Course material related to databases, intended for in-training web developers.
We are using bits and pieces of the following electronic textbooks, available to registered students through the McGill Library.
 |
|
|---|---|
| Practical SQL | Data Analysis |
Book D |
Book H |
| Learning SQL | SQL Cookbook | SQL Pocket Guide |
Book L |
Book C |
Book P |
| MongoDB Fundamentals | Web Development with MongoDB and Node.js | Neo4J Graph Data Modelling |
Book M |
Book N |
Book J |
- Up to and including Part 3 of
H, from the very beginning of the book until the end of Chapter 15 - Chapter 2 of
L: Creating And Populating A Database - Chapter 2 of
D: Creating Your First Database And Table - Chapter 5 of
P: Creating, Updating, and Deleting
- Chapter 1 of
C: Retrieving Records - Chapter 2 of
C: Sorting Query Results - Chapter 3 of
L: Query Primer - Chapter 4 of
P: Querying Basics - Chapter 3 of
D: Beginning Data Exploration withSELECT
- Chapter 5 of
L: Querying Multiple Tables - Chapter 7 of
D: Joining Tables in a Relational Database - Chapter 3 of
C: Working With Multiple Tables - Chapter 9 of
P: Working With Multiple Tables And Queries
See the documentation of the tools linked below.
- Chapters 1 to 5 of
Mas well as Chapter 8 - Chapters 1 to 4 of
N
- Chapter 1 of
J
- Chapters 6 and 8 of
N
- Chapter 10 of
N
Tools are listed for the session during which we first use them. Some are used again in later sessions.
- Ubuntu & VirtualBox
- MySQL
- MySQL Tutorial: guides for installation and interfaces
- MariaDB
- PostgreSQL
- SQL Server
- SQL Server Ubuntu Quickstart
- Python; note that our early Colab examples use Python to connect to SQLite
- Create a Python webserver
- Flask, one of the many options for webdev in Python
- PHP
- PHP & MySQL
- Ruby on Rails
- RoR & PostgreSQL
- Java
- Java & MySQL
- Perl
- Perl & DBI
- Python Colab demo
- PostgreSQL demo to execute at SQL Online IDE
We do not use example codes in Session 6.
Sessions with no concepts listed do not introduce new concepts, but rather new tools for the concepts we have encountered before.
-
program-data independence
-
database: achieve consistency, provide structure, avoid redundancy, limit unnecessary sharing, make data usable and accessible (define the scope; one or many?)
-
sharing: purposeful replication of data in two or more places
-
redundancy: unnecessary replication of data in two or more places
-
database management system (DBMS): structuring, validation, recovery, monitoring, security, mapping of schemas
-
global schema: what data is available, how is it stored and accessed
-
internal schema: hardware-level implementation of the storage structure
-
conceptual schema: data description (content and constraints)
-
external schema: what an application sees when it accesses a database (format, visibility)
-
(data) model: a description of a database that is not DBMS-specific; needs to map to a schema upon implementation
-
relational modelling: the design of a model in terms identifying attributes and grouping them into tables
-
entity-relationship modelling (ER): identifying entities (conceptually related groups of attributes) and their relationships (associations between the attributes of the entities); see Figure 8.5 of
Hfor an example -
type of entity: much like class in OOP
-
occurence of type: much like an (object) instance in OOP
-
degree of relationship: multiplicities at the end points,
1:1,1:many,many:many, see Figure 9.2 ofHfor an example) -
multiplicity notation:
1,N,M,1..1,0..1,0..*,1..*(see Figure 9.5 ofHfor an example) -
recursive relationship: a relationship from an entity to itself
-
decomposition of
many:many: create an intermediary entity to associate the sides (see Figure 10.2 ofHfor an example) -
connection trap: a part of an ER diagram that allows for an interpretation error (such as a fan trap or a chasm trap; see Chapter 11 of
Hfor examples and definitions) -
table: a definition of what columns (attributes) the table stores for each row (record) stored in that table
-
attribute: a property of a record that holds a value of a specified format (data type)
-
normalized table: each attribute only holds a single value (rows are repeated to accomodate multiple values; for example, products in a shopping basket)
-
fully normalized table: a normalized table that contains no redundant data
-
record: a unique combination of attribute values within a table
-
null: a value that is assigned to an attribute that is unknown or undefined in some way
-
determinant: attribute X is determined by (depends on) attribute Y is duplicate values of X are always associated to one same value of Y
-
determinancy: a diagram that places an arrow from Y to X if and only if Y determines X
-
composite determinancy: a combination of attributes determines another attribute (draw boxes to group the codeterinants in the diagram)
-
transitive determinancy: Z determines Y and Y determines X, so Z transitively determines X (draw a longer arrow from Z to X to show this in a diagram, if so desired)
-
superfluous: an attribute X is only determined by Y so that knowing Y already narrows down the value of X
-
(primary) key: a unique identifier for a record; in a dependency diagram, it is the "root" of the dependency tree; if there are several candidates, one is assigned explicitly as the key of the table
-
table definition:
tableName (attributeName, secondAttributeName, ...)(some like to underline or otherwise highlight the attribute that serves as the primary key)
- conjuntion: two conditions must be both true for the combination to be true (
and) - disjunction: two conditions must both be false for the combination to be false (
or) - concatenate: combine two strings into a single one:
helloconcatenated withworldishelloworld - ascending: increasing order, from lower to higher values
- descending: decreasing order, from higher to lower values
- (inner) join: link rows of one table into rows of another table in a specific manner, usually by matching keys in one to keys in another
- left join: keep all rows of the second table that match a row in the first table (those of the first one are always kept)
- right join: keep all rows of the first table that match a row in the second table (those of the second one are always kept)
- (full) outer join: keep the rows from both, leaving the head or the tail blank if there was no match
- cross join: in the result, include each row of the first table combined with each row of the second table, repeating to include all combinations of the two; in math, this is called a Cartesian product
These focus on tools rather than concepts.
- JSON: JavaScript Object Notation (a text file describing structured data)
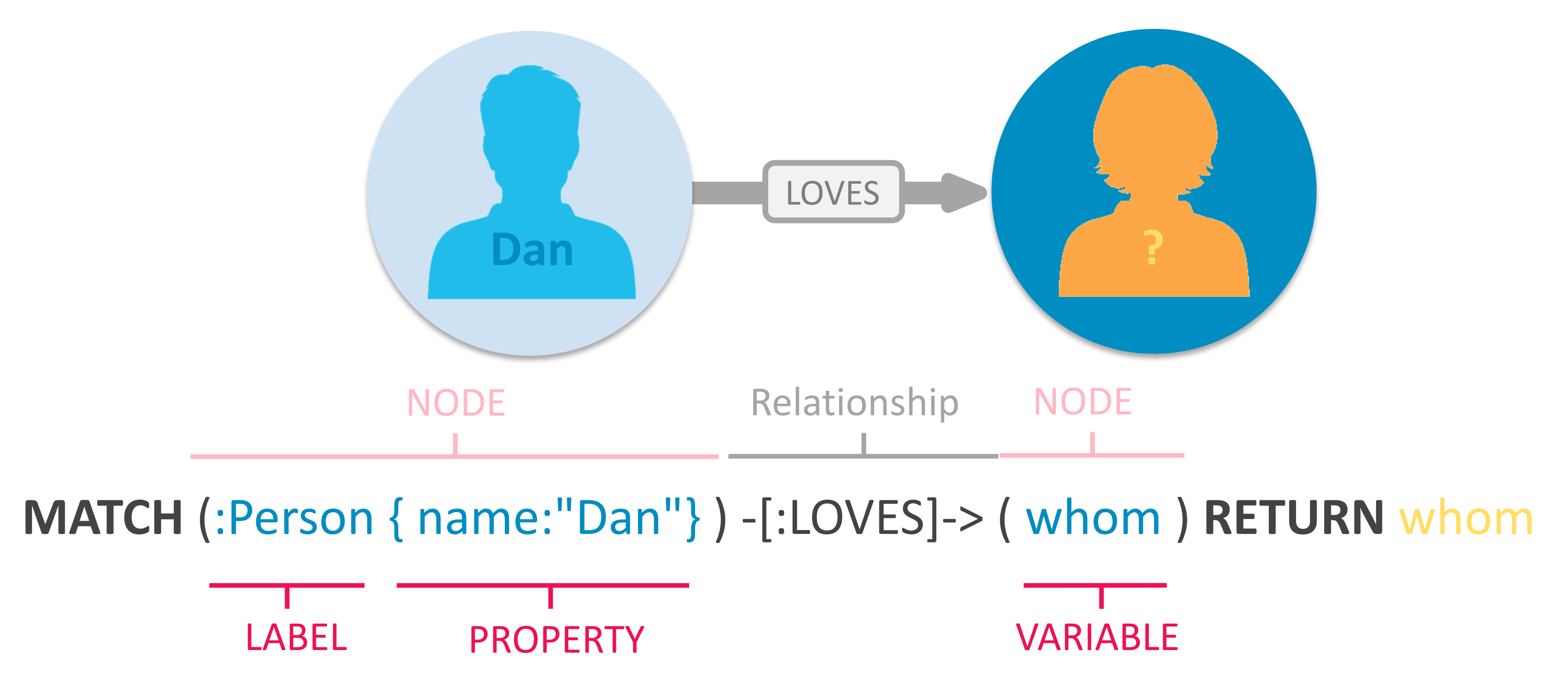
- graph: a set of nodes (vertices) that may have connections (edges) between them
- property graph: nodes and edges with associated properties
The participation journal and the weekly reflections are detailed at Overleaf in addition to being incorporated in myCourses LMS on which the classes are held. All submissions must be done through the LMS, respecting the deadlines as shown there.