The topics of congressional bills would have a fair indication of what our congressional leaders are talking about and how consistent our leaders have been in living up to their campaigns. These topics were derived using machine learning and later used as features to predict potential outcomes of bills. The results were highly intriguing and will be implemented in future work.
Web scraped bill text from congress.gov and retrieved bill and votes data using the Sunlight Foundation API. Bill and vote information dates back to congress 103.
Applied NNMF to derive latent topics in bill text and examine any distinguishable characteristics between time periods in congress. The cosine distance between different topics (H) and within topics (W/tfidf) was explored.
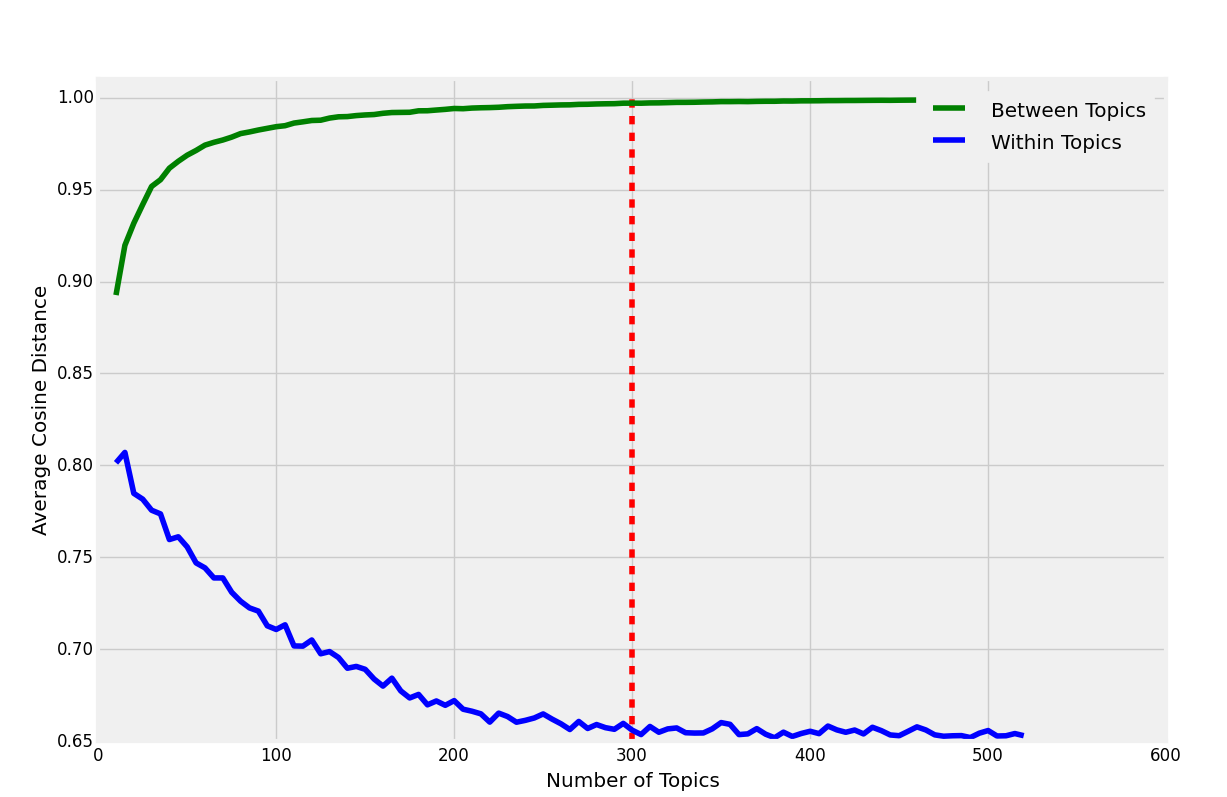
Examining the graph above it can be seen that the cosine distance between topics increases and levels off. The cosine distance within topics decreases and also levels off. A value of 300 topics was chosen to achieve a good balance between both metrics.
Word clouds were developed from the latent topics as a representation of how the algorithm is performing with 300 topics. An example is displayed below.

After deriving the topics with NNMF, the prevalence of a particular topic can be examined over time by grouping by the congress year. The prevalence of the internet is displayed below.
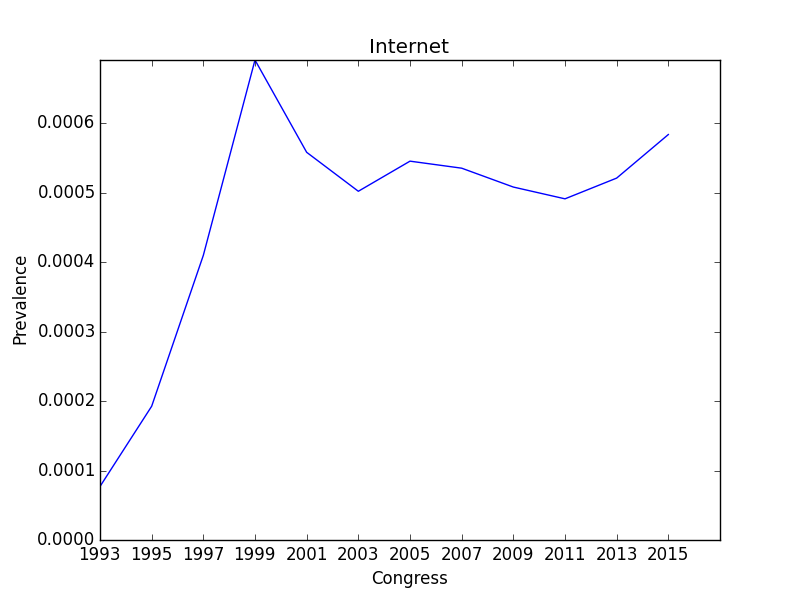
Here, the prevalence of "internet" coincides with what could have been expected. Essentially this displays how the internet importance has risen and become a relevant aspect of people's lives.
With the hypothesis that there is a high level of polarization in government and that these characteristics are prophetic, applied gradient boosted and random forest ensemble methods to predict the percent of yes votes for a given party.
Multiple models were explored, but ultimately the gradient boosted regression ensemble method was chosen for the best results. A plot of the residuals for the Democratic party is displayed below.
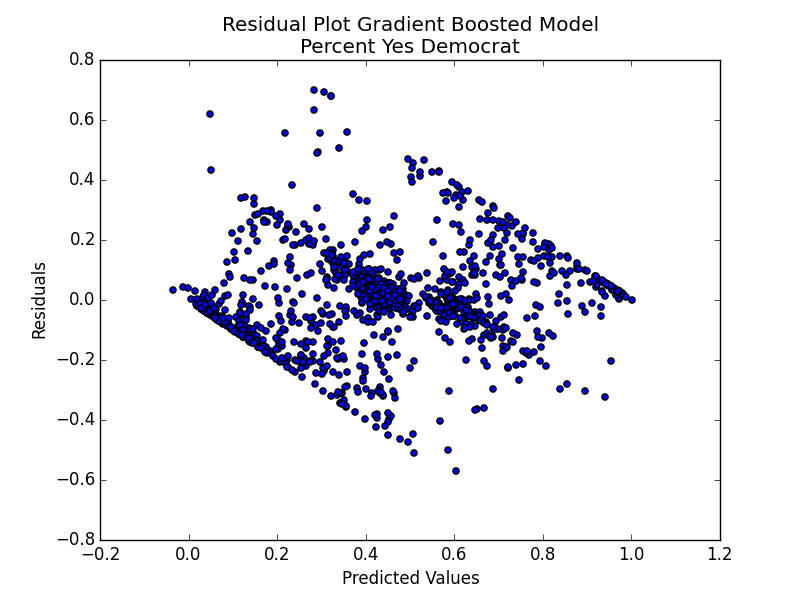
This is not an ideal scenario for a residual plot. However, it does have some indication about the polarization in government. The algorithm is much better at predicting when there is a dominant party voting yes. This has clear indications of what drives a particular party to vote yes on a given bill.
With less than 6% of bills introduced in congress since 1993 being brought to a vote, applied random forest, gradient boosted, neural network, and logistic regression models to predict this rare event. Oversampling (SMOTE) and under-sampling techniques were used to balance the classes within the training data. Recall, precision, and area under the precision recall curve were used as the priority metrics to measure the performance in classifying bills that will be voted on.
pymongo, mongodb, sci-kit learn, scipy, numpy, nltk, AWS, BeautifulSoup