玩家评论可以为游戏的版本迭代提供重要参考,假如可以快速定位玩家的负面评价,则能够节约收集意见的时间成本。本项目通过文本挖掘方法,展示从数据采集到情感模型评价的全过程。
TAPTAP评论数据通过JSON返回,使用python中的Requests库非常容易就可以提取里面的内容。下面这幅图是Fiddler抓包时看到的数据:

建立断点txt文件,在因网络等原因中断时,重启程序,可以在断点处续爬,在中断时,已缓存的数据将保存至csv
def resume(self):
"""
爬取出错时,将出错url的‘from’参数值保存至txt中,中断爬虫。再次运行爬虫程序后,从此页继续爬取
:return: 本次续连url的‘from’参数值
"""
start_from = 0
if os.path.exists(STOP_POINT_FILE):
with open(STOP_POINT_FILE, 'r') as f:
start_from = int(f.readline())
return start_from文明爬虫,虽未发现反爬,但爬完每个页面后暂停0-2秒,减轻服务器负担
import random
import time
pause = random.uniform(0, 2)
time.sleep(pause)python中比较容易出现编码问题,在中文环境下更甚,评论里可能会有无法打印的字符,虽然不影响数据下载,但容易影响后续处理。先把数据进行gbk编码,丢弃无法识别的字符,再进行解码,最后将数据保存为utf-8格式,上面的问题就不存在啦~
review['author'] = r.get('author').get('name').encode('gbk', 'ignore').decode('gbk')其他信息:
每页10条数据,每个游戏的评论最多可爬990页,超过990页,TAPTAP拒绝访问。爬至页面上限需要约30分钟,可以去喝喝茶再回来(因为爬虫不是重点,没有进行速度方面的优化)。程序将采集到的数据存放至你指定路径的csv中。完整代码
这一步主要为数据可视化服务,使用pandas库可以很方便地进行数据清洗。
为了让pyecharts识别出时间标签,需要进行日期转换
import time
data['updated_time'] = data['updated_time'].apply(lambda x: time.strftime('%Y-%m-%d', time.localtime(x)))一些同学发评论比较喜欢用颜表情,但在爬虫过程中,gbk编码下无法全部显示,只能删掉意义不明的那另一半
import re
data['contents'] = data['contents'].apply(lambda x: re.sub('&[\w]+;', '', str(x)))
data['contents'] = data['contents'].apply(lambda x: re.sub('\(\s*\)', '', str(x)))实际情况下,玩家不太可能在未游玩的情况下评论(或者说这些评论意义不大),将游玩时间0替换为缺失是合理的,当进行相关维度的可视化,这些缺失值将不会被考虑
data['spent'] = data['spent'].replace(0, np.nan)其他信息: 其他清洗程序比较简单,见完整代码
从时间、设备、玩家印象维度可视化评论数据,这一步使用pyecharts库。pyecharts库是python生成Eharts图表的轮子,官方文档中就有丰富的图表实例。颜值高,上手容易,入股不亏。
采集数据的时间区间内,游戏分别于2019-10-17,2019-11-04,2020-01-01,2020-03-03进行版本更新,第三个版本满意度相对低,拉低了整体评价,1月30日之后,评分震荡区间上升,但未回到上年12月中旬前的水平:

小米和华为瓜分前15,可考虑重点关注这些机型的优化,或者和产商联合策划活动。

使用文本挖掘的预处理方法对TOP500支持度和热度达到0.5的评论进行处理,得到了玩家对这个游戏的关键评价,基本上是正面的,666。

- 查看数据分布情况
- 文本挖掘预处理
- 建立LSTM模型
- 模型评价


将4-5星的评价看作正面评价,3星及以下的评价看作负面评价,可以看到数据的分布极不均匀,是一个标准的偏斜类数据。直接对这样的数据进行建模,模型对负类的敏感度较低。评价这样的模型,需要在Precision(查准率)和Recall(召回率)之间去权衡。
模型的ver.1使用以上数据直接建模,计算混淆矩阵并计算查准率、召回率、F1值,三个评价指标值都非常低,模型检测负类的表现非常差。ver.1踩坑的完整代码
confuse_matrix(y_test, pred_y_test)
>>>[[ 148 245]
>>> [ 78 1362]]
>>>Precision = 0.38, Recall = 0.65 F1 = 0.48 模型的ver.2通过爬取同类型游戏评论的方式扩充数据集,在此基础上进行后续处理,下图可见,偏斜问题解决了。

1. 去除非中文字符: \u4e00-\u9fa5 是中文字符范围,通过正则表达式取反替换,即可去除非中文字符
import re
pattern = re.compile(r'[^\u4e00-\u9fa5]')
chinese_text = re.sub(pattern, '', text)2. 中文分词: 中文不像英文自然分隔,但我们希望得到每个词单独的含义,利用jieba库的cut操作可以轻松将中文字符拆分成词,它返回一个生成器,通过.join的方式串成字符串
import jieba
text_generater = jieba.cut(chinese_text)
result = ' '.join(text_generater)3. 去除停用词: 像“这”,“某”,“矣”这样的词,在文本分析中意义不大,通过加载停用词列表将其丢弃
# 载入停用词列表
with open(st_path, 'r') as f:
st = f.read()
st_list = st.splitlines()
word_list = chinese_text.split()
# 删除停用词
for stop_word in st_list:
word_list = [word for word in word_list if word != stop_word]4. 获取特征向量:训练词向量的方法有多种,常见的就有TF-IDF、Word2Vec、Glove等等,我们使用Word2Vec训练词向量模型。更一般的,可以下载预训练的词向量,或者对已训练的模型在新语料的基础上增量训练。(因为没有适合的模型,这里重新训练了,但是不建议)
import gensim
model = gensim.models.Word2Vec(text, size=100, min_count=1, window=5)
model.save(save_path)5. 划分训练集和测试集:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(np.array(X), np.array(Y), test_size=0.2, random_state=2)模型的建立思路:
- 更关注负类的预测表现:正类标注为0,负类标注为1
- 引入词向量:Embedding层
- 增强模型长期记忆能力:LSTM层
- 降低对权重的依赖:使用Dropout正则化层
- 只关注正负分类,而不关注具体评分:使用二分类输出层,Sigmoid层;使用二值交叉熵作为损失函数
- 梯度下降优化: 使用ADAM优化器
基于以上思考产生的模型结构:
# 数字可能根据调参发生变化,只关注结构即可
EmotionModel(
(embedding): Embedding(41057, 100)
(lstm1): LSTM(100, 100, batch_first=True)
(dropout1): Dropout(p=0.5, inplace=False)
(lstm2): LSTM(100, 100, batch_first=True)
(dropout2): Dropout(p=0.5, inplace=False)
(linear): Linear(in_features=5000, out_features=1, bias=True)
(sigmoid): Sigmoid()
)在GPU模式下训练模型,迭代50步的学习曲线:
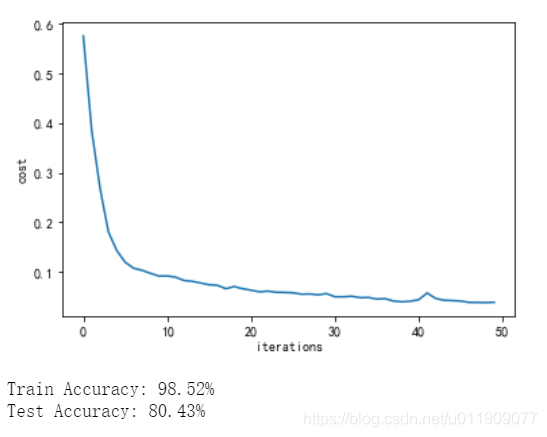
测试准确率比ver.1有明显提高,由于我们更关注负类准度,再查看其他评价指标。
confuse_matrix(y_test, pred_y_test)
>>>[[2527 455]
[ 618 1960]]
Precision = 0.85, Recall = 0.80 F1 = 0.82查准率 = 0.85,说明检测为负的有85%真实为负 召回率 = 0.80,说明80%的负类样本被成功检测 达到了具备实用价值的水平,可喜可贺
从类型接近的其他游戏评论中,随机选择数条新评论进行分类测试:
>>>
----
评论: 说实话这是一款非常不错的游戏!画质细腻,最重要的是可以切换横屏竖屏!惊喜啊!现在想玩到高质量的竖屏暗黑游戏太难啦!18元超值!
预测评分: 大于8
预测情感: 正向
----
评论: 先不说肝不肝,这个游戏的行走机制玩的真想让人砸手机,跑步和行走就是在走格子,见怪停顿然后你走一步怪走一步,受不了。
预测评分: 小于8
预测情感: 负向
----
评论: 这游戏玩不懂啊,感觉引导很奇怪,然后里面的机制也很奇怪,玩得一脸懵逼,啥跟啥都不知道...
预测评分: 小于8
预测情感: 负向
----
评论: 游戏是好游戏,代理太差了,毫无征兆说要开始测试,又随便找个理由跳票,既然没准备测试就不要放出消息啊,用这样的方法刷一波存在感有意思吗?
预测评分: 小于8
预测情感: 负向
----
评论: 今天刚玩,感觉很有趣,制作很良心。很多细节。感觉应该挺耐玩。剧情写得很有意思。很多可以探索的。感觉还蛮值得一玩的。
预测评分: 大于8
预测情感: 正向
----
评论: 这些游戏啊,进都不好进
预测评分: 小于8
预测情感: 负向从分类结果看,只要评论的立场比较明确,模型都能准确地给出判断。完整代码
- 目前的模型仅基于2.7W条评论构建,部分生僻词语出现的频率很低,词向量的构造上仍有很大的提升空间。可以通过采集更庞大的语料对词向量模型进行增量训练。
- 模型仅给出粗糙的正向、负向情感划分,可以构造更复杂的模型来检测更细粒度的情感。
- 未对参数作很多尝试,没有采用交叉验证,没有进行长时间训练,否则模型精度可能有进一步提高
感谢你读完这个长长的README,希望这个项目能对你有所启发~