cart->order-box->order->requirement,job,task
- layer
- adapter
- port(in/out)
- application(use case, service)
- domain(entity)
- 후보 architecture
- DDD-Lite
- DDD-Lite@Spring
- domain 과 adapter 가 분리되어 있는 구조가 usecase 와 aggregate 개수가 많아길 경우 불편한듯
- ddd-start2
- 초반에는 좋아보였으나, 한 package 다양한 성격(service, model, exception 등) 의 file 이 섞이고,
- sub-domain 내에 다수 aggregate 를 넣는 방식이 너무 번거스러워 보임 (책 내용 자체는 좋음)
- CQRS idea 는 여전히 괜찮아 보임
- DDD-Lite
- 주요 선택 기준
- boilerplate code 가 많아질 수 있으나, work-management 의 역할이 많고 복잡하여 domain 별로 구성요소를 분리하는 방법이 적합하다고 판단함
- 특히 controller 에서 받은 data 와 domain 에서 처리하는 data 및 저장 data 가 서로 달라야 하는 경우들이 존재함
cart 에 resource 를 담을 때, 각 resource 별 field 검증은 필요한, domain 로직에서는 상세 resource 는 알 필요 없음상세 resource 를 기반으로 task 로직을 수행 후 영속성 영역에 저장시 general 한 entity 로 변경 해야함
- port.out 사용시 domain 과 별도로 table field 변경이 용이함
json field 를 조건으로 resource 검색 시 성능개선을 위해 field 로 빼더라도 domain 역역에 영향을 주지 않음
- 참고도서
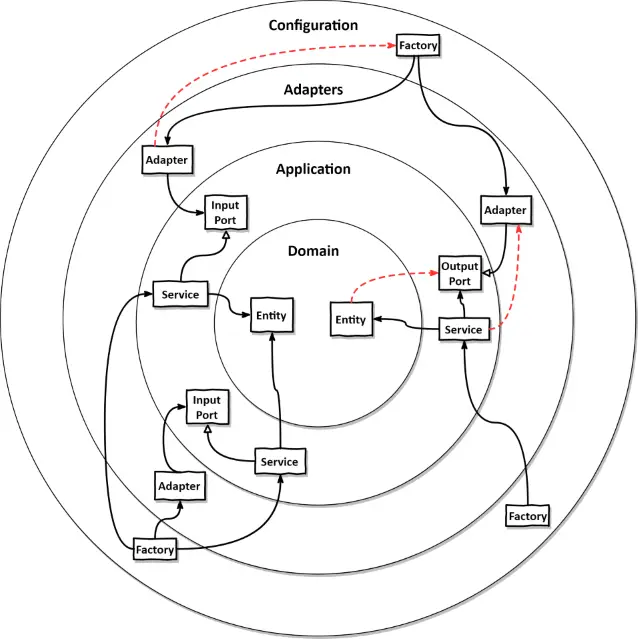
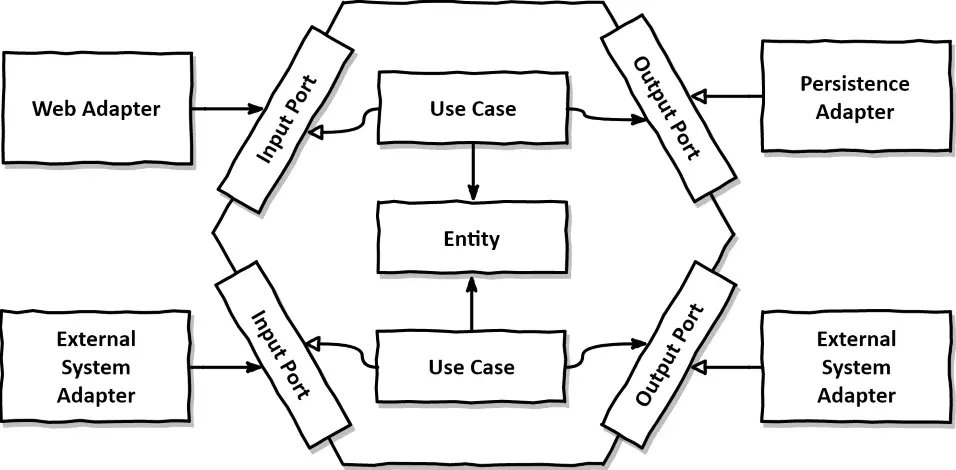
- 의존관계
[adapter.in]->[application.port.in]ᐊ-[application.service]→[application.port.out]ᐊ-[adapter.out]→[adapter.out]- xxxController → (xxxUsecase / xxxQuery) ᐊ- xxxService → xxxPort ᐊ- xxxAdapter → xxxRepository
- domain model 은 service 에서 제공
- port.in 은 필요해지기 전까지 생략
- port.out 은 최대한 한가지 기능만 하는 interface 로 구분
- usecase 가 단순 CRUD 형태라면 port.out 에 JpaRepository 를 상속하는 interface 사용
- domain event
- event-handler 는 application 계층에서 처리함. 이 경우, 같은 service package 에서 의존관계가 형성됨
- 자연스럽게 event-handler 는 다음과 같은 구조의 의존관계가 형성됨
- xxxEventHandler -> xxxService -> xxxPort ᐊ- xxxAdapter :
[application.handler]->[application.service]-> ... - xxxEventHandler -> xxxRequestPort ᐊ- xxxRequestAdapter :
[application.handler]->[application.port.out]ᐊ- ...
- xxxEventHandler -> xxxService -> xxxPort ᐊ- xxxAdapter :
- event-handler 위치 및 이름
- 이벤트가 너무 많아지지 않는다면
- query 와 command 는 package 보다는 name 으로 구분
- ex) CreateOrderService, QueryOrderService
- model
- model 은 각 usecase 마다 별도의 class 사용 권장 (create 와 edit 가 동일한 model 을 사용하는 우연(?)을 중복으로 생각하지 않기)
- 한 package 에 파일 개수가 너무 많아질 경우 model package 를 추가하는 방식 보다는 기능 별로 구분 하고, 사용 모델은 기능과 함께 위치
- ex)
service,service.model-->service.create,service.edit,service.get
- ex)
- 도메인 서비스 (아직 예제 코드는 없음)
- 응용 서비스와 구분되고, 상태가 없도록 유지
- 도메인 로직을 구현하면서 하나의 aggregate 에 종속되지 않는 서비스
- 가능하면 도메인 서비스 대신 aggregate 에서 도메인 로직을 사용을 권장함
- 위치는 domain 패키지 내에 둠
- Aggregate
- aggregate 내에서는 다른 aggregate 의 객체를 직접 참조하면 안됨
- 복수의 aggregate 에 걸친 로직은 도메인 서비스 혹은 응용서비스에서 매핑하거나 조합해야 함
- 주로 양방향 매핑 사용
- request, domain model, persistence model 분리
- 단순한 경우 매핑 생략
- domain entity 로 jpa entity 사용
- request 가 완전히 동일할 경우 domain entity 그대로 사용
- 장바구니(cart)
- 주문(order)
- 주문자(orderer)
- 주문내역(order-item) (order-line 이 더 명확하나 order-item 이 더 익숙함)
- 주문함(order-box)
- 결재함(order-approval-box) (생략)
- 결재(approval)
- 결제(payment)
- 업무(job)
- 요청사항(work) : 결재된 주문 단위의 고객 요청 사항 뭉탱이
- requirement 1:N job(=order) 1:N task
- (work 로 할까 생각해 봤으나, 작업의 관점 보다는 요구사항에 대해 부각하는게 더 좋을듯 함)
- 업무(job) : order 단위의 업무
- 작업(task) : orderItem 단위의 작업
- 작업자(worker) <- member
- 작업처리(process) : 작업으로 이름 지을 경우 업무의 task 와 중복이 혼동이 심할듯
- 자원(asset) : resource 라고 하지 않은 이유는?
- 카테고리(category) : VM 이나, DB, CPU 등의 자원 그룹
- 리소스(resource) : 세부 자원 정보
- 고객(client): asset 을 요청하는 사람
- 작업자(member): asset 을 관리하고 업무를 처리하는 사람
- ID(id:identifier): auto-generate number
- 인덱스(idx:index): 순서를 보장하는 index
- 식별자(no:number): UUID 와 같이 string type 의 식별자
- asset
- category: 서비스 타입별 그룹
- resource: 가용 자원 항목 제공
- client
- cart
- order
- order-item
- (approval)
- member
- work (결제단위 승인, 반려)
- prior-job: 결재라인 등록, asset 준비
- job 과 task 생성
- job: job 과 task 의 상태 관리 (사전협의 승인, 반려 포함)
- task: task 실행 및 상태관리
- task-history