EIGH very very slow --> suggesting an easy fix
danielhanchen opened this issue · 7 comments
This post extends #7339, where @yaroslavvb noticed first that EIGH was surprisingly slow in Scipy vs Numpy.
Anyways first post on Scipy for me!!! Hi all!
I checked Scipy's code on EIGH and how it was implemented. Everything was fine, HOWEVER, you need to add 2 extra lines (literally) of code to make it approx 2-4 times faster than the old Scipy version, and even faster than Numpy's.
Scipy uses:
- SYEVR if B = None and eigvals = None [Very slow non divide n conquer]
- SYEVD if B = not None and eigvals = None [Very Fasssttt divide n conquer]
- SYEVX if B = not None and eigvals = not None. [Slow as well]
There is a slight problem. It should be:
- SYEVD if B = None (identity) and eigvals = None [Very Fasssttt divide n conquer]
- SYEVD if B = not None and eigvals = None [Very Fasssttt divide n conquer]
- SYEVX else
In other words, I propose that Scipy scraps SYEVR completely, and replaces everything with SYEVD. You can keep SYEVR for RAM constraining machines.
An easy fix I tried is:
scipy.linalg.eigh(XTX, b = np.eye(len(XTX), dtype = X.dtype), turbo = True, check_finite = False)Which performs at most 3-4 times faster than doing this:
scipy.linalg.eigh(XTX, b = None, turbo = True, check_finite = False)Note, I also tried:
scipy.linalg.eigh(XTX, b = np.eye(len(XTX), dtype = np.int8), turbo = True, check_finite = False)Which is even slower (meaning you must make identity same dtype as XTX
So, a simple fix in Scipy would be simply:
def eigh(X, b.....):
if b is None:
b = np.eye(len(X), dtype = X.dtype)
....In terms of timing,
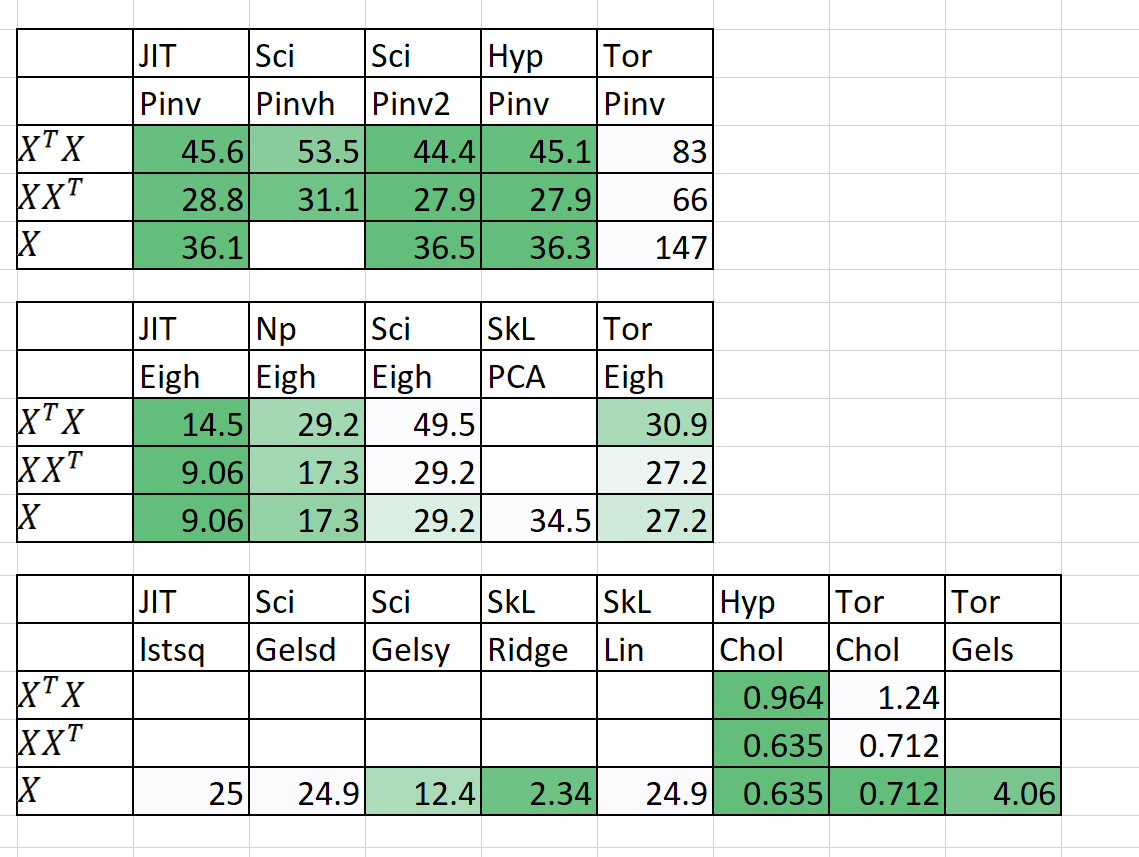
Also, this post flows on from pytorch/pytorch#11174, where I reported that PyTorch's SVD and GELS was slow and unstable.
I'm guessing your matrix size is a perfect power of 2. See section 2.5 in http://www.netlib.org/lapack/lawnspdf/lawn182.pdf
This speed issue is (unfortunately) input dependent and there are cases where the speed can be reversed. Hence we can't make a single choice for eigenvalue solvers.
Also for subset computations we need ?syevr hence it is going to be around.
@ilayn Thanks for the reply!
Nah, I tested multiple matrices including N = 200 (not power of 2), and N = 6,000 even (not power of 2). In all cases, Numpy was twice as fast.
All I know is that Scipy's EIGH is using SYEVR for B = identity. I think it should be SYEVD for B = identity, just like how Numpy does it
Then I don't understand the argument. Numpy already has a speed advantage with ufunc implementation. Can you make a simple test such that we can copy/paste and see what kind of matrices and speed differences we are talking about?
Also are you using MKL or OpenBLAS? It can make a difference. And so can the number of threads you allocate (e.g., OPENBLAS_NUM_THREADS or OMP_NUM_THREADS). If it's easy to open a PR to add a lapack_driver argument that might be a good way to allow people to test. If it's better in most/all cases, we could eventually have lapack_driver='auto' to do what you propose, and people who really want a specific solver could pass the name directly. We did this with linalg.svd recently.
FWIW I have noticed a few places where OpenBLAS is much slower than MKL in code I use, such as linalg.inv and solving a linear system with a symmetric matrix) so it can be helpful to users to have more solver options exposed where possible to work around such problems until the upstream libraries improve.
import numpy as np
from sklearn.datasets import make_regression
import scipy.linalg as linalg
n = 10000
p = 2000
X, y = make_regression(random_state = 0, n_samples = n, n_features = p, n_informative = int(p/3))
X = X.astype(np.float32, copy = False)
y = y.astype(np.float32, copy = False)
XTX = X.T @ X
def eighFix(X):
return linalg.eigh(X, b = np.eye(len(X), dtype = X.dtype), turbo = True,check_finite = False)
def eighOld(X):
return linalg.eigh(X, check_finite = False, turbo = True)
%time eighOld(XTX)
%time eighFix(XTX)@larsoner Numpy & Scipy is using MKL
I can confirm on one machine with MKL ("Fix" mode comes second):
CPU times: user 14.3 s, sys: 175 ms, total: 14.5 s
Wall time: 13.7 s
CPU times: user 3.46 s, sys: 129 ms, total: 3.59 s
Wall time: 3.32 s
I will try MKL and OpenBLAS on another machine tomorrow.
The eigenvalues were np.allclose but to get the np.abs(eigvec) to be np.allclose I had to use atol=1e-3, which had me worried for a moment. However, np.allclose(np.dot(eigvec * eig, eigvec.T), XTX, atol=1e-2) seems to be the order of magnitude atol that passes for both results, so they seem to have at least the same order of magnitude accuracy from one small test. (The same held true for np.allclose(XTX @ eigvec - eigvec @ np.diag(eig), np.zeros(XTX.shape), atol=1e-2)). So I think accuracy here is probably / possibly fine. So I'm leaning +1 on having the option of using the other solver, and probably making it the default, even if currently you can implicitly trigger using it by passing np.eye to the solver.
My API proposal would be to have lapack_driver='auto' which will follow the "It should be:" plan above, and allow explicit 'syevr', 'syevd', 'syevx' options (sanity checked for usability based on input values). This is assuming that you agree, have tested, and/or can show that this new set of options should not negatively impact people's code in terms of precision (and perhaps secondarily, speed).
I have OpenBLAS and I also see some speed-up indeed (not that dramatic though)
Wall time: 3.26 s
Wall time: 1.62 s
If we call the underlying routines
In [1]: %timeit la.lapack.ssyevd(XTX)
1.28 s ± 11.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [2]: %timeit la.lapack.ssyevr(XTX)
3.19 s ± 26.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [3]: I = np.eye(XTX.shape[0], dtype=np.float32)
In [4]: %timeit la.lapack.ssygvd(XTX, I)
1.55 s ± 12 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Hence ?syevd is faster. Note that we use ?syGvd if B is not None (Generalized eigenValue) hence it is not just EVR vs EVD comparison. But in MKL we need to test with much higher lwork values than the defaults. Especially since EVR lwork is n**2 dependent.
In my opinion, the turbo keyword and lack of lwork computations and lack of interval computations (#6510, #8205, #8713 ) grants a rework of this public function API. I started to work on this some time ago https://github.com/ilayn/scipy/tree/evr_lwork but then got distracted. We can revisit them.