This is an oTree project built upon the Django web framwork.
The version of this code used in the original paper has been updated and rewritten in parts as required by the latest version of oTree. I have tested the application locally and with bots on a remote server but not in a lab setting (e.g. with subjects all playing at once). Recent versions of oTree promise better stability and performance, however I recommend a pilot to make sure things will run smoothly.
There are two parts to first time setup. First, setting the project up locally. Second, deploying the project to a server.
-
Python 3.5. oTree provides installation instructions in their documentation: http://otree.readthedocs.io/en/latest/install.html. I'll cover installing 'oTree' in the instructions below. However, my instructions are written for a Unix or Unix-Based OS (e.g. Ubuntu or Mac OS). If you are using Windows, the instructions might be slightly different in places. For trouble shooting or futher reference: http://otree.readthedocs.io/en/latest/install.html.
-
Git. A general idea of git and how to use it will be beneficial. https://help.github.com/articles/set-up-git/
Copy or clone (git clone git@github.com:seidelj/uchicago_pgg.git .) this repository into an empty directory on your machine. Note the trailing ' . ' in the git clone command indicates to clone into the current directory, don't forget it!
Create a virtual environment in the directory. First, make sure that you are in the project's root directory. If you enter ls you should see something very similiar to
(venv) wireless-s1-so-150-56-217:uchicago_pgg joseph$ ls
Procfile manage.py risk
README.md payment_info runtime.txt
__pycache__ public_goods settings.py
_static quizes survey
_templates requirements.txt training
data requirements_base.txt
db.sqlite3 requirements_heroku.txt
Next, enter the commands into your terminal.
$ pyvenv venv
$ source venv/bin/activate
If you are not familiar with virtual environments, the basic idea is to avoid this application's dependencies interfering with any other Python applications on your machine. Similarly, it will keep any future Python applications you install from interfering with this application. If the environment is 'active' you'll see '(venv)' on your terminal's command line.
Deactivate your virtual environment and set the required environment variables.
(venv)$ deactivate
In a text editor, open the file venv/bin/activate, which was created when you ran pyvenv venv. At the bottom of the file, add the following lines. You should choose your own value for OTREE_ADMIN_PASSWORD, which will the password used to sign into the administrative portion of the application.
export SECRET_KEY='your secret key'
# YOU MAY GENERATE A SECRET KEY USING: http://www.miniwebtool.com/django-secret-key-generator/
export OTREE_AUTH_LEVEL='STUDY'
export OTREE_ADMIN_PASSWORD='choose a password'
Reactivate your virtual environment.
$ source venv/bin/activate
Install neccessary Python packages to your virtual environment.
(venv)$ pip3 install -r requirements_base.txt
Check to see that everything worked.
(venv)$ otree resetdb
(venv)$ otree runserver
At this point, you can make any required changes and test them locally by using the the command otree runserver and observing them at http://127.0.0.1:8000/ in a web browser. The only required changes would be those relating to localization. If your subjects will be participating in the English language, you can skip ahead to server set up.
Each oTree application has the file structure
app_name
views.py
models.py
...
...
templates/app_name/
SomeName.html
The bulk of text is contained in the .html files. The files are standard html with some Django template variables. Django template variables and commands are indicated by {{ varname }} or {% some_command %}. There is no reason to change django template variables found in the html files.
In addition to the template files, there are instances where the views.py file contains variables that are used to display text to subjects. These will appear near the top of the file and begin with an underscore followed by a name in all caps, e.g. _RESULTS_WAIT_PAGE_BODY_TEXT. These files are
- public_goods/views.py
- quizes/views.py
- risk/views.py
- training/views.py
In addition to the notes above, the applications: quizes, survey, and risk require additional attention.
-
QUIZ_KEY.py is a list and dictionary declaration of the questions and answers. Maintain the integrity of the structures but you may change the text in quotations as needed.
-
Many of the questions are in the form of True False. If you need to change the language of True/False you can do so by modifying the
TRUE_FALSE_CHOICESvariables in the quizes/models.py. IMPORTANT: If you change the word to "True" to "Foo" then the correct answer in the QUIZ_KEY.py file must also be changed to "Foo".
- In models.py the variables below should be translated accordingly. Maintain the integrity of the list structure.
RACE_CHOICES
EDUCATION_CHOICES
HOUSEHOLD_CHOICES
PROFESSIONAL_CHOICES
- In models.py the Python class 'Player' defines several instance fields prefixed with a
q_. Change the verbose_name attribute as necessary.
- In the models.py, the Python class Player contains the following variables.
GAMBLES = (
('1', "Gamble 1"),
...,
('5', "Gamble 5"),
)
URNS = (
('0', "Black: ? | White: ?"),
('1', "Black:50% | White:50%"),
)
COLORS = (
('0', "Black"),
('1', "White"),
)
If you need to change these, only change the second values of the tuples within the tuple. For example
GAMBLES = (
('1', "Grumble 1"),
...
('5', "Grumble 5"),
)
COLORS = (
('0', "Negro"),
('1', "Blanco"),
)
In order to access this application through a website, you'll need to set this application up on a web server. I have written instructions for Heroku. The oTree documentation also has instructions for Heroku and a couple other options.
There are three steps I won't cover in detail
- Creating an account with Heroku
- Installing the Heroku CLI
- Create a new app through your Heroku dashboard.
Once a new Heroku app has been created, Heroku will provide instructions on how to deploy or you can follow my instructions below. The commands below should be done from the root directory of your project, same as the commands preceding.
(venv)$ heroku login
(venv)$ git init
(venv)$ heroku git:remote -a your-app-name-10101
In the last command above, you should use your Heroku app's name. If you don't specify one when creating a new heroku app heroku will generate one for you. e.g. ancient-spire-16403.
You can follow this sequence of commands any time you might change the code and want to upload it to the server.
(venv)$ git add .
(venv)$ git commit -am "first deploy"
(venv)$ git push heroku master
Although you have deployed your local files to the server, the heroku application will not be working. Your terminal will report Push rejected to your-app-name while trying to deploy to Heroku because configuration variables are missing.
(venv)$ heroku config:set OTREE_PRODUCTION=1
(venv)$ heroku config:set OTREE_AUTH_LEVEL=STUDY
(venv)$ heroku config:set SECRET_KEY="SECRET KEY FROM venv/bin/activate"
(venv)$ heroku config:set OTREE_ADMIN_PASSWORD="password_from_venv/bin/activate"
Now, you should be able to successfully deploy to Heroku.
(venv)$ git push heroku master
(venv)$ heroku addons:create heroku-redis:hobby-dev
A note on this: When I first ran this project I used a much older version of oTree that required a standard-0 tier of postgres. I will recommend the same. However, for those faced with budget constraints, oTree claims to have improved their performance and you may be able to function with a hobby-basic tier. I'd certainly pilot or test with some RAs before deciding to use the lesser tier.
(venv)$ heroku addons:create heroku-postgresql:standard-0
Creating heroku-postgresql:standard-0 on ⬢ secure-sands-26521... $50/month
Your add-on is being provisioned and will be available shortly
Created postgresql-curved-47346 as HEROKU_POSTGRESQL_CHARCOAL_URL
(venv)$ heroku pg:wait
(venv)$ heroku pg:promote HEROKU_POSTGRESQL_CHARCOAL
In the last command above, replace 'CHARCOAL' with whatever color Heroku assigns to your database.
Further reading, but not required: Heroku documentation for provisioning databases: doc.
This is a destructive process, don't do this more than once unless you know what you are doing. For example, if you have generated data in the lab using the application, this command will destroy that data from the remote database.
(venv)$ heroku run otree resetdb
(venv)$ heroku open
From your Heroku apps dashboard at heroku.com, you should uprade your dynos using the resources tab. In the original experiment, I used 1x Professional Dynos. Make sure you activate a dyno for the "worker". Use a lower-tiered dyno at your own risk as it could affect performance. Also, you can easily turn 'dynos' on and off through the Heroku dashboard when the application is not in use and you'll only be charged for when they are in use.
At this point, you are ready to run the experiment in the lab!
- On a computer that will not be used by a subject log in at create a session.
(Admin Login username is set in settings.py default is admin. Password is set as an envronment variable
OTREE_ADMIN_PASSWORD.)
2. Select "+Create new session"
3. Select session config.
4. Enter 16 participants, then click "Create"
5. Distribute links to the subject's computers. You can use the "Session-wide link". Make sure you enter this link on computers 1 and a time. If the link is initialized simultaniously on two seperate computers you may end up assiging two players to the same participant session. OR you can use a unique link on each computer.
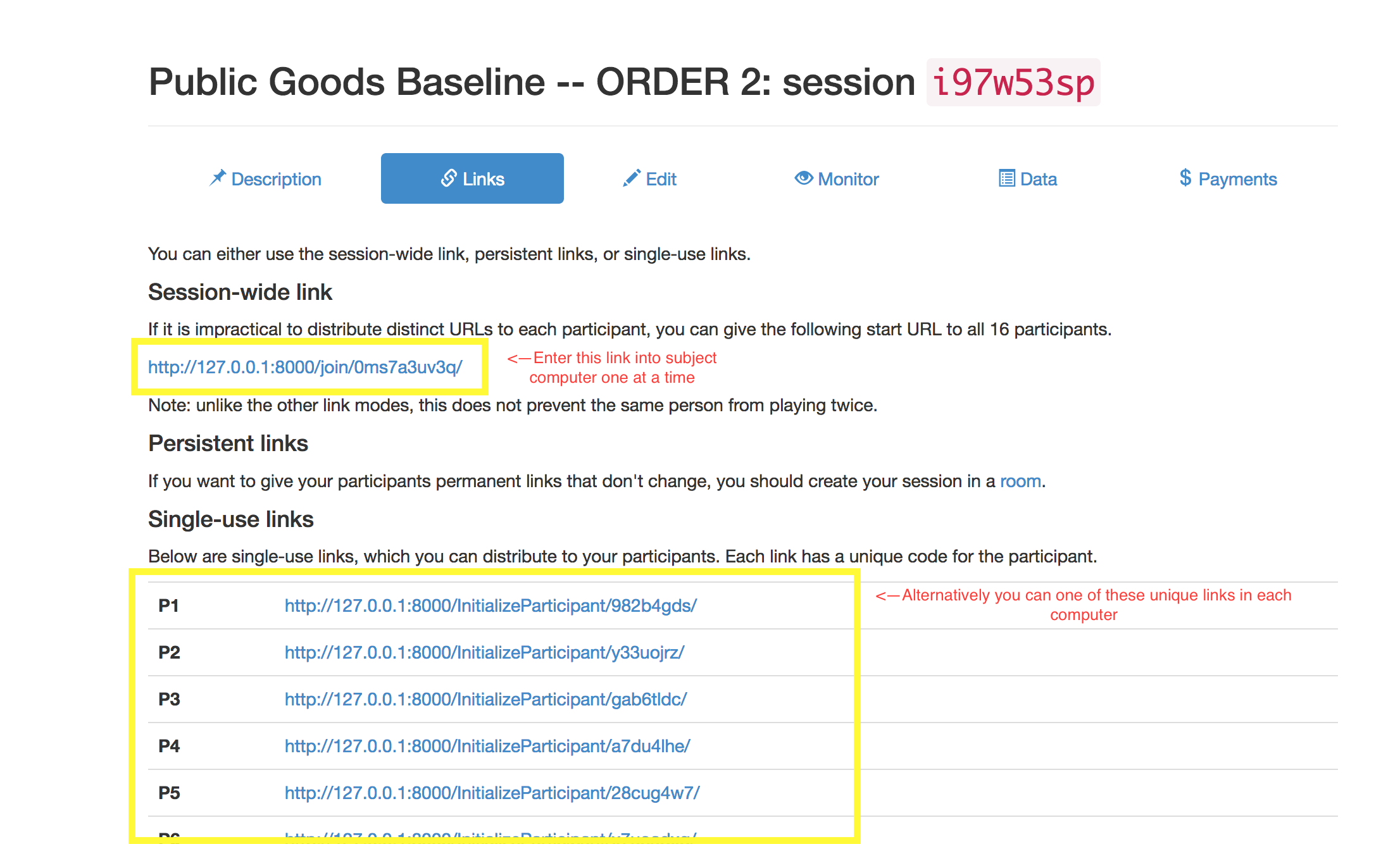
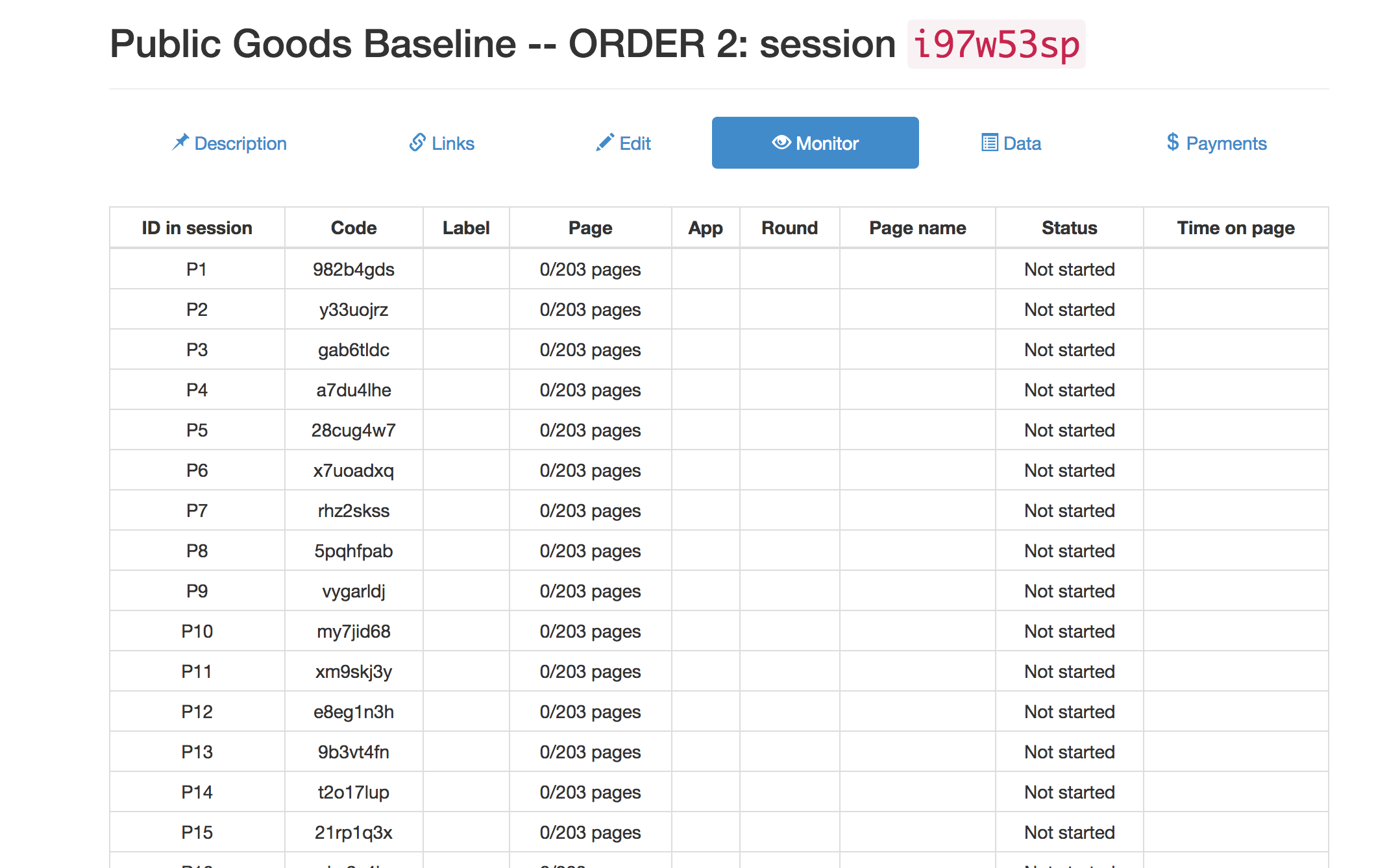
You can monitor the session.
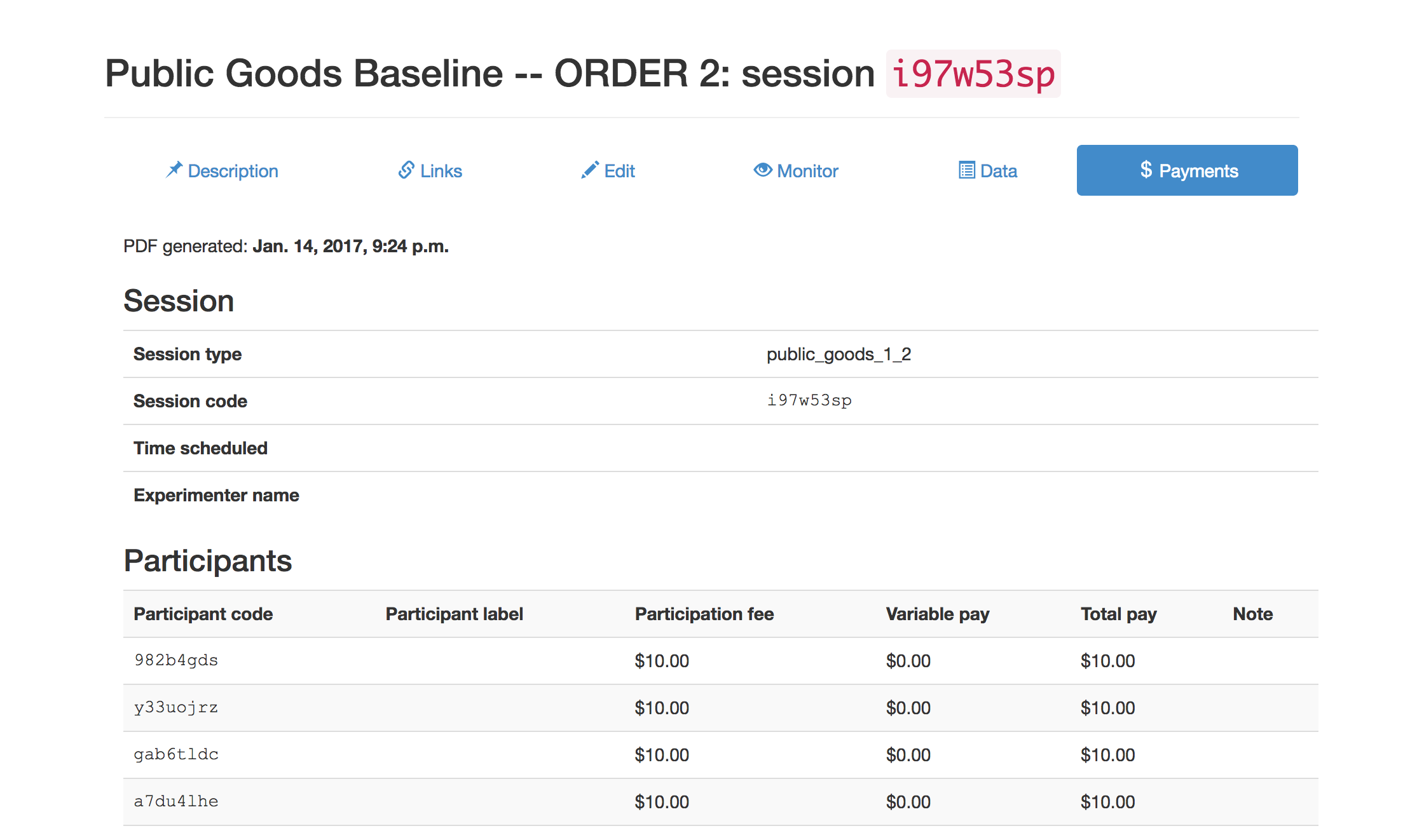
The payment tab will report subjects earnings for study. Payment values update as subject progress through the experiment, however the value will not be displayed on the payment info page without a page refresh. The reason I mention this is because sometimes subjects will mention they are being paid less than what got reported on their screen. Refreshing the page will rememedy discrepancy.
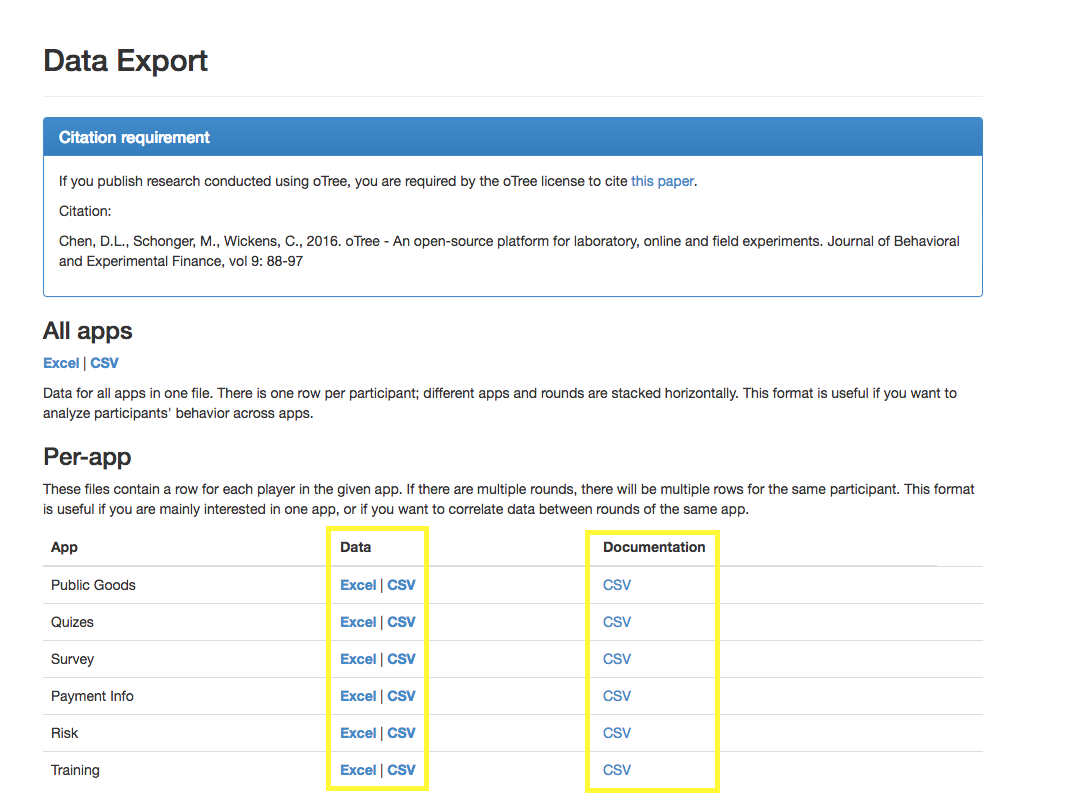
You can download CSV or Excel files containing the data from each session. There is also useful documentation associated with each app. The documentation found from the links seen in the example below will detail fields from the entirity of the SQL tables. Most people will find this version of the data and documentation excessive. See below.
- Click on "Data" in the page heading.
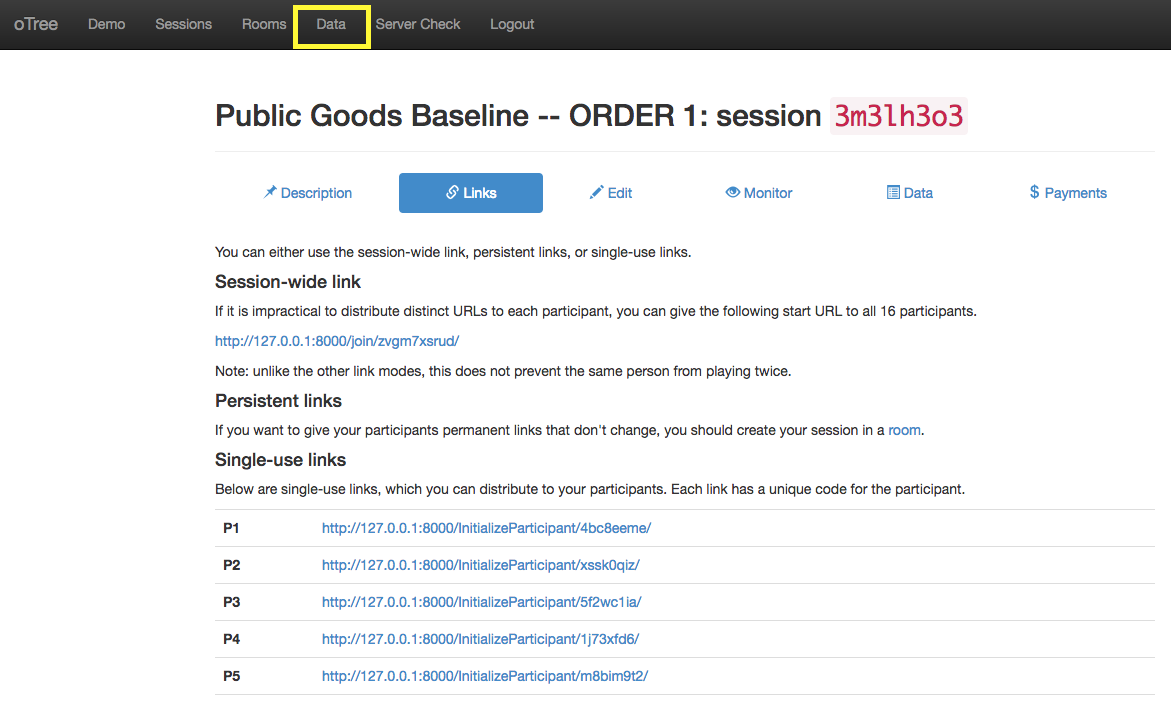
- Click to download app data and documentation.
Included in this repository is a Stata do file: data/merge/merge.do. It will combine the data exported from the website into a .dta and .csv file for analysis. It will also remove variables that aren't useful for academic purposes. Follow the instructions in the comments at the beginning of the .do file. The file is currently set up with a working example using data created by robots.