The Qualcomm® AI Hub Models are a collection of state-of-the-art machine learning models optimized for performance (latency, memory etc.) and ready to deploy on Qualcomm® devices.
- Explore models optimized for on-device deployment of vision, speech, text, and genenrative AI.
- View open-source recipes to quantize, optimize, and deploy these models on-device.
- Browse through performance metrics captured for these models on several devices.
- Access the models through Hugging Face.
- Sign up to run these models on hosted Qualcomm® devices.
Supported runtimes
Supported operating systems:
- Android 11+
Supported compute units
- CPU, GPU, NPU (includes Hexagon DSP, HTP)
Supported precision
- Floating Points: FP16
- Integer: INT8 (8-bit weight and activation on select models), INT4 (4-bit weight, 16-bit activation on select models)
Supported chipsets
- Snapdragon 845, Snapdragon 855/855+, Snapdragon 865/865+, Snapdragon 888/888+
- Snapdragon 8 Gen 1, Snapdragon 8 Gen 2, Snapdragon 8 Gen 3
Select supported devices
- Samsung Galaxy S21 Series, Galaxy S22 Series, Galaxy S23 Series, Galaxy S24 Series
- Xiaomi 12, 13
- Google Pixel 3, 4, 5
and many more.
We currently support Python >=3.8 and <= 3.10. We recommend using a Python virtual environment (miniconda or virtualenv).
You can setup a virtualenv using:
python -m venv qai_hub_models_env && source qai_hub_models_env/bin/activate
Once the environment is setup, you can install the base package using:
pip install qai_hub_modelsSome models (e.g. YOLOv7) require additional dependencies. You can install those dependencies automatically using:
pip install "qai_hub_models[yolov7]"Each model comes with the following set of CLI demos:
- Locally runnable PyTorch based CLI demo to validate the model off device.
- On-device CLI demo that produces a model ready for on-device deployment and runs the model on a hosted Qualcomm® device (needs sign up).
All the models produced by these demos are freely available on Hugging Face or through our website. See the individual model readme files (e.g. YOLOv7) for more details.
All models contain CLI demos that run the model in PyTorch locally with sample input. Demos are optimized for code clarity rather than latency, and run exclusively in PyTorch. Optimal model latency can be achieved with model export via Qualcomm® AI Hub.
python -m qai_hub_models.models.yolov7.demoFor additional details on how to use the demo CLI, use the --help option
python -m qai_hub_models.models.yolov7.demo --helpSee the model directory below to explore all other models.
Note that most ML use cases require some pre and post-processing that are not
part of the model itself. A python reference implementation of this is provided
for each model in app.py. Apps load & pre-process model input, run model
inference, and post-process model output before returning it to you.
Here is an example of how the PyTorch CLI works for YOLOv7:
from PIL import Image
from qai_hub_models.models.yolov7 import Model as YOLOv7Model
from qai_hub_models.models.yolov7 import App as YOLOv7App
from qai_hub_models.utils.asset_loaders import load_image
from qai_hub_models.models.yolov7.demo import IMAGE_ADDRESS
# Load pre-trained model
torch_model = YOLOv7Model.from_pretrained()
# Load a simple PyTorch based application
app = YOLOv7App(torch_model)
image = load_image(IMAGE_ADDRESS, "yolov7")
# Perform prediction on a sample image
pred_image = app.predict(image)[0]
Image.fromarray(pred_image).show()Some models contain CLI demos that run the model on a hosted Qualcomm® device using Qualcomm® AI Hub.
To run the model on a hosted device, sign up for access to Qualcomm® AI Hub. Sign-in to Qualcomm® AI Hub with your Qualcomm® ID. Once signed in navigate to Account -> Settings -> API Token.
With this API token, you can configure your client to run models on the cloud hosted devices.
qai-hub configure --api_token API_TOKENNavigate to docs for more information.
The on-device CLI demo performs the following:
- Exports the model for on-device execution.
- Profiles the model on-device on a cloud hosted Qualcomm® device.
- Runs the model on-device on a cloud hosted Qualcomm® device and compares accuracy between a local CPU based PyTorch run and the on-device run.
- Downloads models (and other required assets) that can be deployed on-device in an Android application.
python -m qai_hub_models.models.yolov7.exportMany models may have initialization parameters that allow loading custom
weights and checkpoints. See --help for more details
python -m qai_hub_models.models.yolov7.export --helpAs described above, the script above compiles, optimizes, and runs the model on a cloud hosted Qualcomm® device. The demo uses Qualcomm® AI Hub's Python APIs.
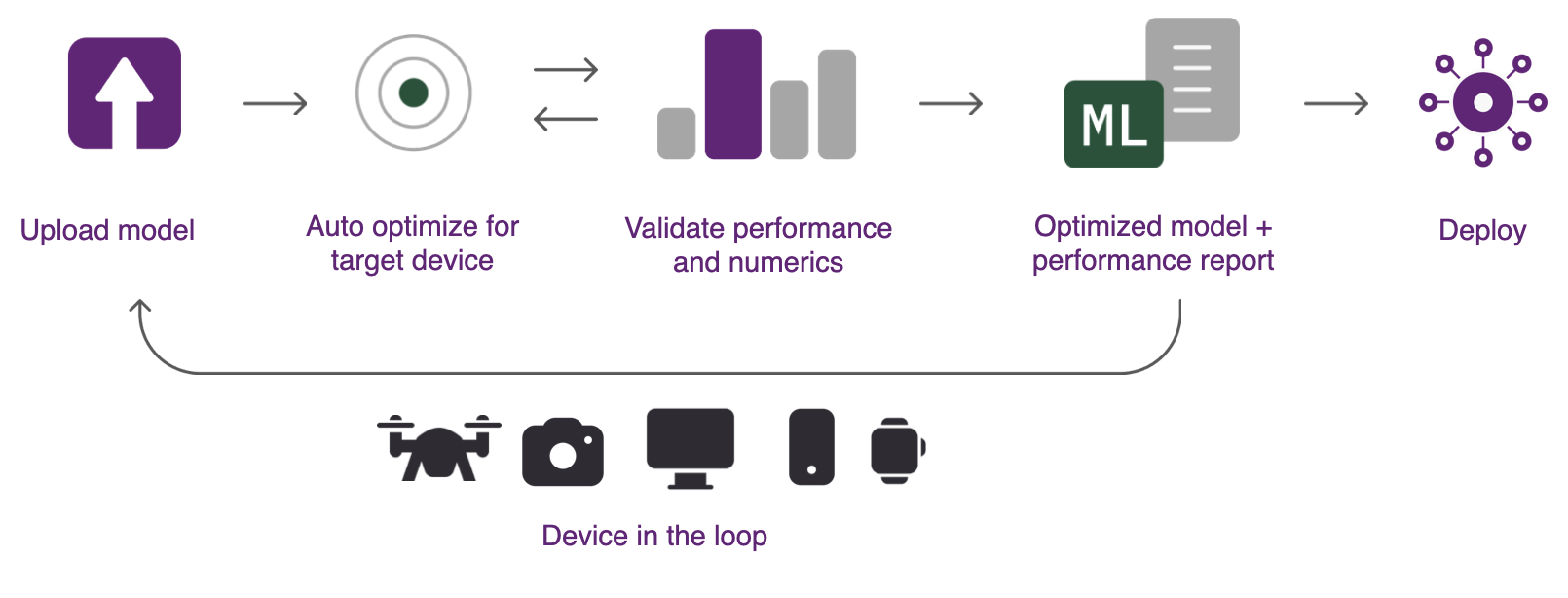
Here is a simplified example of code that can be used to run the entire model on a cloud hosted device:
from typing import Tuple
import torch
import qai_hub as hub
from qai_hub_models.models.yolov7 import Model as YOLOv7Model
# Load YOLOv7 in PyTorch
torch_model = YOLOv7Model.from_pretrained()
torch_model.eval()
# Trace the PyTorch model using one data point of provided sample inputs to
# torch tensor to trace the model.
example_input = [torch.tensor(data[0]) for name, data in torch_model.sample_inputs().items()]
pt_model = torch.jit.trace(torch_model, example_input)
# Select a device
device = hub.Device("Samsung Galaxy S23")
# Compile model for a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on a cloud hosted device
target_model = compile_job.get_target_model()
# Profile the previously compiled model on a cloud hosted device
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
# Perform on-device inference on a cloud hosted device
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
# Returns the output as dict{name: numpy}
on_device_output = inference_job.download_output_data()You can clone the repository using:
git clone https://github.com/quic/ai-hub-models/blob/main
cd main
pip install -e .Install additional dependencies to prepare a model before using the following:
cd main
pip install -e ".[yolov7]"All models have accuracy and end-to-end tests when applicable. These tests as designed to be run locally and verify that the PyTorch code produces correct results. To run the tests for a model:
python -m pytest --pyargs qai_hub_models.models.yolov7.testFor any issues, please contact us at ai-hub-support@qti.qualcomm.com.
| Model | README | Torch App | Device Export | CLI Demo |
|---|---|---|---|---|
| Speech Recognition | ||||
| Whisper-Base | qai_hub_models.models.whisper_asr | ✔️ | ✔️ | ✔️ |
| HuggingFace-WavLM-Base-Plus | qai_hub_models.models.huggingface_wavlm_base_plus | ✔️ | ✔️ | ✔️ |
| Audio Enhancement | ||||
| Facebook-Denoiser | qai_hub_models.models.facebook_denoiser | ✔️ | ✔️ | ✔️ |
| Model | README | Torch App | Device Export | CLI Demo |
|---|---|---|---|---|
| TrOCR | qai_hub_models.models.trocr | ✔️ | ✔️ | ✔️ |
| OpenAI-Clip | qai_hub_models.models.openai_clip | ✔️ | ✔️ | ✔️ |
| Model | README | Torch App | Device Export | CLI Demo |
|---|---|---|---|---|
| Image Generation | ||||
| Stable-Diffusion | qai_hub_models.models.stable_diffusion_quantized | ✔️ | ✔️ | ✔️ |
| ControlNet | qai_hub_models.models.controlnet_quantized | ✔️ | ✔️ | ✔️ |
| Text Generation | ||||
| Llama-v2-7B-Chat | qai_hub_models.models.llama_v2_7b_chat_quantized | ✔️ | ✔️ | ✔️ |
| Baichuan-7B | qai_hub_models.models.baichuan_7b_quantized | ✔️ | ✔️ | ✔️ |