use your shared, encrypted snapshot, you must also share the CMK key that was used to encrypt it
- Snapshots of encrypted volumes are always encrypted
- Volumes restored from encrypted snapshots are encrypted automatically
- To take a snapshot of the root device, the instance needs to be stopped or volume needs to be detached (it is not required but recommended)
- Copying an unencrypted snapshot allows encryption
- EBS Encryption leverages keys from KMS (AES-256)
- All the data in flight moving between the instance and an encrypted volume is encrypted
- Encryption of a root volume involves following steps,
- Take a snapshot
- Copy the snapshot and choose the ecryption option (Once encrypted, it cannot be uncrypted by again making a copy)
- Create an Image (AMI) from the encrypted snapshot
- EBS backups use IO and hence backups should be taken during off-peak hours
- Each EBS volume is automatically replicated within its own AZ to protect from component failure and provide high availability and durability
- EC2 instance and its volume are going to be in the same AZ
- Migrating EBS to a different AZ or Region involves the following steps
- Create a snapshot
- Create an AMI
- Copy the AMI to a different Region
- Launch an EC2 instance in a different Region with the AMI
- The size and type of the EBS volumes can be changed without even stopping the EC2 instance
- AMI can be created directly from the volume as well
- AMI root device storage can be
- Instance Store (Ephemeral Stores)
- EBS Backed Volumes
- Instance store volumes are created from a template stored in Amazon S3
- Instance stores are attached to the host where the EC2 is running, whereas EBS volumes are network volumes. However, in 90% of the use cases the difference in latency with the two types of stores does not make any difference
- Instance stores survive reboot, but NOT termination
- gp2 Throughput (in MiB/sec) = (Volume size in GiB) * (IOPS per GiB) * (I/O size in KiB). The I/O size is 256KiB (earlier 16KiB).
- gp2 - Max Throughput 250 MiB/sec (volumes >= 334 GiB won't increase throughput)
- io1 Throughput (in MiB/sec) = (IOPS per GiB) * (I/O size in KiB). If the IOPS provisioned is 500, the instance can achieve 500 * 256KiB writes per second
- io1 - Max Throughput 500 MiB/sec (at 32,000 IOPS) and 1000 MiB/sec (at 64,000 IOPS)
- EBS Optimized Instances - With small additional fee, customers can launch certain Amazon EC2 instance types as EBS-optimized instances. EBS-optimized instances enable EC2 instances to fully use the IOPS provisioned on an EBS volume. Contention between Amazon EBS I/O and other traffic from the EC2 instance is minimized
- Amazon Data Lifecycle Manager (Amazon DLM) automates the creation, deletion and retention of EBS snapshots
- Improving I/O performance
- Use RAID 0
- Increase size of EC2 instance
- Use appropriate volume types
- Enhanced Networking feature can provide higher I/O performance and lower CPU utilization to the EC2 instance. However, HVM AMI instead of PV AMI is required
- EBS can provide the lowest latency store to a single EC2 instance. EBS latency is lesser than S3 even with VPC endpoint
- You can configure your AWS account to enforce the encryption of your EBS volumes and snapshots. Activating encryption by default has two effects:
- AWS encrypts new EBS volumes on launch
- AWS encrypts new copies of unencrypted snapshots
- Encryption by default is a Region-specific setting. If you enable it for a Region, you cannot disable it for individual volumes or snapshots in that Region
- Newly created EBS resources are encrypted by your account's default customer master key (CMK) unless you specify a customer managed CMK in the EC2 settings or at launch
- EBS encrypts your volume with a data key using the industry-standard AES-256 algorithm. Your data key is stored on-disk with your encrypted data, but not before EBS encrypts it with your CMK; it never appears on disk in plaintext
- When you have access to both an encrypted and unencrypted volume, you can freely transfer data between them. EC2 carries out the encryption and decryption operations transparently
- To create snapshots for Amazon EBS volumes that are configured in a RAID array, there must be no data I/O to or from the EBS volumes that comprise the RAID array. These same precautions and steps should be followed whenever you create a snapshot of an EBS volume that serves as the root device for an EC2 instance
- Although snapshots are incremental, snapshots are designed in such a way that retaining the last snapshot is sufficient to recover the complete volume data. Deleting the old snapshots may not reduce the occupied storage. Snapshots copy only the data that have changed since the last snapshot was taken and points to the unchanged data of the last snapshot
- Volumes can be resized
- increase in size
- increase in IOPS (for io1)
- change in volume type
- After resizing, the volume needs to be repartitioned
- After resizing, the volume will remain in "optimization" phase for some time. While the volume will remai usable, but the performancce will not be good
- EBS volumes restored from the snapshots need to be pre-warmed for optimal performance (fio or dd command will read the entire volume ad thus helps in pre-warming)
- EBS Volume migration to a different region
- Take a snapshot
- Copy snapshot to a different region
- Restore volume from the snapshot
- EBS Volume migration to a different AZ
- Take a snapshot
- Restore volume from the snapshot in a different AZ
- High wait time of SSD can be resolved by provisioning more IOPS in io1
- You can stripe multiple volumes together to achieve up to 75,000 IOPS or 1,750 MiB/s when attached to larger EC2 instances. However, performance for st1 and sc1 scales linearly with volume size so there may not be as much of a benefit to stripe these volumes together

- Note that you can't delete a snapshot of the root device of an EBS volume used by a registered AMI. You must first deregister the AMI before you can delete the snapshot
- To take a consistent snapshot, unmount the volume, initiate the snapshot and mount it back (The ongoing reads and writes do not affect the snapshot once it is started)
CloudWatch
- CloudWatch is for monitoring performance, whereas CloudTrail is for auditing API calls
- CloudWatch with EC2 will monitor events every 5 min by default - basic monitoring
- With detailed monitoring, the interval will be 1 min. Use detailed monitoring for prompt scaling actions in ASG
- CloudWatch alarms can be created to trigger notifications when a certain metric reaches a certain value
- We can create a CloudWatch Events Rule That triggers on an AWS API Call Using AWS CloudTrail
- Enabling CloudWatch logs for EC2
- Assign appropriate CloudWatch access policy to the IAM role
- Install CloudWatch agent (awslogsd) in EC2
- Since EC2 does not have access to the underlying OS, some metrics are missing including disk and memory utilization
- CloudWatch can collect metrics and logs from services, resources and applications on AWS as well on-premise services
- CloudWatch Alarms can be created to
- send SNS notifications
- do EC2 autoscaling when a certain metrics satisfies a configured condition
- do EC2 actions (Against EC2 metrics only)
- Recover - Recover the instance on different hardware
- Stop
- Terminate
- Reboot
- CloudWatch Events allow users to do some activity (by triggering a Lambda function) on real time when some system change happens. CloudTrail cannot do this because CloudTrail deliver logs in around 15 minutes interval
- CloudWatch Events doesn't get triggered on read events
- CloudWatch Alarm Status
- impaired - checks failed
- insufficient data - checks in progress
- ok - all checks passed
- Amazon CloudWatch does not aggregate data across Regions. Therefore, metrics are completely separate between Regions
- For EC2, AWS provides the following CloudWatch metrics
- CPU - CPU Utilization + Burst Credit Usage / Balance
- Network - Network In / Out
- Disk - Read / Write for Ops / Bytes (only for instance store)
- Status Check
- Instance status - checks the EC2 VM
- System status - checks the underlying hardware
- For custom metrics (API - PutMetricData)
- Basic resolution - 1 min interval
- High resolution - 1 sec interval
- CloudWatch dashboards are global. Dashboards can include graphs from different regions
- Metric Filter can be used to find a specific log message based on pattern and create a metric on the number of occurence of the message
- Using AWS CLI, we can tail CloudWatch logs
- You can use subscriptions to get access to a real-time feed of log events from CloudWatch Logs and have it delivered to other services such as a Amazon Kinesis stream, Amazon Kinesis Data Firehose stream, or AWS Lambda for custom processing, analysis, or loading to other systems. To begin subscribing to log events, create the receiving source, such as a Kinesis stream, where the events will be delivered. A subscription filter defines the filter pattern to use for filtering which log events get delivered to your AWS resource, as well as information about where to send matching log events to
- CloudWatch logs can go to
- S3 for archival (one time batch)
- Stream to Elastic Search
- Stream to Lambda (Lambda provides blueprints for streaming log events to Splunk or other services)
- Logs are not automatically encrypted. Need to be enabled at log group level

CloudTrail
- By default CloudTrail keeps account activity details upto 90 days
- These events are limited to management events with create, modify, and delete API calls and account activity. For a complete record of account activity, including all management events, data events, and read-only activity, you’ll need to configure a CloudTrail trail
- By setting up a CloudTrail trail you can deliver your CloudTrail events to Amazon S3, Amazon CloudWatch Logs, and Amazon CloudWatch Events
- You can create up to five trails in an AWS region. A trail that applies to all regions exists in each region and is counted as one trail in each region
- By default, CloudTrail log files are encrypted using S3 Server Side Encryption (SSE) and placed into your S3 bucket
- CloudTrail integration with CloudWatch logs enables you to receive SNS notifications of account activity captured by CloudTrail. For example, you can create CloudWatch alarms to monitor API calls that create, modify and delete Security Groups and Network ACL’s
- Logs are automatically encrypted
CloudFormation
- AWS CloudFormation templates are JSON or YAML-formatted text files that are comprised of five types of elements:
- An optional list of template parameters (input values supplied at stack creation time)
- An optional list of output values (e.g. the complete URL to a web application)
- An optional list of data tables used to lookup static configuration values (e.g., AMI names)
- The list of AWS resources and their configuration values (mandatory)
- A template file format version number
Route 53
- In AWS, the most common records are:
- A: URL to IPv4
- AAAA: URL to IPv6
- CNAME: URL to URL
- Alias: URL to AWS resource.
- Prefer Alias over CNAME for AWS resources (for performance reasons)
- Route53 has advanced features such as:
- Load balancing (through DNS – also called client load balancing)
- Health checks (although limited…)
- Routing policy: simple, failover, geolocation, geoproximity, latency, weighted, multivalue answer
- IPv4 - 32 bit, IPv6 - 128 bit
- Simple Routing - Multiple IP addresses against a single A record. Route 53 returs all of them in random order
- Wighted Routing - A separate A record for each IP with a percentage weight. A separate health check can be associated with each IP or A record. SNS notification can be sent if a health check fails. If a health check fails, the server is removed from Route 53, until the health check passes
- Latency Based Routing - A separate A record for each IP with a percentage weight. A separate health check can be associated with each IP or A record. Routing happens to the server with lowest latency
- Failover Routing - 2 separate A records - one for primary and one for secondary. Health check can be associated with each, If primary goes down, traffic will all be ruted to secondary
- Geolocation Based Routing - A separate A record for each IP. Each A record is mapped to a location and the routing happens to a specific server depending on which location the DNS query originated. Good for scenarios where different website will have different language labels based on location
- Multivalue Answer - Simple routing with health checks of each IP
- Geoproximity - Must use Route 53 Traffic Flow. Routes traffic based on geographic location of users and resources. This can be further influenced with biases
- You configure active-active failover using any routing policy (or combination of routing policies) other than failover, and you configure active-passive failover using the failover routing policy
- Amazon Route 53’s DNS services does NOT support DNSSEC at this time
RDS
- Databases supported -
- Postgres
- Oracle
- MySQL
- MariaDB
- Microsoft SQL Server
- Aurora
- Upto 5 Read Replicas (Async Replication - within AZ, cross AZ or cross Region)
- Read replicas of read replicas are possible
- Each read replica will have its own DNS endpoint
- Read replica can be created in a separate region as well
- If a read replica is promoted to its own database, the replication will stop
- Read replica cannot be enabled unless the automatic backups are also enabled
- Oracle does not support Read replica
- Read replicas themselves can be Multi-AZ* for disaster recovery
- Read Replicas can help in Disaster Recovery by cross-region read-replica
- Each Read Replica will have its own read endpoint
- Read Replicas can be used to run BI / Analytics reports
- A failover in a Multi-AZ deployment can be forced by rebooting the DB
- Multi-AZ cannot be cross-region
- Multi-AZ happens in the following use cases
- Primary DB instance fails
- Availability zone outage
- DB instance server type changed
- DB instance OS undergoing software patching
- Manual failover using reboot with failover
- With Multi-AZ there is less impact on primary for backup & maintenance as the backup happens from standby and maintenance patches are first applied on standby and then the standby is promoted to become the primary
- Primary database and the Multi-AZ Standby will have a common DNS name
- Two ways of improving performance
- Read replicas
- ElastiCache
- Replication for Disaster Recovery is synchronous (across AZ - Automatic failover - DNS endpoint remains same) - Multi AZ
- Replicas can be promoted to their own DB
- Automated backups:
- Daily full snapshot of the database
- Capture transaction logs in real time
- Ability to restore to any point in time
- 7 days retention (can be increased to 35 days)
- The backup data is stored in S3
- Backups are taken during specified window. The application may experience elavated latency during backup
- Restoring DB from automatic backup or snapshots always creates a new RDS instance with a new DNS endpoint
- DB Snapshots:
- Manually triggered by the user
- Retention of backup for as long as we want
- Can be taken on the Multi AZ standby and thus minimizing impact on the master
- Incremental after the first which is full
- Can copy and share snapshots
- Steps to encrypt unencrypted DB - Snapshot => copy snapshot as encrypted => create DB from snapshot
- Encryption at rest capability with AWS KMS - AES-256 encryption
- To enforce SSL:
- PostgreSQL: rds.force_ssl=1 in the AWS RDS Console (Paratemer Groups)
- MySQL: Within the DB: GRANT USAGE ON . TO 'mysqluser'@'%' REQUIRE SSL;
- To connect using SSL:
- Provide the SSL Trust certificate (can be download from AWS)
- Provide SSL options when connecting to database
- RDS, in general, is not serverless (except Aurora Serverless which is serverless)
- We cannot access the RDS virtual machines. Patching the RDS operating system is Amazon's responsibility
- CloudWatch Metrics (Gathered from the Hypervisor) -
- DatabaseConnections
- SwapUsage
- ReadIOPS / WriteIOPS
- ReadLatency / WriteLatency
- ReadThroughPut / WriteThroughPut
- DiskQueueDepth
- FreeStorageSpace
- Enhanced Monitoring metrics are useful when it is required to see how different processes or threads on a DB instance use the CPU
- IAM users can be used to manage DB (only for MySQL/Aurora)
- Key RDS APIs
- DescribeDBInstances - Lists DB instances including read replicas and also provides DB version
- CreateDBSnapshot
- DescribeEvents
- RebootDBInstance
- RDS Performance Insights
- By Waits - find the resource that is bottleneck (CPU, IO, lock etc.)
- By SQL Statements - find the SQL statement that is problem
- By Hosts - find the server that is using the DB most
- By Users - find the user that is using the DB most
DynamoDB
- Supports both document and key-value data model
- Stored on SSD storage
- Spread across 3 geographically distributed data centers
- Supports both Eventual Consistant Reads (Default) & Strongly Consistant Reads
- Serverless service
- Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache that can reduce Amazon DynamoDB response times from milliseconds to microseconds
- DynamoDB auto scaling modifies provisioned throughput settings only when the actual workload stays elevated (or depressed) for a sustained period of several minutes
- To enable DynamoDB auto scaling for the ProductCatalog table, you create a scaling policy. This policy specifies the following:
- The table or global secondary index that you want to manage
- Which capacity type to manage (read capacity or write capacity)
- The upper and lower boundaries for the provisioned throughput settings
- Your target utilization
Redshift
- Amazon's data warehouse solution
- Single node (160 GB) or multi node (leader node and compute node - upto 128 compute nodes)
- Column based data store, column based compression techniques and multiple other compression techniques
- No indexes or materialized views
- Massively parallel processing
- Redshift attempts to maintain 3 copies of data (the original and replica on the compute nodes and a backup in S3)
- Available in only 1 AZ
- Backup retention period is 1 day by default which can be extended to 35 days
- Can asynchronously replicate to S3 in a different region for disaster recovery
- Redshift Spectrum is a feature of Amazon Redshift that enables you to run queries against exabytes of unstructured data in Amazon S3, with no loading or ETL required
- With enhanced VPC Routing, Amazon Redshift forces all COPY and UNLOAD traffic between the Redshift cluster and the data repositories through the Amazon VPC. When we use Enhanced VPC Routing to route traffic through your VPC, you can also use VPC flow logs to monitor COPY and UNLOAD traffic.
- Amazon Redshift logs information about connections and user activities in your database. These logs help you to monitor the database for security and troubleshooting purposes, which is a process often referred to as database auditing. The logs are stored in the Amazon Simple Storage Service (Amazon S3) buckets
- Connection log — logs authentication attempts, and connections and disconnections
- User log — logs information about changes to database user definitions
- User activity log — logs each query before it is run on the database
- work load management
Aurora
- Aurora storage automatically grows in increments of 10GB, up to 64 TB
- Aurora can have 15 replicas while MySQL has 5, and the replication process is faster (sub 10 ms replica lag)
- 2 copies of data is maintained in each AZ with a minimum of 3 AZ
- Compute resources can scale upto 32 vCPUs and 244 GB of memory
- Aurora costs 20% more than RDS
- Aurora can transparently handle the loss of 2 copies of data without affecting write availability and 3 copies of data without affecting read availability
- Backups and snapshots does not impact database performance
- Storage is self-healing. Disks and blocks are scanned for errors and repaired automatically
- Aurora snapshots can be shared with other AWS accounts
- Two types of replicas - MySQL replicas (based on MySQL binlog) and Aurora Replicas
- Automated failover is only possible with Aurora replicas (not MySQL replicas)
- Failover in Aurora is instantaneous. It’s HA native
- If you have an Amazon Aurora Replica, in the same or a different Availability Zone, when failing over, Aurora flips the canonical name record (CNAME) for your DB Instance to point at the healthy replica, which is in turn promoted to become the new primary. Start-to-finish, failover typically completes within 30 seconds
- If you are running Aurora Serverless and the DB instance or AZ become unavailable, Aurora will automatically recreate the DB instance in a different AZ
- If you do not have an Amazon Aurora Replica (i.e. single instance) and are not running Aurora Serverless, Aurora will attempt to create a new DB Instance in the same Availability Zone as the original instance
- Disaster recovery across regions is a manual process, where you promote a secondary region to take read/write workloads
- Aurora Endpoints -
- Cluster Endpoint - Primary DB for read-write
- Reader Endpoint - load balanced read replicas for reading
- Custom endpoint - load balanced groups of read replicas (max 5 custom endpoints)
- The amount of replication is independent of the number of DB instances in your cluster
- The Aurora shared storage architecture makes your data independent from the DB instances in the cluster. For example, you can add a DB instance quickly because Aurora doesn't make a new copy of the table data. Instead, the DB instance connects to the shared volume that already contains all your data
ElastiCache
- ElastiCache is to get managed Redis or Memcached
- ElastiCache features -
- Write Scaling using sharding
- Read Scaling using Read Replicas
- Multi AZ with Failover Capability
- Redis - Multi AZ, Backups and restore
- Memcached - Multi threaded, horizontal scaling
- Elastic cache can be used as - db cache, session store
- Caching patterns -
- Write through
- Lazy loading
VPC
- VPC Architecture Diagram

- VPC Architecture Diagram with IPV6

- VPC Flow Logs allows us to monitor the traffic within, in and out of your VPC (useful for security, performance, audit)
- VPC are per Account per Region
- Subnets are per VPC per AZ
- Subnet doesn't span across AZ
- Inter AZ data transfer is chargeable
- You are initially limited to launching 20 Amazon EC2 instances per Region at any one time and a maximum VPC size of /16 (65,536 IPs)
- Max CIDR per VPC - 5 (Soft limit)
- Max VPC size - /16 - 65536 IP
- Min VPC size - /28 - 16 IP
- Max 5 VPC per region (Soft limit)
- One VPC can be attached to only one Internet Gateway and vice versa
- Internet gateway is also a NAT for EC2 istances with a public IP
- A subnet can be configured to automatically assign a public IP to the launched instances
- Security Groups doesn't span across VPC
- A VPC can have only 1 internet Gateway
- Amazon reserves 5 IP in each subnet - 4 at the begining & 1 at the end
- Each EC2 instance performs source/destination checks by default. This means that the instance must be the source or destination of any traffic it sends or receives. However, a NAT instance must be able to send and receive traffic when the source or destination is not itself. Therefore, we must disable source/destination checks on the NAT instance
- NAT instace / gateway must be in public subnet
- A route from private subnet to NAT Gateway is important
- NAT instance must have a security group
- NAT Gateway is redundant inside an AZ
- NAT Gateway starts at 5 Gbps and scales upto 45 Gbps
- NAT Gateway don't need a security group
- NAT Gateway automatically have a public IP assigned
- With NAT Gateway there is no need to disable source / destination checks
- Create a NAT Gateway in each AZ and configure the route to use the NAT Gateway in the same AZ
- Once a NAT Gateway is created, its elastic IP cannot be disassociated from it until the NAT gateway is deleted. Disassociation does not automatically return the eleastic IP
- The NACL of the subnet applies to the NAT Gateway
- A NAT gateway cannot send traffic over VPC endpoints, AWS Site-to-Site VPN connections, AWS Direct Connect, or VPC peering connections. If your instances in the private subnet must access resources over a VPC endpoint, a Site-to-Site VPN connection, or AWS Direct Connect, use the private subnet’s route table to route the traffic directly to these devices
- To avoid data processing charges for NAT gateways when accessing Amazon S3 and DynamoDB that are in the same Region, set up a gateway endpoint and route the traffic through the gateway endpoint instead of the NAT gateway. There are no charges for using a gateway endpoint
- NAT Gateway limit - 5 per AZ
- To increase the limit of NAT gateway or that of elastic IP use Amazon VPC Limits Form
- The public subnet must be configured to asign public IP addresses to the EC2 machines
- NACL is evaluated before security groups
- NACL's rules are executed in chronological order with lowest numbered rule evaluated first. Therefore DENY should come before ALLOW
- Default NACL allows all inbound and outbound traffic
- Custom NACL by default denies all inbound and outbound traffic
- A subnet can be associated with only one NACL and one NACL can be assigned to multiple subnets
- NACLs are stateless unlike security groups
- Default NACL allows all outbound and inbound traffic
- By default, each custom NACL denies all inbound and outbound traffic
- Each subnet in a VPC must be associated with a NACL. If we do not assign an NACL with the subnet, the subnet will have the default NACL assigned
- IP addresses can be blocked by NACL and NOT security groups
- VPC Security Flow

- 2 public subnets are required to create a load balancer
- VPC flow logs capture information about IP traffic going to and from the network interfaces in the VPC
- Flow logs are stored in Cloudwatch logs
- Flow logs can be created at VPC level, subnet level or network interface level
- Flow logs cannot be enabled for VPCs that are peered with our VPC unless the peered VPCs belong to our AWS account
- Flow logs cannot be tagged
- Once a Flow log is created, its configuration cannot be changed
- Not all traffic is monitored in VPC Flow log. Traffic not monitored include:
- DHCP traffic
- Traffic to and from Amazon DNS
- Traffic of Amazon Windows License activation
- Traffic to and from 169.254.169.254 for instance metadata
- Traffic to the reserved IP address for the default VPC router
- 169.254.0.0/16
- Routing in the subnet
- A Bastion host is a special purpose computer specially designed to withstand attacks. The computer usually hosts a single application, e.g. a proxy server, and all other services are removed or limited to reduce the threat to the computer. It is hardened in this manner primarily due to its location and purpose which is either on the outside of a firewall or in a demelitarized zone (DMZ) and usually involves access from untrusted networks or computers
- A NAT Gateway is used to provide internet traffic to the private subnet
- A Bastion host is used to administer the EC2 instances in the private subnet using SSH or RDP
- Traditionally, multiple users can connect to a Bastion host either by sharing a key pair, or by adding the public keys of each user in the authorized keys of the bastion host. A more secured way is to avoid key pairs and use EC2 Instance Connect which will allow the users connect to the bastion host based on IAM policies attached to their IAM users or roles
- AWS Direct Connect provides reliable, high throughput, dedicated and secure connection from the local data center to the AWS
- A Corporare network can be connected to a VPC using a VPN over the internet or a VPN over AWS Direct Connect. VPN over Direct Connect is significantly more expensive than over internet
- Using AWS Direct Connect, a dedicated private network connection between the AWS VPC and corporate network can be established
- AWS Direct Connect use cases
- Increased bandwidth throughput
- Consistent connection
- AWS Direct Connect requires physical connection established between the corporate network and the AWS Direct Connect Location
- AWS Direct Connect can be setup to connect to multiple VPCs (even in different region) in the same account by using a AWS Direct Connect Gateway. However, for the VPCs to talk to each other a VPC Peering connection is required
- VPC endpoints allow the VPC to privately connect to the supported AWS services without leaving the AWS network. The instances in the VPC do not require public IP * Two types of VPC Endpoints -
- Interface Endpoints - An elastic network interface with a private IP address that serves as an entrypoint for traffic destined to a supported service
- Gateway Endpoints - Only for S3 and DynamoDB
- Interface endpoints are powered by AWS PrivateLink - doesn't require public IP
- VPC Endpoints support only IPv4 traffic
- Gateway VPC Endpoints - The service and the VPC must be in the same region (AWS PrivateLink powered Interface Endpoints do not have this limitation since 2018)
- Currently, no CloudWatch metric is available for the interface-based VPC endpoint
- With Gateway VPC Endpoint, you must enable DNS resolution in your VPC
- With Interface VPC Endpoint,
- The instances can connect to the AWS service using endpoint specific DNS name, if private DNS is not enabled
- The instances can also connect to the AWS services using the default DNS name, if private DNS is enabled
- To use private DNS, DNS hostname and DNS support must be enabled in VPC
- Enabling DNS hostname and DNS support gives public DNS names to EC2 instances that have public IP or Elastic IP addresses
- VPC Peering can connect to VPC in same account or different account, in same region or different region
- VPC Peering does not need Internet Gateway
- VPC Peering traffic withing region is not encrypted, but across region is AEAD encrypted
- By default, a query for a public hostname of an instance in a peered VPC in a different region will resolve to a public IP address. Route 53 private DNS can be used to resolve to a private IP address with Inter-Region VPC Peering
- Inter-Region VPC Peering doesn't support IPv6
- Services that cannot be used over VPC Peering - EFS, Network Load Balancer, AWS PrivateLink
- VPC Peering connection does not support edge to edge routing or transitive routing
- VPC Peering needs route table configuration
- On creation of a VPC, a default route table, NACL and security group are automatically created. Subnets and Internet Gateways are not automatically created
- US-East-1A in one AWS account can be completely different from US-East-1A in another AWS account
- Traffic Flow -
- Internet Gateway -> Router -> Route Table -> NACL -> Security Group -> NAT Instance -> EC2 in private subnet
- Internet Gateway -> Router -> Route Table -> NACL -> NAT Gateway -> EC2 in private subnet
- To be able to SSH into an EC2 system in a public subnet of a custom VPC, following are required
- An internet gateway should be assigned to the VPC
- The public subnets should be associated with a custom route table that should have a route that will allow destination to everywhere (0.0.0.0/0) through the internet gateway
- Private subnets should be associated with a custom NACL that allows traffic to and from the public subnets (atleast SSH & ICMP) and internet (for NAT Gateway to work)
- Private subnet should be associated with a route table that route all internet traffic (0.0.0.0/0) to the NAT Gateway
- ENI - ENI (Elastic Network Interface) is attached to a subnet of VPC and cannot be used across Availability Zone or VPC
- ENI - ENI has IP, source & destination check flag, MAC address and security groups attached
- ENI - All EC2 instances have a primary ENI. Additional ENIs can be
- ENI - ENI can be used to design low cost high availability by reassigning the ENI to a new EC2 instance when the original instance fails
- ENI - Customer will be charged if the Elastic IP is attached to an ENI which is not associated with any running instance
- ENI - Attach termminology
- Hot Attach - When the instance is running
- Warm Attach - When the instance is stopped
- Cold Attach - When the instance is being launched
- Backup & Recovery strategies
- Backup & Restore - Low cost DR approach backs up your data and applications from anywhere to the AWS cloud for use during recovery from a disaster
- Pilot Light - A small part of the infrastructure is always running simultaneously syncing mutable data (as databases or documents), while other parts of the infrastructure are switched off and used only during testing
- Warm Standby - A scaled-down version of a fully functional environment is always running in the cloud
- Multi-Site - A multi-site solution runs on AWS as well as on your existing on-site infrastructure in an active- active configuration
- To enable Lambda function to access resources inside a private VPC, we must provide additional VPC-specific configuration information that includes private subnet IDs and security group IDs. AWS Lambda uses this information to set up elastic network interfaces (ENIs) that enable the function to connect securely to other resources within the private VPC
- Each ENI is assigned a private IP address from the IP address range within the subnets you specify. Lambda functions that are connected to a VPC do not have public IP addresses or internet access by default. A NAT Gateway is required, if the function needs internet access
- If the VPC does not have sufficient ENIs or subnet IPs, the Lambda function will not scale as requests increase, and we will see an increase in invocation errors with EC2 error types like EC2ThrottledException
- You cannot detach a primary ENI from an instance
- Third party TLS certificates can be imported to either AWS Certificate Manager or IAM certificate store
- Security Groups are applied at the instance level, whereas NACLs are at the subnet level
- When you add an Internet gateway, an egress-only Internet gateway, a virtual private gateway, a NAT device, a peering connection, or a VPC endpoint in your VPC, you must update the route table for any subnet that uses these gateways or connections
- A Site-to-Site VPN connection consists of a virtual private gateway attached to your VPC and a customer gateway located in your data center
- The IP address of the customer gateway is either is either an internet routable public IP or the NAT public IP of the corporate network
- An egress-only Internet gateway is for use with IPv6 traffic only. It allows outbound communication over IPv6 from instances in a VPC to the Internet, and prevents the Internet from initiating an IPv6 connection with the instances (Similar to NAT Gateway for IPv4)
- The Internet Gateway works with both IPv6 and IPV4 and it does Network Address Translation (NAT) between the public IP and the private subnet IP for the instances while communicating with the resources in the internet
- Ephemeral ports - Clients receives response to server requests on random ports in the range 1024-65535 (ephemeral ports). Security groups don't need to handle ephemeral ports as security groups are stateful, outbound traffic to allowed inbound traffic is always allowed. However, NACL needs to add proper entries for ephemeral ports
- AWS PrivateLink - As a service user, you will need to create interface type VPC endpoints for services that are powered by PrivateLink. These service endpoints will appear as Elastic Network Interfaces (ENIs) with private IPs in your VPCs. Once these endpoints are created, any traffic destined to these IPs will get privately routed to the corresponding AWS services
- AWS PrivateKink - As a service owner, you can onboard your service to AWS PrivateLink by establishing a Network Load Balancer (NLB) to front your service and create a PrivateLink service to register with the NLB. Your customers will be able to establish endpoints within their VPC to connect to your service after you whitelisted their accounts and IAM roles
- Bring Your Own IP (BYOIP) - Customers can move all or part of their existing publicly routable IPv4 address space to AWS for use with their AWS resources. Customers will continue to own the IP range, however, AWS will take over its advertisement on the internet. Customers can create Elastic IPs from the IP space they bring to AWS and use them with EC2 instances, NAT Gateways, and Network Load Balancers. Customers will continue to have access to Amazon-supplied IPs and can choose to use BYOIP Elastic IPs, Amazon-supplied IPs, or both
- Use Cases of BYOIP -
- IP Reputation
- IP Whitelisting
- IP Hardcoding
- Regulation & Compliance
- Amazon VPC traffic mirroring, provides deeper insight into network traffic by allowing you to analyze actual traffic content, including payload, and is targeted for use-cases when you need to analyze the actual packets to determine the root cause a performance issue, reverse-engineer a sophisticated network attack, or detect and stop insider abuse or compromised workloads
- Default VPCs are assigned a CIDR range of 172.31.0.0/16. Default subnets within a default VPC are assigned /20 netblocks within the VPC CIDR range
- Currently, Amazon VPC supports five (5) IP address ranges, one (1) primary and four (4) secondary for IPv4. Each of these ranges can be between /28 (in CIDR notation) and /16 in size. The IP address ranges of your VPC should not overlap with the IP address ranges of your existing network
- For IPv6, the VPC is a fixed size of /56 (in CIDR notation). A VPC can have both IPv4 and IPv6 CIDR blocks associated to it
- For VPCs with a hardware VPN connection or Direct Connect connection, instances can route their Internet traffic down the virtual private gateway to your existing datacenter. From there, it can access the Internet via your existing egress points and network security/monitoring devices
- An internet gateway is not required to establish an AWS Site-to-Site VPN connection
- Amazon supports Internet Protocol Security (IPSec) VPN connections
- Traffic between two EC2 instances in the same AWS Region stays within the AWS network, even when it goes over public IP addresses
- Traffic between EC2 instances in different AWS Regions stays within the AWS network, if there is an Inter-Region VPC Peering connection between the VPCs where the two instances reside
- You may use a third-party software VPN to create a site to site or remote access VPN connection with your VPC via the Internet gateway
- Analyzing VPC Flow logs
- For inbound traffic, if inbound is ACCEPT, but outbound is REJECT, it is only an NACL problem
- For outbound traffic, if outbound is ACCEPT, but inbound is REJECT, it is only an NACL problem
SQS
- SQS is pull based, NOT push based
- Messages are 256 KB in size
- Messages can be kept in the queeu from 1 minute to 14 days; the default retention period is 4 days
- Visibility Timeout is the amount of time that the message is invisible in the SQS queue after a reader picks up that message. If the message is processed successfully before the timeout expires, the message will be deleted from the queue. Otherwise, the message will again become visible after the timeout for another reader to pick it up for processing. This could result is message being delivered twice
- Visibility Timeout maximum is 12 hours
- Standard queue guarantees that the message will be delivered at least once
- Standard queue lets us have a nearly unlimited number of transactions per second
- Standard queue may deliver more than one copy of the same message
- Standard queue provides best effort ordering; out of order delivery is possible
- SQS Long Polling API call doesn't return until a message arrives in the queue or the long poll times out. This result in less number of API calls and thus less cost
- FIFO queue strictly preserves order
- FIFO queue gurantees exactly-once delivery
- FIFO queue is limited to 300 transactions per second
- FIFO queues also support message groups that allow multiple ordered message groups within a single queue
- It's a way to decouple infrastructure
- After consuming the message the client app must call SQS API to delete the message
SWF
- Workflow service viz. human interaction
- SWF workflow execution can last upto 1 year
- SWF provides a task oriented API, whereas SQS peovides a message oriented API
- SWF Actors
- Workflow Starters
- Deciders -
- Handles special tasks called decision tasks. Amazon SWF issues decision tasks whenever a workflow execution has transitions such as an activity task completing or timing out
- decides the next steps, including any new activity tasks, and returns those to Amazon SWF
- Activity Workers
- SWF is a fully-managed state tracker and task coordinator service. It does not provide serverless orchestration to multiple AWS resources. AWS Step Functions provides serverless orchestration for modern applications
SNS
- Push notifications to mobile devices
- SMS, email & HTTP endpoints
- Push based delivery, no polling
- Stored redundantly across multiple AZ
- Supports multiple topics
API Gateway
- Supports caching of API response
- Allows enabling CORS to access multiple AWS resources with different origin name using Javascript
- Allows logging result to CloudWatch
- Allow throttling to prevent attacks
- CORS is enforced by client's browser
Kinesis
- Amazon alternative of Kafka
- Streaming data
- Types of Kinesis
- Kinesis Streams
- Kinesis Analytics
- Kinesis Firehose
- Default retention period 24 hours
- Maximum retention period 7 days
- Kinesis Shard Read - 5 transactions per second upto a total data rate of 2MB per second
- Kinesis Shard Write - 1000 records per second upto a maximum data write of 1 MB per second
- The total capacity of the stream is the sum of the capacities of its shards
- Kinesis Streams have shards
- Kinesis Firehose doesn't have a persistent store. As soon as the data comes in, the data needs to be processed optionally using Lambda functions and send it to the appropriate data stores
Cognito
- User pool consists of user data like email, userid etc. It handles authentication, registration, recovery etc.
- Identity pools are temporary IAM roles to access various AWS resources
- Cognito uses push synchronizations and SNS notifications to push updates across devices
- Cognito is an Identity broker which handles interaction between the AWS applications and the Web Id Provider
- Active Directory - SAML Federation
- If the corporate identity store is not compatible with SAML 2.0, then we can build a custom identity broker application to perform a similar function. The broker application authenticates users, requests temporary credentials for users from Amazon STS, and then provides them to the user to access AWS resources.
OpsWorks
- Managed configuration management system
- Provides managed instancess of Chef and Puppet
CodeDeploy
-
EC2/on-premise Deployment Configuration
- All At Once
- In-place deployments - Deployment in all the EC2 instances will be done at the same time
- Blue-Green deployments - A replacement environment will be created and the triffic will be moved from the old to the new environment all at once
- Half At A Time
- In-place deployments - self explanatory
- Blue-Green deployments - self explanatory
- One At A Time
- In-place deployments - self explanatory
- Blue-Green deployments - self explanatory
- All At Once
-
Lambda Deployment Configuration
- Canary - Traffic is shifted to the new Lambda version in two increments. The percentage of traffic and the time interval between the increments are configurable
- Linear - Traffic is shifted to the new Lambda version in equal increments with equal number of minutes between each increment. The percentage of traffic in each increment and the time interval between each increment are configurable
- All at once - Traffic is shifted to the new Lambda version all at once
Directory Service
- Managed Microsoft Active Directory
- Corporate Active Directory can be integrated with AWS using AWS Directory Service AD Connector
- IAM Role can be assigned to the users or groups from the coprorate Active Directory once it is integrated with the VPC via the AWS Directory Service AD Connector
Shield
- All AWS customers benefit from the automatic protections of AWS Shield Standard, at no additional charge
- AWS Shield Standard with Amazon CloudFront and Amazon Route 53 provides comprehensive availability protection against all known infrastructure (Layer 3 and 4) attacks like SYN/UDP floods, reflection attacks, and others to support high availability of your applications on AWS
- AWS Shield Advanced provides additional detection and mitigation against large and sophisticated DDoS attacks
WAF
- AWS WAF helps protects your website from common attack techniques like SQL injection and Cross-Site Scripting (XSS)
- Rate based rule allows you to specify the number of web requests that are allowed by a client IP in a trailing, continuously updated, 5 minute period
- Rate based rule is designed to protect the app from use cases such web-layer DDoS attacks, brute force login attempts and bad bots
- The custmers can create rules to filter web traffic based on conditions that include IP addresses, HTTP headers and body, or custom URIs
- WAF can be used with both ALB & CloudFront
Macie
- Amazon Macie recognizes sensitive data such as personally identifiable information (PII) or intellectual property, and provides us with dashboards and alerts that give visibility into how this data is being accessed or moved
Inspector
- Amazon Inspector automatically assesses applications for vulnerabilities or deviations from best practices and produces a detailed list of security findings prioritized by level of severity
- Amazon Inspector includes a knowledge base of hundreds of rules mapped to common security best practices and vulnerability definitions such as remote root login being enabled, or vulnerable software versions installed
Lambda
- Lamda provides CloudWatch metrics for Invocations and Errors
- Lambda@Edge function can intercept the request and response at the CloudFront edge locations and modify the request and responses. Possible use cases include URL rewriting, modifying requests based on the client user-agent etc.
Elastic Beanstalk
- Deployment options
- All at once (deploy all in one go) –
- Fastest
- Downtime
- No additional instances
- Rolling
- Update a few instances at a time (bucket), and then move onto the next bucket once the first bucket is healthy
- No downtime
- Running at lower capacity
- Rolling with additional batches
- Spins up new instances to move the batch (so that the old application is still available)
- Running at full capacity
- Additional cost due to additional instances (bucket size) running during deployment
- Immutable
- Spins up new instances in a new ASG, deploys version to these instances, and then swaps all the instances when everything is healthy
- Running at full capacity
- Additional cost due to additional instances (bucket size) running during deployment
- Quick Rollback in case of failure - terminate the new ASG
- Blue Green deployment is not supported out of box. It could be achieved by Swap URL to a new environment or by doing Route 53 configurations (optionally with weighted routing)
- All at once (deploy all in one go) –
Config
- AWS Config is a fully managed service that provides you with an AWS resource inventory, configuration history, and configuration change notifications to enable security and governance
- If configurations do not match the configured compliance rules, it can trigger SNS notifications (Compliance monitoring)
Systems Manager
- Allows to take action on groups of AWS resources
- Provides a unified user interface so you can view operational data from multiple AWS services and allows you to automate operational tasks across your AWS resources
- Sub modules
- Session Manager - Browser based shell without the need to open inbound ports, maintain bastion hosts, and manage SSH keys
- Run Command - Provides a simple way of automating common administrative tasks across groups of instances such as registry edits, user management, and software and patch installations, replacing the need for bastion hosts, SSH, or remote PowerShell
- Patch Manager - helps you select and deploy operating system and software patches automatically across large groups of Amazon EC2 or on-premises instances
- Automation - allows you to safely automate common and repetitive IT operations and management tasks across AWS resources
- Configuration Compliance - lets you scan your managed instances for patch compliance and configuration inconsistencies
- Inventory - collects information about your instances and the software installed on them, helping you to understand your system configurations and installed applications
- State Manager - provides configuration management, which helps you maintain consistent configuration of your Amazon EC2 or on-premises instances. With Systems Manager, you can control configuration details such as server configurations, anti-virus definitions, firewall settings, and more. You can define configuration policies for your servers through the AWS Management Console or use existing scripts, PowerShell modules, or Ansible playbooks directly from GitHub or Amazon S3 buckets
- Parameter Store - provides secure, hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, and license codes as parameter values. You can store values as plain text or encrypted data. You can then reference values by using the unique name that you specified when you created the parameter
- Distributor - enables you to securely store and distribute software packages in your organization
- OpsCenter - provides a central location where operations engineers, IT professionals, and others can view, investigate, and resolve operational issues related to their environment
- Maintenance Windows - lets you schedule windows of time to run administrative and maintenance tasks across your instances in order to manage EC2 instances in a private subnet
Resource Access Manager
- AWS Resource Access Manager (AWS RAM) enables you to share your resources with any AWS account or organization in AWS Organizations. Customers who operate multiple accounts can create resources centrally and use AWS RAM to share them with all of their accounts to reduce operational overhead. AWS RAM is available at no additional charge
Secrets Manager
- You can encrypt secrets at rest to reduce the likelihood of unauthorized users viewing sensitive information
- To retrieve secrets, you simply replace secrets in plain text in your applications with code to pull in those secrets programmatically using the Secrets Manager APIs
- Secrets Manager can rotate secrets by invoking a lambda function. The code of the lambda function is predefined for AWS services. For other types of services, the user need to write the code for the Lammbda function
- Secrets are encrypted by provided KMS CMK or default account CMK
- Secrets Manager is similar to AWS Systems Manager's Parameter Store except the following additional features in Secrets Manager
- Secret rotation
- Random secret generation
- Secrets Manager is more expensive than AWS Systems Manager
- Parameter Store is now integrated with Secrets Manager so that you can retrieve Secrets Manager secrets when using other AWS services that already support references to Parameter Store parameters
Organizations
- AWS Organizations is an account management service that lets you consolidate multiple AWS accounts into an organization that you create and centrally manage. With AWS Organizations, you can create member accounts and invite existing accounts to join your organization. You can organize those accounts into groups and attach policy-based controls
CloudHSM
- AWS CloudHSM provides hardware security modules in the AWS Cloud. A hardware security module (HSM) is a computing device that processes cryptographic operations and provides secure storage for cryptographic keys
- Use cases
- Offload the SSL/TLS Processing for Web Servers
- Dedicated hardware - not shared with other AWS customers. It may be useful to meet certain compliance requirements
- Your KMS customer master keys (CMKs) never leave the CloudHSM instances, and all KMS operations that use those keys are only performed in your HSMs
- CloudHSM currently uses Luna SA HSMs from SafeNet
- You can implement CloudHSMs in multiple Availability Zones with replication between them to provide for high availability and storage resilience
KMS
- There are typically three scenarios for how data is encrypted using AWS KMS. Firstly, you can use KMS APIs directly to encrypt and decrypt data using your master keys stored in KMS. Secondly, you can choose to have AWS services encrypt your data using your master keys stored in KMS. In this case data is encrypted using data keys that are protected by your master keys in KMS. Thirdly, you can use the AWS Encryption SDK that is integrated with AWS KMS to perform encryption within your own applications, whether they operate in AWS or not.
- Envelope Encryption - While AWS KMS does support sending data less than 4 KB to be encrypted directly, envelope encryption can offer significant performance benefits. When you encrypt data directly with AWS KMS it must be transferred over the network. Envelope encryption reduces the network load since only the request and delivery of the much smaller data key go over the network. The data key is used locally in your application or encrypting AWS service, avoiding the need to send the entire block of data to KMS and suffer network latency
- CMK Rotation - The previous backing key is not deleted and stored perpetually for decryption of old data until the CMK logical entity itself is deleted
- Custom Key Store -
- The AWS KMS custom key store feature combines the controls provided by AWS CloudHSM with the integration and ease of use of AWS KMS
- You cannot import key material into your custom key store
- You cannot have KMS automatically rotate keys
- Customer managed CMK (Customer Master Key)
- Manual Key Rotation -
- manually create new keys
- map the new key to alias
- Use the alias in source code
- do not delete the old key as it will be used to decrypt old data
- Encryption Algorithm - AES with 256 bit key in GCM mode
- Generates a unique data key. This operation returns a plaintext copy of the data key and a copy that is encrypted under a customer master key (CMK) that you specify. You can use the plaintext key to encrypt your data outside of KMS and store the encrypted data key with the encrypted data
- Use KMS for compliance with various security schemes
Firewall Manager
- AWS Firewall Manager simplifies your AWS WAF administration and maintenance tasks across multiple accounts and resources. With AWS Firewall Manager, you set up your firewall rules just once. The service automatically applies your rules across your accounts and resources, even as you add new resources
GuardDuty
- Amazon GuardDuty is a continuous security monitoring service that analyzes and processes the following data sources: VPC Flow Logs, AWS CloudTrail event logs, and DNS logs. It uses threat intelligence feeds, such as lists of malicious IPs and domains, and machine learning to identify unexpected and potentially unauthorized and malicious activity within your AWS environment. This can include issues like escalations of privileges, uses of exposed credentials, or communication with malicious IPs, URLs, or domains. For example, GuardDuty can detect compromised EC2 instances serving malware or mining bitcoin. It also monitors AWS account access behavior for signs of compromise, such as unauthorized infrastructure deployments, like instances deployed in a region that has never been used, or unusual API calls, like a password policy change to reduce password strength
Single Sign-On
- AWS SSO is an AWS service that enables you to use your existing credentials from your Microsoft Active Directory to access your cloud-based applications, such as AWS accounts and business applications (Office 365, Salesforce, Box), by using single sign-on (SSO)
Trusted Advisor
- AWS Trusted Advisor is an online tool that provides you real time guidance to help you provision your resources following AWS best practices
- Trusted Advisor scans your AWS Infrastructure, compares it to AWS best practices in 5 categories and provides recommended actions
- Cost Optimization
- Performance
- Security
- Fault Tolerance
- Service Limits
Budgets
- AWS Budgets gives you the ability to set custom budgets that alert you when your costs or usage exceed (or are forecasted to exceed) your budgeted amount
- You can also use AWS Budgets to set reservation utilization or coverage targets and receive alerts when your utilization drops below the threshold you define
Backup
-
AWS Backup is a fully managed backup service that makes it easy to centralize and automate the back up of data across AWS services in the cloud as well as on premises using the AWS Storage Gateway. Using AWS Backup, you can centrally configure backup policies and monitor backup activity for AWS resources, such as Amazon EBS volumes, Amazon RDS databases, Amazon DynamoDB tables, Amazon EFS file systems, and AWS Storage Gateway volumes
-
Amazon Data Lifecycle Management (DLM) policies and backup plans created in AWS Backup work independently from each other and provide two ways to manage EBS snapshots. DLM provides a simple way to manage the lifecycle of EBS resources, such as volume snapshots. You should use DLM when you want to automate the creation, retention, and deletion of EBS snapshots. You should use AWS Backup to manage and monitor backups across the AWS services you use, including EBS volumes, from a single place
-
Amazon EFS backup functionality is built on AWS Backup
Scenario Question Tips
| Term | AWS Services |
|---|---|
| Streams | Amazon Kinesis |
| Disk for OS / boot volume | General Purpose SSD (gp2) |
| Disk for DB | Provisioned IOPS SSD (io1) |
| Big Data / Data Warehouse / Batch Job | Throughput Optimized HDD (st1) |
| Infrequently accessed | Cold HDD (sc1) |
| IOPS (no. of TPS) | SSD |
| Throughput (data volume per second) | HDD |
| Sequential Disk access (viz. batch job, data warehouse) | HDD |
| High performance storage across AZ | EFS |
| High performance within AZ | EBS |
| Blocking IP | NACL |
| Datawarehouse | Redshift |
| ETL | AWS Glue |
| Traffic within AWS / not over internet | VPC Endpoint |
| Connecting to S3 / DynamoDB without going through internet | Gateway VPC Endpoint |
| ASG with 20 EC2 instance per Region | AWS soft limit |
| Webapp across Regions | Amazon Route53 |
| Accessing service from a different region VPC | VPC Peering + Interface VPC Endpoint + PrivateLink + Network Load Balancer |
| Access over VPC Peering | Edge to edge and transitive routing not supported |
| DB cache / Session storage | ElastiCache |
| Scalable NoSQL DB | DynamoDB |
| DB Performance | Read Replica + ElastiCache |
| DB Disaster Recovery | Multi AZ |
| Greater Control on instances | EC2, EMR |
| Workflow | Amazon SWF |
| Serverless orchestration | AWS Step Functions |
| On-premise storage backup | Storage Gateway |
| Hybrid architecture | VPN + Customer Gateway + Direct Connect + VPC Gateway |
| Secrets | AWS Secrets Manager + AWS Systems Manager (Parameter Store) |
| Chef + Puppet | AWS OpsWorks |
| Sophisticated DDoS | Amazon Shield Advanced |
| Managing fleet of EC2 instances | AWS Systems Manager + Parameter Store + Session Manager + State Manager + Run Command + Inventory + OpsCenter + Maintenance Windows + Patch Manager + Automation + Distributor |
| Personally Identifiable Information (PII) | Amazon Macie |
| Synchronous DB replication | Multi AZ |
| Asynchronous DB replication | Read replicas |
| Data loss in EC2 | Instance Store |
| Db thread and process CPU utilization | Enhanced monitoring |
| CloudWatch custom metrics / Metrics not supported | CPU Utilization + Disk Utilization |
| Customer owned IP range | AWS advertises + use as Elastic IP |
| Services that by default encrypt | AWS CloudTrail + Amazon Glacier S3 |
| Lambda deployment | AWS CodeDeploy |
| Automatic load balancing, auto scaling etc. | AWS Elastic Beanstalk |
| KMS Custom Key Store | CloudHSM |
| Single tenant key access | CloudHSM |
| Services encrypted by default | Glacier, Storage Gateway, CloudTrail |
| AWS CLI Not able to connect | Make sure the region is correctly specified |
| Microsoft Active Directory | AWS SSO |
| AWS Best Practices | AWS Trusted Advisor |
| Log scan for security threats, udr of region never used before, password strength reduction | GuardDuty |
| WAF administration maintenance across accounts & resources | AWS Firewall Manager |
| Offload SSL/TLS processing from web servers | CloudHSM |
Serverless Services
- Compute
- AWS Lambda
- Lambda@Edge
- AWS Fargate
- Storage
- Amazon S3
- Amazon EFS
- Data Stores
- Amazon DynamoDB
- Amazon Aurora Serverless
- API Proxy
- Amazon API Gateway
- Application Integration
- Amazon SQS
- Amazon SNS
- AWS AppSync
- Amazon EventBridge
- Orchestration
- Amazon Step Functions
- Analytics
- Amazon Kinesis
- Amazon Athena
- Glue
Common Architecture
-
Accessing a custom service from a different region without going through internet -
- Use a inter-region VPC peering to connect the two provider VPC in different regions
- Use a Network Load Balancer in the secondary provider VPC to connect to the primary VPC service over VPC peering
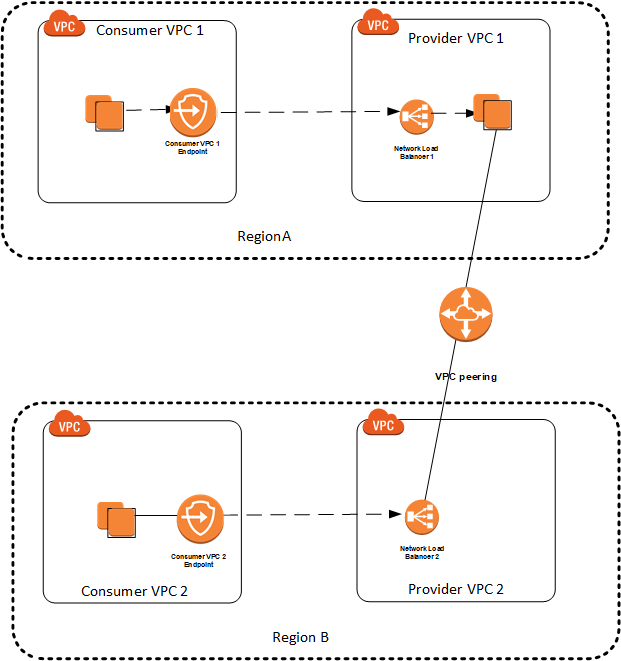
-
Creating a highly available webpage with VPC, ELB, ASG, VPC Endpoint, CloudFront, Systems Manager
-
Create a VPC in
na-east-1region with CIDR10.0.0.0/16 -
Create a public subnet (CIDR -
10.0.1.0/24&10.0.2.0/24) in each of the AZna-east-1aandna-east-1b. The public subnets will contain only the NAT Gateways and the Application Load Balancer.- Create a internet gateway
- Add a route in the main route table to the internet gateway for traffic to 0.0.0.0/0
-
Create a private subnet (CIDR -
10.0.3.0/24&10.0.4.0/24) in each of the AZna-east-1aandna-east-1b. The private subnets will contain the EC2 instances hosting the Apache web servers.- Create a NAT gateway in each of the two public subnets
- Associate an Elastic IP to each NAT gateway
- Create a custom route table for each private subnets
- Associate the appropriate private subnet with the custom route tables
- Add a route in each custom route table to the appropriate NAT gateway for traffic to 0.0.0.0/0
- Create a custom NACL
- Add both the private subnets to the custom NACL
- Refer to the NACL configuration below
-
Create a VPC endpoint for each of the services
com.amazonaws.region.ssmandcom.amazonaws.region.ec2messagesin the private subnets. These are required to enable the SSM (Systems Manager) agent in the EC2 instances to communicate with the Systems Manager over Amazon internal network -
Create a few security groups -
- For ALB - Allow inbound traffic to port
80from0.0.0.0/0 - For Auto Scaling Group - Allow inbound traffic to port
80from ALB security group - For VPC Endpoint - Allow inbound traffic for
HTTPS, port443from10.0.0.0/16
- For ALB - Allow inbound traffic to port
-
Create a few IAM roles -
- For EC2 - Add policy
AmazonSSMManagedInstanceCoreto allow the SSM agent communicate with the Systems Manager
- For EC2 - Add policy
-
Create a Target Group with port
80 -
Create an ALB
- Associate the appropriate security group created earlier
- Associate the target group created earlier
- Add a listener with port
80 - Associate the two public subnets created earlier
-
Create an ASG launch configuration
- Add the AMI Amazon Linux 2
- Associate the appropriate IAM role created earlier
- Associate appropriate security group created earlier
- Add user data to deploy Apache Httpd with an HTML. Refer to the user data given below
-
Create an Auto Scale Group
- Add the launch configuration created earlier
- Add the private subnets created earlier
- Add the target group created earlier
- Ensure that the Health Check Type is set to ELB
-
Create an S3 bucket to store images to be displayed in the web page
-
Create a CloudFront Distribution
- Add the ELB as default origin to serve HTML
- Add the S3 bucket as an origin to serve images
- Create an Origin Access Identity (OAI)
- Add a caching behavior for the S3 bucket with the OAI created earlier and update the S3 bucket policy to allow access to OAI
-
NACL Configuration
- Inbound Rules
Port Source Remarks HTTP (80) 10.0.0.0/16 HTTP traffic to come from ALB in the public subnets of the VPC Custom TCP (1024 - 65535) 0.0.0.0/0 Return traffic from the internet on the ephemeral ports - Outbound Rules
Port Destination Remarks HTTP (80) 0.0.0.0/0 HTTP traffic to the NAT gateway for internet download HTTPS (443) 0.0.0.0/0 HTTPS traffic to the NAT gateway for internet download & Systems Manager Custom TCP (1024 - 65535) 10.0.0.0/16 Return traffic to the ELB -
EC2 User Data -
#!/bin/bash yum update -y yum install httpd -y yum install awslogs -y service httpd start systemctl enable httpd chkconfig httpd on service awslogsd start systemctl enable awslogsd chkconfig awslogsd on cd /var/www/html echo "<html><h1>Hello AWS Study - Welcome To My Webpage</h1><body><img src='myimg.jpg'></body></html>" > index.html
-
