The Tripitaka Koreana in Han (TKH) Dataset and the Multiple Tripitaka in Han (MTH) Dataset for the research of Chinese character detection and recognition in historical documents is now released by Deep Leaning and Visual Computing Lab of South China University of Technology. The datasets can be downloaded through the following links:
Note: The TKH dataset and MTH dataset can only be used for non-commercial research purpose.
The datasets contain scanned Tripitaka images with ground truth labels, including ground truth character bounding boxes and ground truth characters in each box.
Tripitaka Koreana in the Han language has been playing an important role in connecting Buddhism to the public since its first release in AD 11. We downloaded the Tripitaka Koreana in Han images, which were originally released by the research institute of Tripitaka Koreana, from the internet. The first row of Figure 1 shows typical sample pages of Tripitaka Koreana images. Although these scanned images have noise such as spots, tears, ink fading, and transparent backside, they can be easily read without any preprocessing.

We used a vertical projection method to separate the images into text lines, which are then further over-segmented by a beam-search algorithm to obtain the initial rectangular bounding boxes of characters. Then, we adjusted these bounding boxes to ensure they bound the characters accurately. During the adjustment, we also annotated the ground truth character in each of the boxes. Examples of the ground truth bounding boxes are shown in Figure 3.

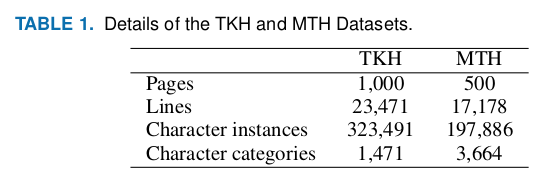
Our TKH Dataset contains 1,000 images, comprising approximately 320,000 character instances and 23,000 lines. The details of the dataset are given in Table 1. As the layout of the images in the TKH Dataset are relatively regular and characters in them are mostly uniform, it can be a suitable baseline dataset for research on character detection and recognition in historical documents.
For more complicated situations, we propose the Multiple Tripitaka in Han (MTH) Dataset, which contains scanned images from eight different Tripitaka versions in China. The data in this dataset induce more complicated situations, which makes the MTH Dataset more challenging than the TKH Dataset. For example, some images contain drawings, and some have more than one text area. The most challenging case is where characters in the same line appear in different sizes. In this case, smaller characters would be very blurred and close to each other. Some examples are shown in the second and third row of Figure 1. These challenges also make it infeasible to generate initial bounding boxes in the same manner as that used on the TKH Dataset. Instead, we used a detector trained with the TKH Dataset to generate these initial bounding boxes. Examples of ground truth bounding boxes of the MTH Dataset are shown in Figure 3.
The MTH Dataset contains approximately 500 images that are more complicated and more representative than those in the TKH Dataset. Thus we believe that the MTH Dataset has a unique value and can further support research on historical document images.
We compared our proposed method (RGD) with several state-of-the-art general object detection and scene text detection methods. The general object detection methods were two typical region-based methods, specifically, R-FCN and Faster R-CNN, and two typical region-free ones, specifically, SSD and YOLO. The compared scene text detection methods were TextBoxes, DMP-Nets and FEN. FEN and DMP-Nets use the Resnet-101 network for feature extraction, whereas all the other methods use the VGG-16 network.
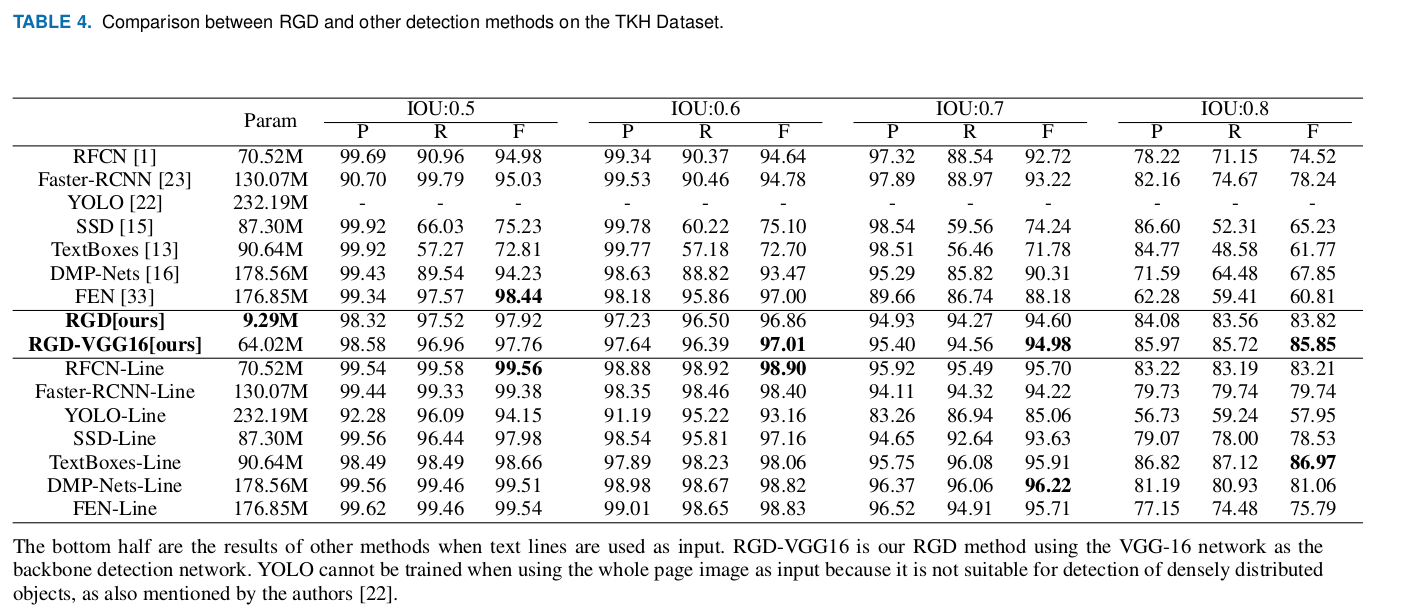
We tested these methods on the TKH Dataset using the entire image as input. The results are shown in the top half of Table 4. As the detection network in our proposed method (RGD) uses text lines as input, for fair comparison, we also tested the performance of other detection methods using text lines as input. The results are given in the bottom half of Table 4, in which previous methods with inputs of text lines are denoted by method-Line.
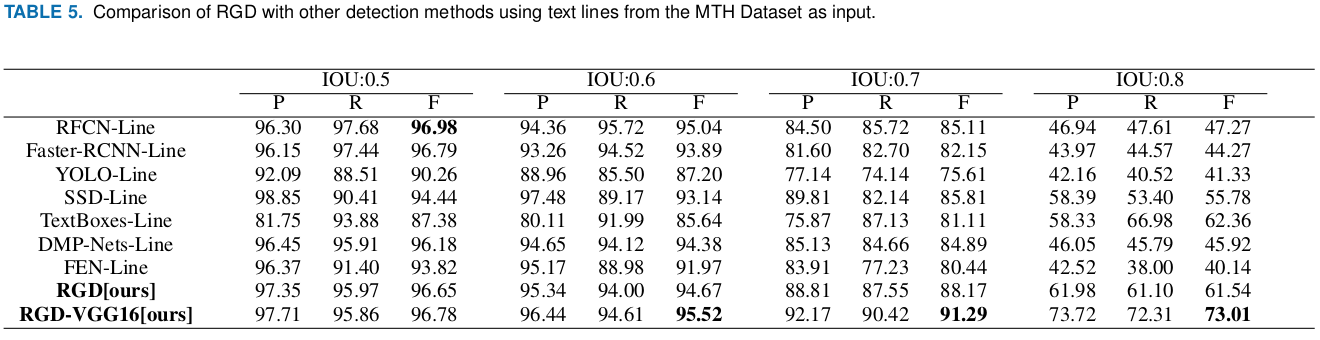
Data in the MTH Dataset comprise more diverse and complex situations than the TKH Dataset. This makes the MTH Dataset very suitable for testing the robustness and generalization of the models trained with each of the methods. Therefore, we conducted a set of experiments to compare the testing performance of the well-trained models in Table 4 using text lines from the MTH Dataset. The results are shown in Table 5.
Please consider to cite our paper when you use our datasets:
@article{yang2018SCUT,
title = {Dense and Tight Detection of Chinese Characters in Historical Documents: Datasets and a Recognition Guided Detector},
author = {Yang, Hailin and Jin, Lianwen and Huang, Weiguo and Yang, Zhaoyang and Lai, Songxuan and Sun, Jifeng},
jurnal = {IEEE Access},
year = {2018}
For any quetions about these datasets please contact the authors by sending email to eehlyang@mail.scut.edu.cn and eelwjin@scut.edu.cn.
The authors sincerely thank Beijing Longquan Monastery for organizing volunteers to help building the datasets. This research is supported in part by the National Key Research and Development Program of China (No.0 2016YFB1001405), NSFC (Grant No.: 61472144, 61673182, 61771199), GD-NSF (no.2017A030312006), GDSTP (Grant No.: 2015B010101004, 2017A030312006) , GZSTP (No. 201607010227).