This repository contains the code (in PyTorch) for "Pyramid Stereo Matching Network" paper (CVPR 2018) by Jia-Ren Chang and Yong-Sheng Chen.
Recent work has shown that depth estimation from a stereo pair of images can be formulated as a supervised learning task to be resolved with convolutional neural networks (CNNs). However, current architectures rely on patch-based Siamese networks, lacking the means to exploit context information for finding correspondence in illposed regions. To tackle this problem, we propose PSMNet, a pyramid stereo matching network consisting of two main modules: spatial pyramid pooling and 3D CNN. The spatial pyramid pooling module takes advantage of the capacity of global context information by aggregating context in different scales and locations to form a cost volume. The 3D CNN learns to regularize cost volume using stacked multiple hourglass networks in conjunction with intermediate supervision.

As an example, use the following command to train a PSMNet on Scene Flow
python main.py --maxdisp 192 \
--model stackhourglass \
--datapath (your scene flow data folder)\
--epochs 10 \
--loadmodel (optional)\
--savemodel (path for saving model)
As another example, use the following command to finetune a PSMNet on KITTI 2015
python finetune.py --maxdisp 192 \
--model stackhourglass \
--datatype 2015 \
--datapath (KITTI 2015 training data folder) \
--epochs 300 \
--loadmodel (pretrained PSMNet) \
--savemodel (path for saving model)
You can alse see those example in run.sh
Use the following command to evaluate the trained PSMNet on KITTI 2015 test data
python submission.py --maxdisp 192 \
--model stackhourglass \
--KITTI 2015 \
--datapath (KITTI 2015 test data folder) \
--loadmodel (finetuned PSMNet) \

| Method | D1-all (All) | D1-all (Noc) | Runtime (s) |
|---|---|---|---|
| PSMNet | 2.32 % | 2.14 % | 0.41 |
| iResNet-i2 | 2.44 % | 2.19 % | 0.12 |
| GC-Net | 2.87 % | 2.61 % | 0.90 |
| MC-CNN | 3.89 % | 3.33 % | 67 |



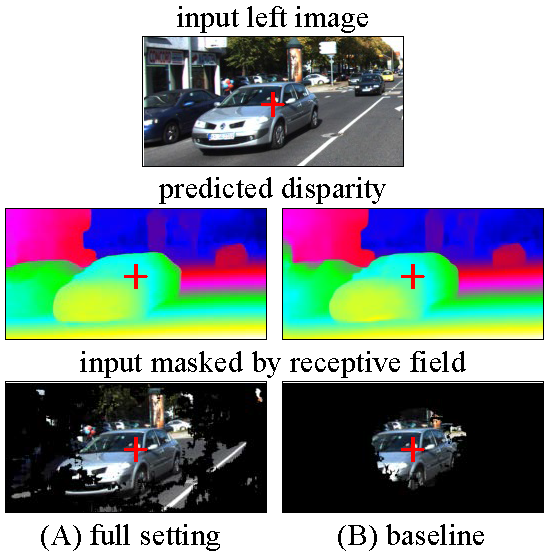
We visualize the receptive fields of different settings of PSMNet, full setting and baseline.
Full setting: dilated conv, SPP, stacked hourglass
Baseline: no dilated conv, no SPP, no stacked hourglass
The receptive fields were calculated for the pixel at image center, indicated by the red cross.
We are working on the implementation on caffe. Any discussions or concerns are welcomed!