
Hey There Cinephiles !, have you ever wasted time on deciding which movie to watch, and end up being watching no movie. NO MORE TIME WASTING ON DECIDING WHICH MOVIE TO WATCH COZ WE DO THAT FOR YOU HERE IN GO_SCREEN-CINEMATRIX
CineMatrix is one of its kind versatile, diversified movie recommending system which is based on not one or two but a combination five different recommending algorithms.CineMatrix is built on a solid foundation of advanced algorithms and methods like K-Nearest-Neighbours,term-frequency-inverse-document-frequency(tfidf),cosine similarity,SVD and many more other advanced techniques which gives at most most accurate recommendations almost instantly. With an interactive and user friendly UI/UX CineMatrix stands out from the rest of the other recommenders on the internet.
Here is a sneakpeak of our website:

-->Go_screen-CineMatrix<--

Also CheckOut our one of its kind Song Recommender JAXXTOPIA
 ( under construction, will be available shortly )
( under construction, will be available shortly )
A huge shoutout and thanks to Surya and Harsha for making this possible in short time, Surya I couldn’t have done it without you, Thanks for your hard work on this. And Harsha thanks man for the wonderful UI/UX you really have an eye for the design.
That's all for the website promotion, now for the nerds like me who are interested in how this thing works, here is brief summary of the backend:
A recommender system is a simple algorithm whose aim is to provide the most relevant information to a user by discovering patterns in a dataset. The algorithm rates the items and shows the user the items that they would rate highly. An example of recommendation in action is when you visit Amazon and you notice that some items are being recommended to you or when Netflix recommends certain movies to you. They are alsoused by Music streaming applications such as Spotify and Deezer to recommend music that you might like. During the last few decades, with the rise of Youtube, Amazon, Netflix and many other such web services, recommender systems have taken more and more place in our lives. From e-commerce (suggest to buyers articles that could interest them) to online advertisement (suggest to users the right contents, matching their preferences), recommender systems are today unavoidable in our daily online journeys.


-
Under content based system i used item based filtering, techniques i implemented are:
- TF-IDF (term frequency-inverse document frequency) is a statistical measure that evaluates how relevant a word is to a document in a collection of documents.
It works by increasing proportionally to the number of times a word appears in a document, but is offset by the number of documents that contain the word. So, words that are common in every document. Multiplying and these two(term frequency,inverse document frequency) numbers results in the TF-IDF score of a word in a document. The higher the score, the more relevant that word is in that particular document.
- CountVectorizer is a great tool provided by the scikit-learn library in Python. It is used to transform a given text into a vector on the basis of the frequency (count) of each word that occurs in the entire text.CountVectorizer creates a matrix in which each unique word is represented by a column of the matrix, and each text sample from the document is a row in the matrix. The value of each cell is nothing but the count of the word in that particular text sample.
- Cosine similarity measures the similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction. It is often used to measure document similarity in text analysis.the smaller the angle and the greater the match between vectors.
- That's all for the concept part, i first read the datset cleaned it for potential null values added couple of coloumns to make the workflow easy, then took the user input, searched for the matching result in the dataset using dfflib, dfflib searches for the best matching string and returns the value. Then i made two objects of classes TfidfVectorizer() and CountVectorizer(), then i used fit_transform() method for tfidf and count seperately to convert the text data into numerical data and finally used cosine similarity to find the best matching result i.e the words that are makign less angle with the word i given i.e the user movie title. Remaining is to enumerate through the similar movies that cosine similariity has found and print the top results after sorting similarity scores in descending order. The execution time and system resources consumed from this approach are very less compared to other techniques.
- i observed tfidf produces great results for some given inputs, and countvectorizer provied great results for other inputs. so i combined the results of both tfidf and count vectorizer to get atmost precise results, then i passed the obtained combined matrix to the find the cosine similarity.
The final output is result of both tfidf and count vectorizer, i selected the top 10 best results and displayed them. Thanks to the pre-processing i've done to the dataset it takes less than second to compute and display recommended movies.
- TF-IDF (term frequency-inverse document frequency) is a statistical measure that evaluates how relevant a word is to a document in a collection of documents.
It works by increasing proportionally to the number of times a word appears in a document, but is offset by the number of documents that contain the word. So, words that are common in every document. Multiplying and these two(term frequency,inverse document frequency) numbers results in the TF-IDF score of a word in a document. The higher the score, the more relevant that word is in that particular document.
-
The above model works great but i wanted to extend it further
- This time i decided to use linear kernel for calculating the cosine similarity, Linear Kernel is used when the data is Linearly separable, that is, it can be separated using a single Line. It is one of the most common kernels to be used. It is mostly used when there are a Large number of Features in a particular Data Set. One of the examples where there are a lot of features, is Text Classification, as each alphabet is a new feature. So we mostly use Linear Kernel in Text Classification.So here i passed the vectorized data obtained from the term-frequency-inverse-document-frequenct(tf-idf) vectorizer to cal the cosine similarity and store them.Then i take the user input movie, find its index enumerate through the vectors in cosine similarity find those vectors which least angles, sort them in ascending order and return the top 10 movies. A small change in the input data completely changes the output, working method of this and above model is same, the change is in pervious model i used cosine similarity to find similarity here i used linear kernel.
- This time i decided to use linear kernel for calculating the cosine similarity, Linear Kernel is used when the data is Linearly separable, that is, it can be separated using a single Line. It is one of the most common kernels to be used. It is mostly used when there are a Large number of Features in a particular Data Set. One of the examples where there are a lot of features, is Text Classification, as each alphabet is a new feature. So we mostly use Linear Kernel in Text Classification.So here i passed the vectorized data obtained from the term-frequency-inverse-document-frequenct(tf-idf) vectorizer to cal the cosine similarity and store them.Then i take the user input movie, find its index enumerate through the vectors in cosine similarity find those vectors which least angles, sort them in ascending order and return the top 10 movies. A small change in the input data completely changes the output, working method of this and above model is same, the change is in pervious model i used cosine similarity to find similarity here i used linear kernel.
-
Under collabrative based system i used content based filtering, techniques i implemented are:
- In User-based collaborative filtering, products are recommended to a user based on the fact that the products have been liked by users similar to the user. For example, if Sasi and Surya like the same movies and a new movie come out that Sasi like, then we can recommend that movie to Surya because Sasi and Surys seem to like the same movies.
- I used a movie lens dataset which is really huge and has a size of 250mb for a CSV file.
I loadaed the dataset stored it in a pandas df, movie lens dataset set contains multiple files each categorized seperately, so i grouped them based on the requirement it was such an headache.After clubbing and removing unneccessary data in rows, cols the final raw input is ready. Then to know what i'm dealing with i ran a few datavisualizing techniques and also built-in pandas methods such as .unique, .describe you get the point right. I decided on using movie ratings as a factor for deciding the recommended movies.i used these ratings to calculate the
correlation between the movies. Correlation is a statistical measure
that indicates the extent to which two or more variables fluctuate
together. Movies that have a high correlation coefficient are the movies
that are most similar to each other. In this case, i used the Pearson
correlation coefficient. This number will lie between -1 and 1. 1 indicates
a positive linear correlation while -1 indicates a negative correlation. 0
indicates no linear correlation. Therefore, movies with a zero correlation
are not similar at all.In order to do this i need create a pivot matrix with row as User_id and col as movie titles and values as ofcourse rating of that movie rated by the respective user.The final step is omputing the correlation between
user given movie ratings and the ratings of the rest of the movies in the
dataset.In order to compute the correlation between two dataframes we use
pandas corwith functionality. Corrwith computes the pairwise correlation
of rows or columns of two data frames objects. Let's use this functionality
to get the correlation between each movie's rating and the ratings of the
Air Force One movie.
- Last step is to order the correlation score in decsending order and return the top 10 movies with highest score, those movies will be the most similar ones. This model works fine but i wanted my recommender to be divesified so i also used other collabrative filtering methods which we will be discussing in the next section.
-
Under Memory-based collaborative filtering based system techniques i implemented are:
- In memory-based methods we don’t have a model that learns from the data to predict, but rather we form a pre-computed matrix of similarities that can be predictive.
- Step-1 is to select to filter data, in this approach i used the same dataset from movie lens, but the raw input is different from the previous model, here i selected a few feature coloumns such as genre, director, cast etc and removed remaining other unncessary cols in the dataset, then i transformed these metadata texts to vectors of features using Tf-idf transformer of scikit-learn package.Each movie will transform into a vector of the length ~ 23000. Since the data has become to huge and complex for computing i used SVD,truncated singular value decomposition (SVD) is a good tool to reduce dimensionality of matrix especially when applied on Tf-idf vectors.
- Then i used the rating df i created in the above collabrative filtering model, now in this model i have both content and collaborative matrices, all left to do is to find the similarity between user give movie and data in content and collaborative matrices. Cosine similarity is of huge help in finding the similarity.I calculated similarity score for user movie w.r.t content based matrix and score for user movie w.r.t collabrative based matrix , took and hybrid score of both. Sort the similarity scores in descending order and return the top-10 movies. This is so far the 'easy-peasy' explanantion for this model, the actual process in doing this is such a pain in ass 😭.
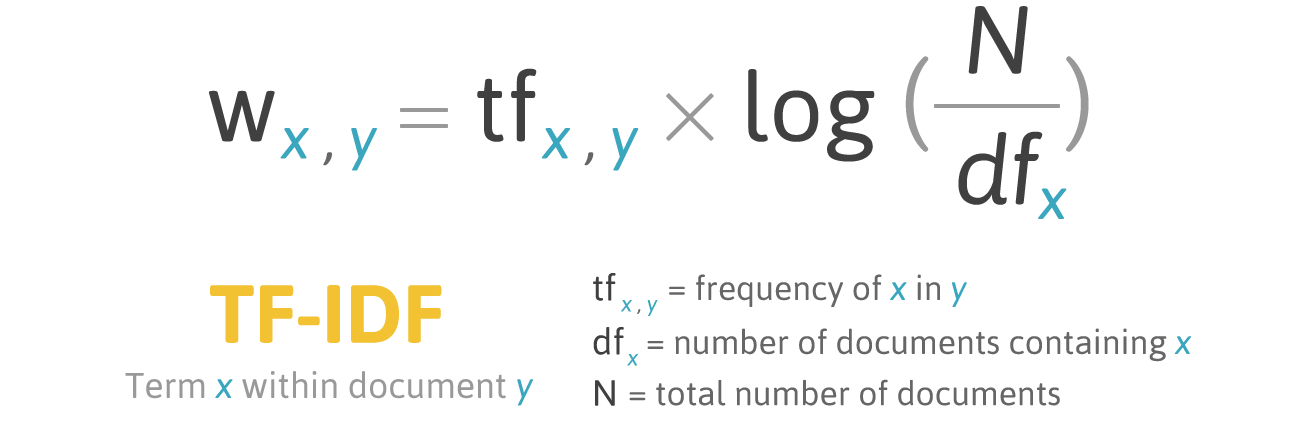
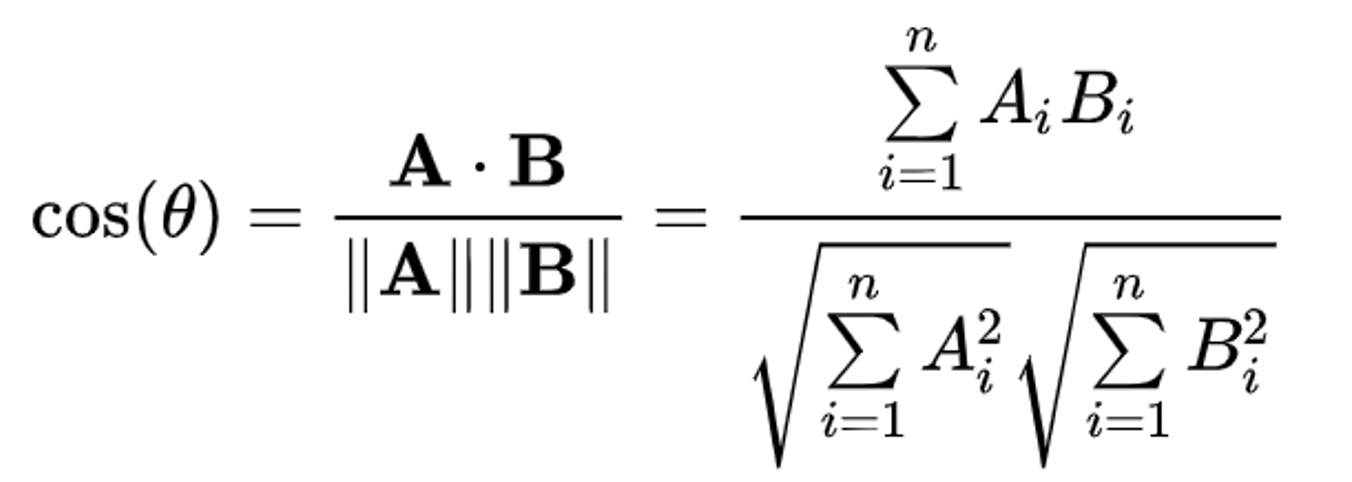
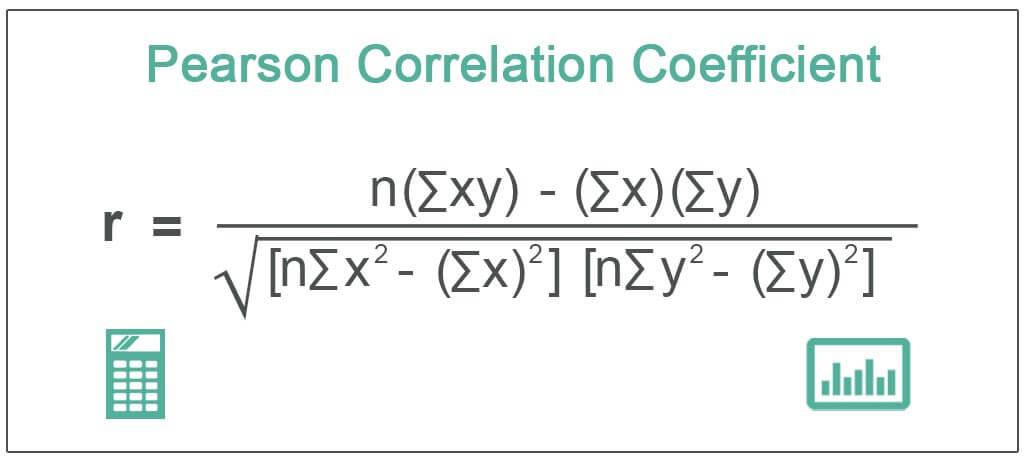
- KNN recommender is too complex and huge to write and explain, i'm too lazy to write, will upload an detailed documentation about KNN recommender sooner or later in this repo
- KNN recommender uses a huge computational power even after hours of preprocessing the data, it often causes website to crash too.
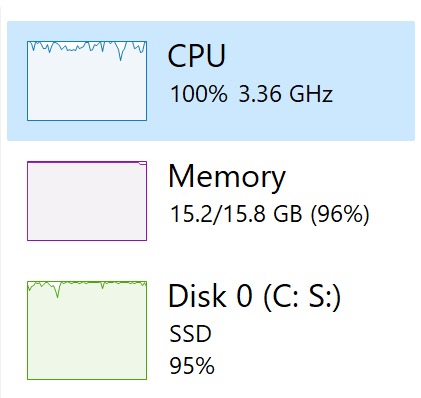 This was the moment i know i f'ed up.
This was the moment i know i f'ed up.
- so we decided to hop on to other methods too , one such method in our mind is to use matrix factorisation and support vector machines.
- HELP NEEDED FOR RECOMMNDER SYSTEM FOR MATRIX FACTORISATION MODEL FOR MODEL BASED COLLABRATIVE FILTERING,AS MATRIX FACTORISATION IS BETTER AT DEALING WITH SCALABILTY AND SPARSITY THAN THE PRESENT MODEL IN THIS SYSTEM.
- We are open to FORKS and PULL_REQUESTS.

